Authors:
D Alqattan、R Sun、H Liang、G Nicosia、V Snasel、R Ranjan、V Ojha
Paper:
https://arxiv.org/abs/2408.10752
Introduction
Federated Learning (FL) has emerged as a promising solution to the challenges posed by Centralized Machine Learning (CML), such as data storage, computation, and privacy concerns. FL enables collaborative training of a global model across numerous clients while preserving data decentralization. However, traditional FL, which employs a two-level node design, faces limitations in terms of latency, network efficiency, and server capacity. Hierarchical Federated Learning (HFL) addresses these challenges by employing multiple aggregator servers at edge and cloud levels, forming a hierarchical structure that enhances scalability and reduces latency.
Despite its advantages, HFL is susceptible to adversarial attacks that can compromise data integrity and undermine the global model’s performance. This study investigates the security of HFL, focusing on its resilience against inference-time and training-time adversarial attacks. Through extensive experiments, the research uncovers the dual nature of HFL’s resilience, highlighting its robustness against untargeted training-time attacks and vulnerabilities to targeted attacks, particularly backdoor attacks.
Related Work
Significant attention has been devoted to studying the impact of attacks on FL. Abyane et al. conducted an empirical investigation to understand the quality and challenges associated with state-of-the-art FL algorithms in the presence of attacks and faults. Shejwalkar et al. systematically categorized various threat models, types of data poisoning, and adversary characteristics in FL, assessing the effectiveness of these threat models against basic defense measures. Bhagoji et al. explored the emergence of model poisoning, a novel risk in FL, distinct from conventional data poisoning.
In contrast to conventional 2-level FL, adopting HFL introduces novel research concerns due to its inherently intricate multi-level design. Some studies have focused on examining convergence in HFL and proposed resilient aggregation methods for 4-level HFL models. However, scholarly works assessing the security aspects of HFL are relatively scarce. This research aims to fill this gap by conducting a systematic assessment of HFL security.
Research Methodology
Hierarchical Federated Learning (HFL) Model
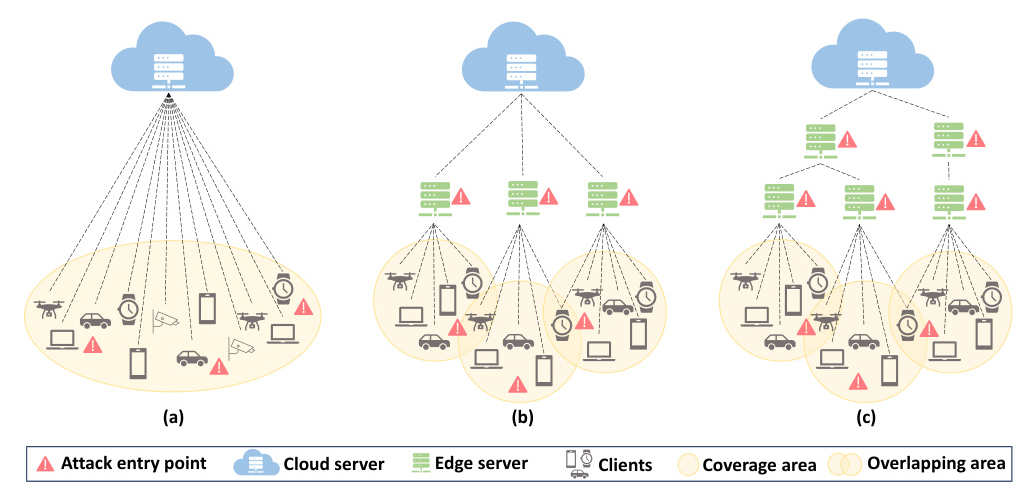
The HFL system is conceptualized as a multi-parent hierarchical tree, denoted as T = (V, E), consisting of |L| levels. Nodes in the system, categorized as clients (N) and servers (S), are represented in the set V, while the collection of undirected communication channels between nodes is represented in the set E. The cloud server node, s0, serves as the root of the tree at level 0, with client nodes, n, positioned at the leaves of the tree at level L −1. Intermediate edge servers, sℓ, act as intermediary nodes between cloud servers and clients at level ℓ(ℓ∈{1, . . . , L −2}).
The aggregation process in an HFL system involves several critical steps:
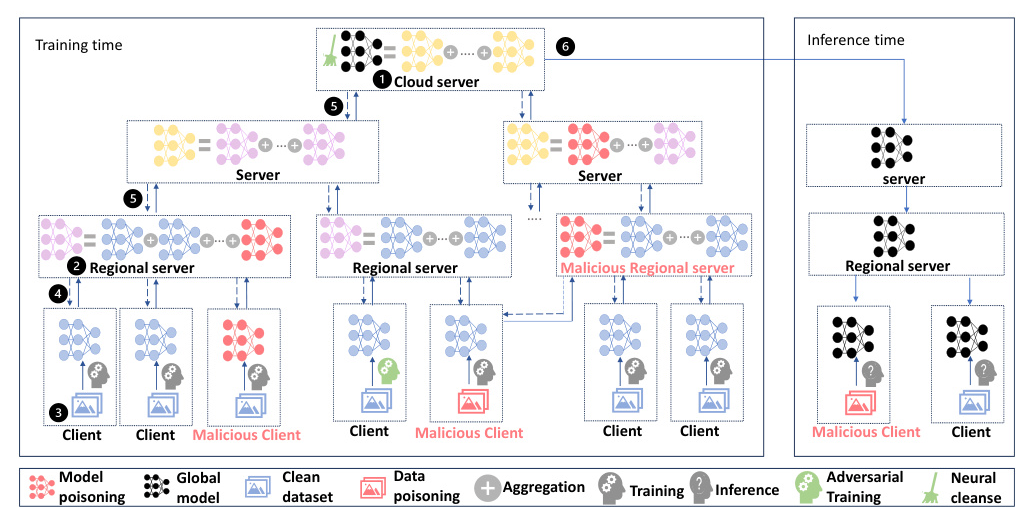
1. The cloud server s0 sends the initial model to clients n through edge servers sℓ.
2. Regional edge servers sL−2 select a set of client participants Ct at aggregation round t from their coverage areas A(sL−2) for model updates.
3. Clients Ct download the latest model from regional edge servers sL−2 and train their local models.
4. Updated parameters are sent back to regional edge servers sL−2 for aggregation.
5. Parent servers sℓ at level ℓ aggregate updated model parameters from child nodes sℓ+ 1 within their coverage areas A(sℓ) for Tℓ Number of aggregation rounds.
6. After T0 global aggregation rounds implemented by cloud server s0, a global model is constructed and transmitted to clients for deployment through edge servers sℓ.
Adversarial Attacks on HFL Model
Adversarial attacks on HFL models target data integrity during both training and inference times. These attacks can be client-side or server-side, with client-side attacks encompassing data poisoning and model poisoning tactics.
Inference-time Attacks (ITAs)
ITAs aim to perturb the input data at inference time to have them misclassified by the global model. Adversarial data is created through two types of ITAs: white-box attacks and black-box attacks. White-box attacks require full access to the target model, including its architecture, parameters, and gradients. Black-box attacks do not rely on or require access to the internal details of the target global model. This work applies white-box attacks, including Adversarial Patch (AP), Fast Gradient Method (FGM), Projected Gradient Descent (PGD), and Saliency Map Method (JSMA). Black-box attacks, including Square Attack (SA) and Spatial Transformations Attack (ST), are also applied.
Training-time Attacks (TTAs)
TTAs aim to inject adversarial data during training time to influence model parameters. These attacks can be client-side or server-side. Client-side attacks encompass data poisoning attack (DPA) and model poisoning attack (MPA) tactics. On the server side, the attacker can only implement MPA. DPA aims to manipulate the training data, while MPA directly alters model parameters. To implement the DPA attack, the targeted label flipping (TLF) method is applied, which aims to make the model misclassify specific backdoored inputs while maintaining performance on other inputs. Untargeted label flipping (ULF) attacks introduce random misclassifications. Regarding MPA, client-side sign flipping attacks (CSF) and server-side sign flipping attacks (SSF) are implemented, flipping the sign of the model parameters.
Adversarial Defense on HFL Model
Defenses against adversarial attacks can be broadly classified into two categories: data-driven and model-driven defenses. Data-driven defenses involve detecting adversarial attacks in the data or enhancing the quality of the data corrupted by the attack to improve model performance. Model-driven defenses involve building models that are robust to adversarial attacks. This work implements model-driven defense methods, including Neural Cleanse (NC) and Adversarial Training (AT).
NC cleans the neural network from neurons possibly affected by an attack, mitigating the impact of a TLF backdoor attack and producing a robust model. AT involves retraining the model with adversarial examples to make the model recognize and classify these examples correctly, even in the presence of perturbations. In the context of HFL, this process is referred to as adversarial hierarchical federated training.
Experimental Design
Experiments are conducted to assess the impact of adversarial attacks on HFL models (3-level HFL and 4-level HFL) and compare the performance of HFL models under various attacks and defense mechanisms alongside CML and traditional FL approaches (2-level FL).
Dataset
Three popular image classification datasets are used: MNIST, Fashion-MNIST, and CIFAR-10. Each dataset contains 60,000 images (50,000 training and 10,000 test images) categorized into 10 classes. To simulate non-IID real-world scenarios, the training set images are split according to the Dirichlet distribution.
HFL Model
A population of 100 smart devices representing client nodes distributed across a city implements image classification tasks. Each client trains a local classifier model to classify images. The cloud server performs the FedAvg aggregation rule for 20 aggregation rounds. The 3-level HFL model has 20 regional edge servers, each connected to 5 clients, performing the FedAvg aggregation rule for two aggregation rounds. The 4-level HFL model has 4 edge servers between the cloud server and regional edge servers, each communicating with five regional edge servers and performing the FedAvg aggregation rule for three aggregation rounds.
Client Local Training Model
Two different convolutional neural network (CNN) architectures are used for the client’s local classifier model. For MNIST and Fashion-MNIST, a CNN with two 3×3 convolution layers (32 and 64 channels) followed by 2×2 max-pooling, a fully connected layer with 512 units and ReLu activation, and a final softmax output layer with 10 outputs is deployed. For CIFAR-10, a CNN with two 3×3 convolution layers (32 channels) followed by 2×2 max pooling, another two 3×3 convolution layers (64 channels) followed by 2×2 max pooling, a fully connected layer with 512 units and ReLu activation, and a final softmax output layer with 10 outputs is used.
Malicious Node
If a client is compromised, it could act maliciously by implementing DPA or MPA. The performance of the model is evaluated with 1, 5, and 10 malicious clients. Models considering the overlapping area of two regional edge servers are indicated with the letter ‘O’ (3-level HFL-O and 4-level HFL-O). Regional edge servers can also be compromised and act maliciously by implementing MPA.
Evaluation Metrics
Misclassification Rate (MR) and Targeted Attack Success Rate (TASR) are used to assess attack efficiency and defense effectiveness. MR measures the rate of misclassification of clean or adversarial inputs, while TASR measures the success rate of targeted adversarial attacks.
Results and Analysis
Baseline Performance: HFL Model Under No Attacks
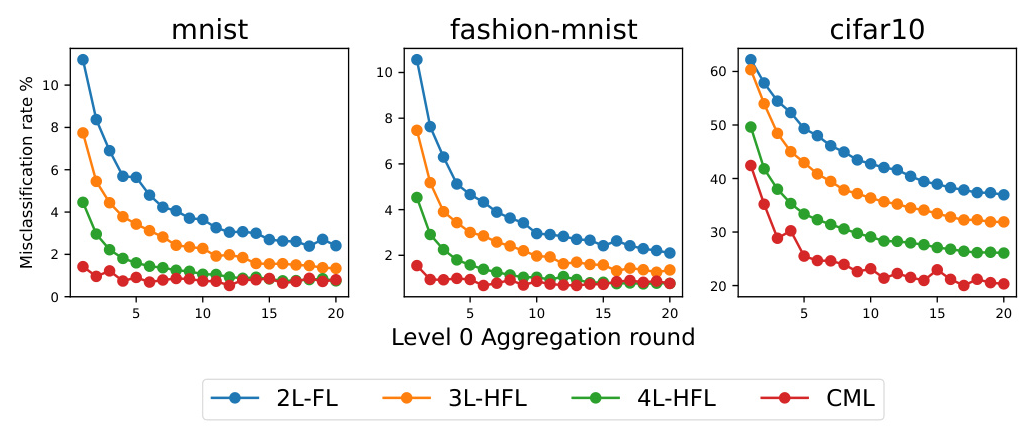
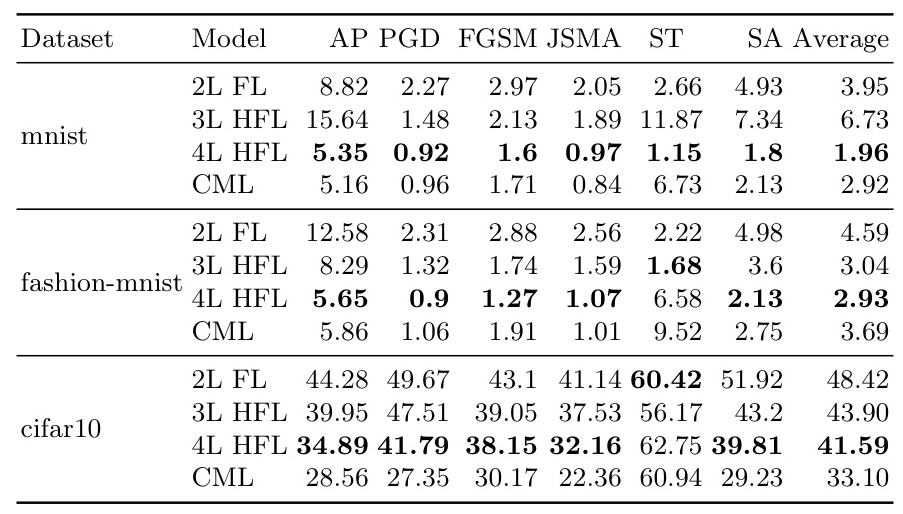
The performance of four models (CML, 2-level FL, 3-level HFL, and 4-level HFL) is compared under no attacks. The CML model maintains consistently high accuracy across 20 global aggregation rounds for each dataset. The 4-level HFL model demonstrates notably high performance, showcasing the potential advantages of hierarchical architecture in FL. The 3-level HFL model presents intermediary performance between 4-level HFL and 2-level HFL models, highlighting the impact of hierarchical architecture on FL. The 2-level FL model shows inferior performance.
Models Performance Under Inference-time Attacks and Defense
Impact of the Attacks
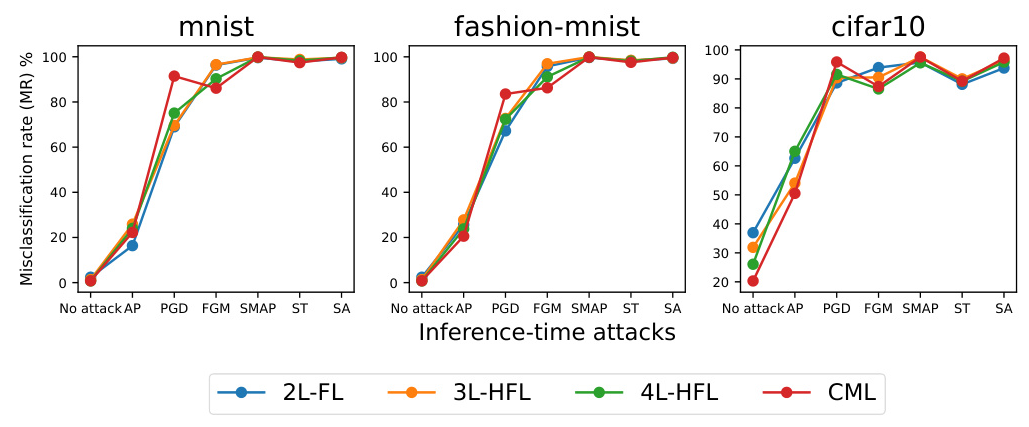
The effectiveness of the models under attack is assessed by calculating MR. The MR of all models trained on the same dataset exhibits a high degree of similarity, but the impact of each type of attack varies. Adversarial patch attacks demonstrate the lowest impact, while other attacks lead to high MR ranging between 80% to 100%.
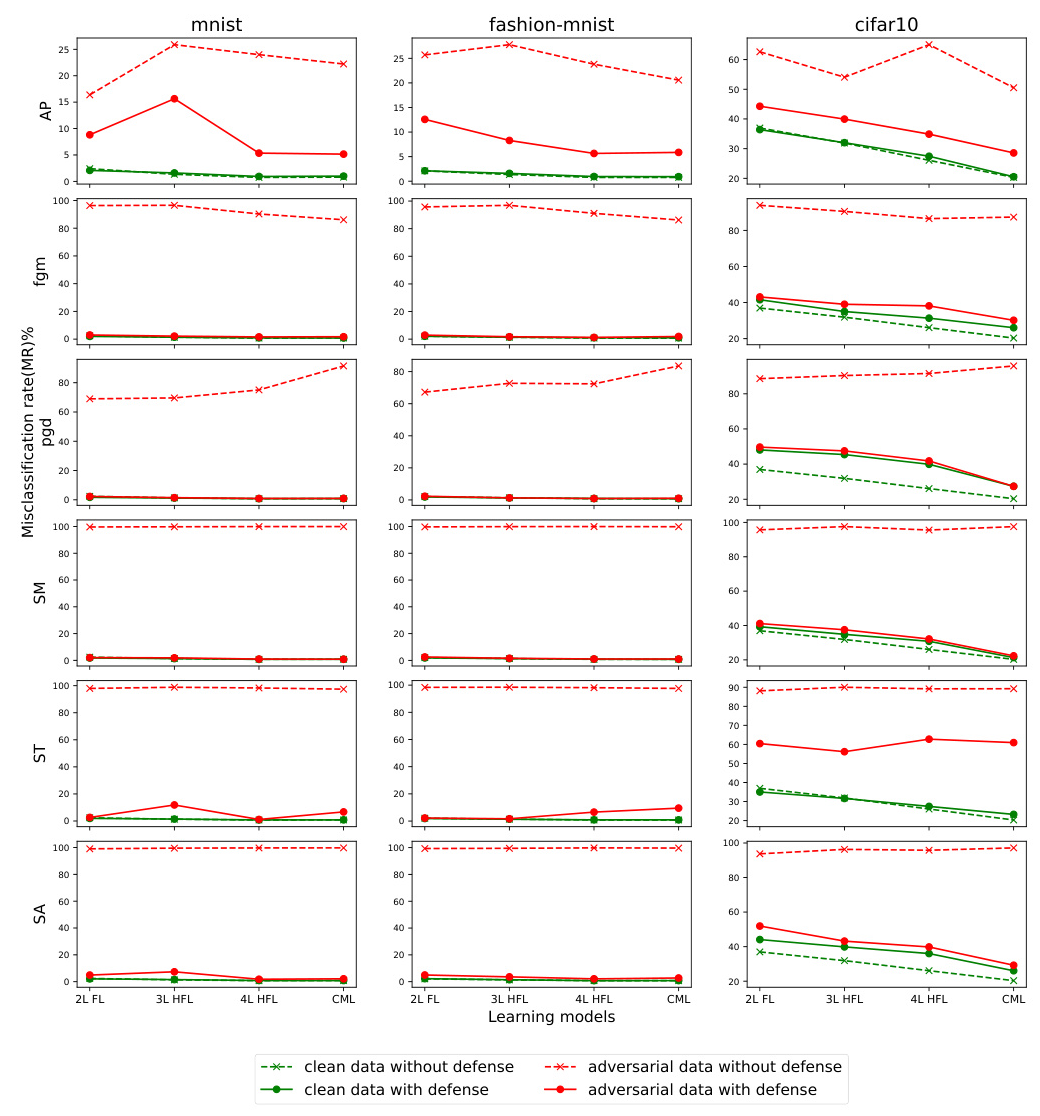
Adversarial Training (AT) Defense Against Inference-time Attack
Adversarially trained models using data generated by inference-time attacks show significantly reduced MR across all models. HFL models, especially the 4-level architecture, demonstrate higher resistance to attacks compared to CML models. However, increased dataset complexity (CIFAR-10) leads to higher MR for clean data, emphasizing the need for further research on complex, large-scale datasets.
Models Performance Under Training-time Attacks and Defense
Impact of Client-side Attacks (Data Poisoning)
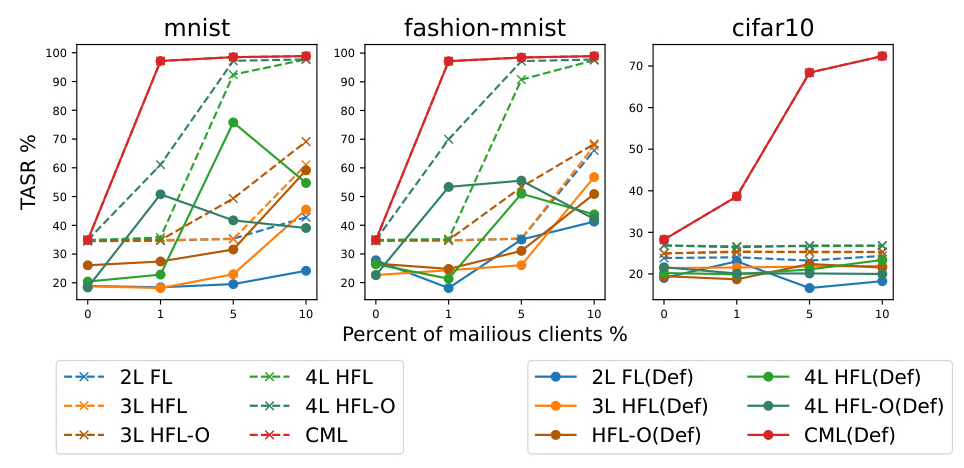
Both targeted and untargeted attacks on HFL are studied. Targeted label flipping (TLF) with backdoor attack aims to maintain model performance on clean data and make the model misclassify the targeted label as a desired label. The MR for clean test datasets remains relatively stable across different percentages of malicious clients, indicating minimal impact on model performance. However, TASR increases with the percentage of malicious clients, with the 4-level model showing the highest vulnerability to backdoor attacks.
The neural cleanse (NC) method offers robust defense against backdoor attacks, significantly reducing TASR and enhancing overall model security and robustness.
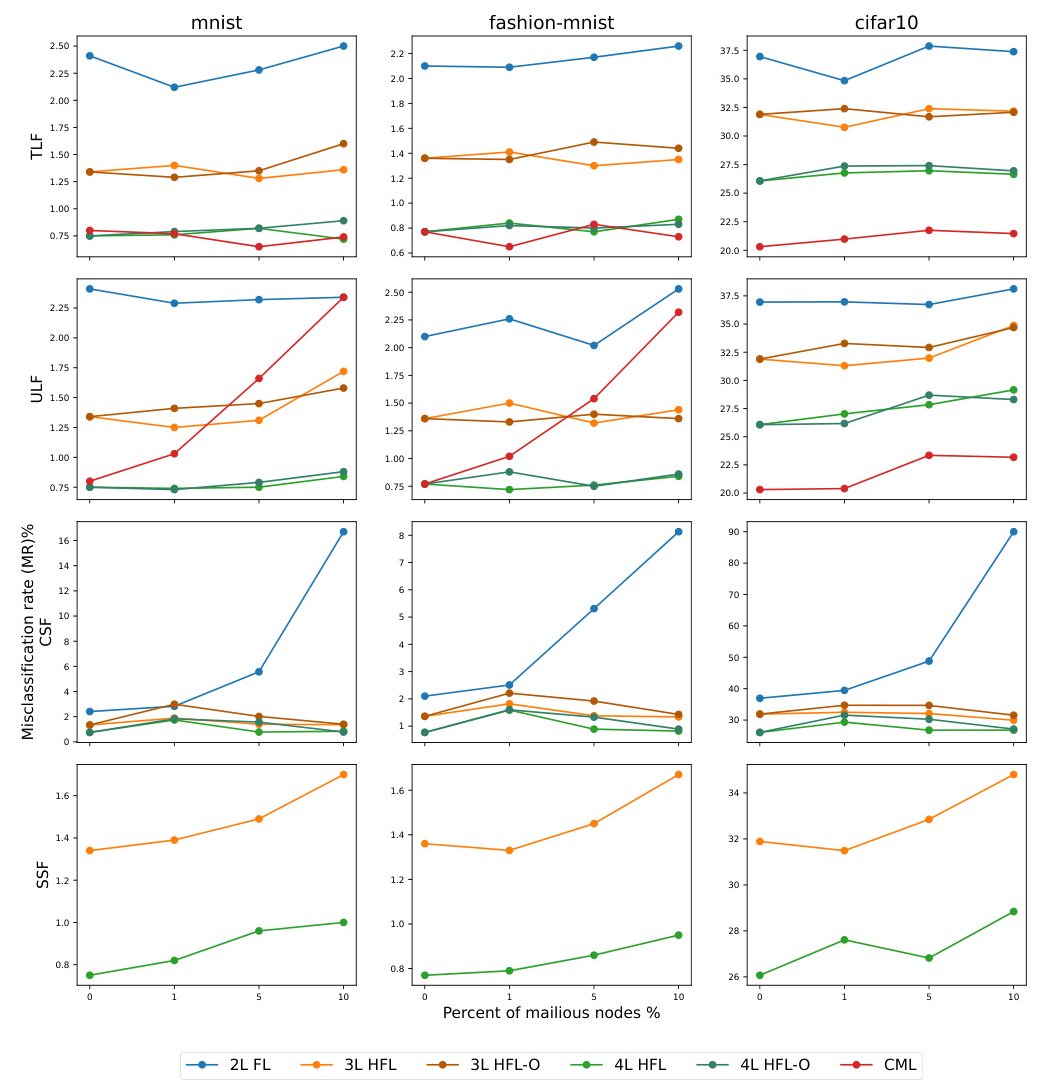
Untargeted random label flipping (ULF) attacks show that CML models suffer amplified effects as the number of compromised clients increases, while FL and HFL models are less impacted. FL’s resilience is attributed to its client selection mechanism, reducing the likelihood of selecting compromised clients.
Impact of Client-side Attacks (Model Poisoning)
Model poisoning (Client-side Sign flipping – CSF) shows minimal increases in MR for FL models, indicating resilience against such attacks. The 2-level FL model displays significant vulnerability when 10 clients are compromised, while the 3-level and 4-level HFL models show stronger performance due to their hierarchical aggregation process.
Impact of Server-side Attacks (Model Poisoning)
Server-side sign-flipping (SSF) attacks show that the 4-level HFL model consistently demonstrates lower MR across all datasets, indicating greater resilience to model poisoning. The impact increases with the number of compromised servers but remains negligible, highlighting the robustness of HFL models against server-side attacks.
Overall Conclusion
Hierarchical Federated Learning (HFL) demonstrates resilience to untargeted data poisoning due to its hierarchical structure. However, targeted attacks, such as backdoors, exploit architectural nuances, particularly when malicious clients are strategically positioned in overlapping coverage areas of regional edge servers. This highlights the need for further research in HFL security. Nonetheless, HFL shows promise in enhancing adversarial training to counter inference-time attacks. Future efforts should focus on developing tailored defense mechanisms to mitigate risks, bolstering the overall security and reliability of HFL systems for broader applications.