

Authors:
Sreyoshi Bhaduri、Satya Kapoor、Alex Gil、Anshul Mittal、Rutu Mulkar
Paper:
https://arxiv.org/abs/2408.11043
Introduction
Background and Problem Statement
Talent management research is pivotal in understanding employee sentiment, behavior, and overall organizational dynamics. This field often relies on qualitative data collection methods such as interviews and focus groups to gather rich, context-dependent insights. However, the manual analysis of qualitative data is labor-intensive and time-consuming, posing significant challenges for researchers. Traditional statistical techniques often fall short in capturing the nuanced complexities of qualitative data, leading to potential misinterpretations.
Large Language Models (LLMs) like BERT, GPT-3, and PaLM have shown promise in text summarization, classification, and information extraction. However, these models are primarily designed from a quantitative, data-driven paradigm, which can struggle to fully capture the nuanced, contextual nature of language critical for qualitative research. This study explores the potential of employing Retrieval Augmented Generation (RAG) based LLMs as novice qualitative research assistants to bridge the gap between qualitative richness and quantitative efficiency in talent management research.
Related Work
Quantitative and Qualitative Paradigms
Quantitative research, rooted in positivism, seeks to measure and quantify human behavior and societal phenomena using statistical methods. In contrast, qualitative research, aligned with interpretivist and constructivist traditions, focuses on understanding processes, experiences, and worldviews through non-numerical data collection methods like in-depth interviews and ethnographic fieldwork.
Mixed methods research combines the strengths of both paradigms to address complex research problems. Previous work has explored the use of Natural Language Processing (NLP) techniques for qualitative data analysis, but traditional methods like Latent Dirichlet Allocation (LDA) have limitations in capturing contextual nuances. Recent advancements in LLMs have shown potential in overcoming these limitations by leveraging deep neural networks to learn rich, contextual representations from large text datasets.
Research Methodology
Thematic Analysis Using LLMs
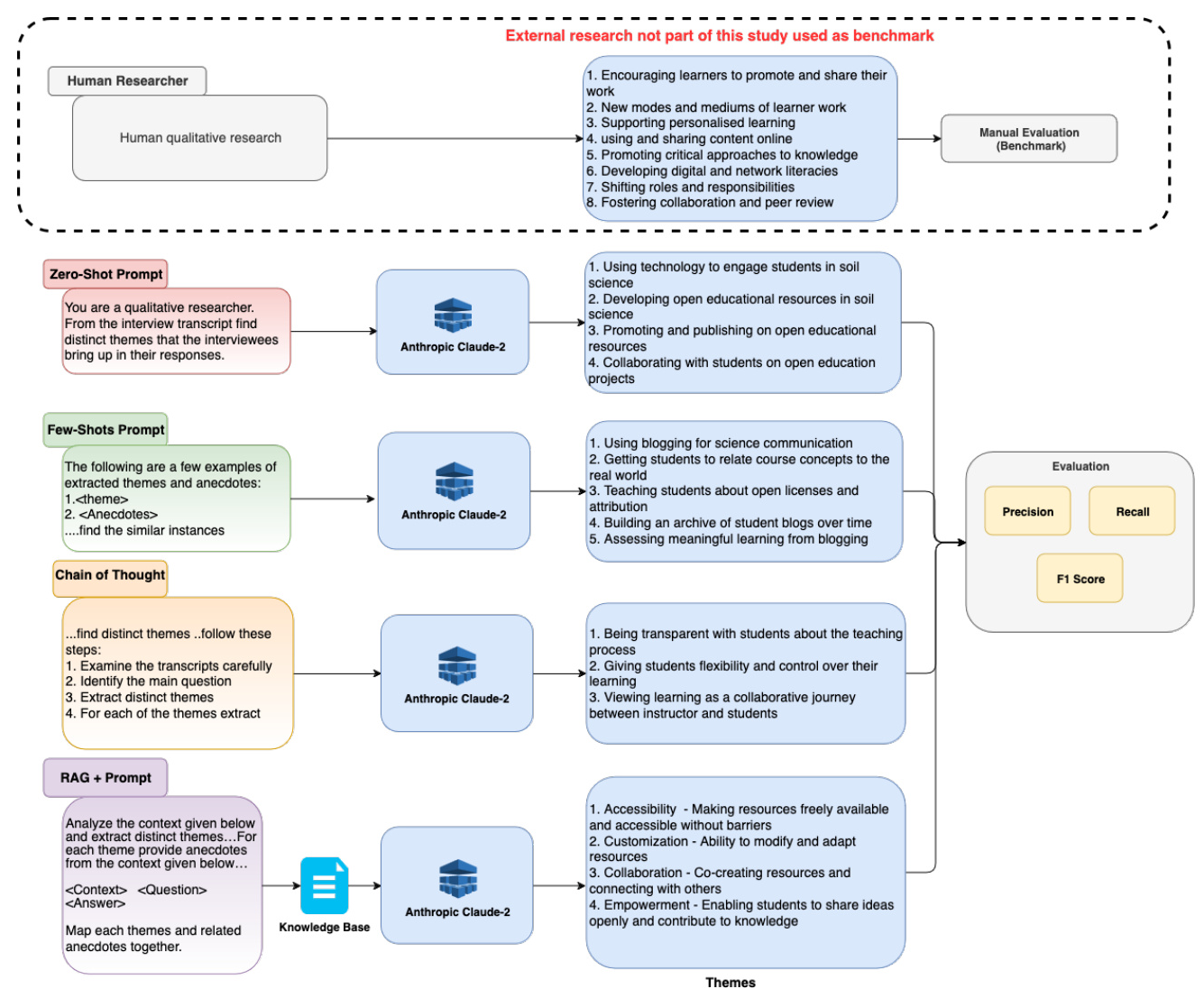
The study employs a novel approach by leveraging LLMs as novice research assistants in the thematic analysis of semi-structured interview data. The process involves using the Langchain framework to create dynamic prompt templates, such as few-shot prompts and chain-of-thought reasoning, to guide the LLM in performing topic modeling and generating insights from interview transcripts. Anthropic’s Claude2 model is used to execute these prompts and extract relevant themes.
Retrieval Augmented Generation (RAG)
The study experiments with four methods: zero-shot prompting, few-shot prompting, chain-of-thought reasoning, and RAG-based question answering. RAG combines the capabilities of an LLM with a retrieval system to source and integrate additional information into its responses, providing contextually richer and more accurate outputs.
Experimental Design
Dataset
An open-source dataset containing eight transcripts from hour-long interviews with educators was used to demonstrate the efficacy of the LLM-augmented approach. The dataset was originally collected to explore educators’ experiences with open educational practices. The manually extracted topics from this dataset serve as a gold standard for benchmarking the LLM-based approach.
Thematic Analysis Process
The thematic analysis process begins with formulating research questions and collecting interview transcripts. The LLM is then prompted to identify and summarize key topics, iteratively refining these into broader themes. The study compares the performance of various LLM prompting techniques, including zero-shot, few-shot, chain-of-thought, and RAG, across different embedding models.
Results and Analysis
Performance Metrics
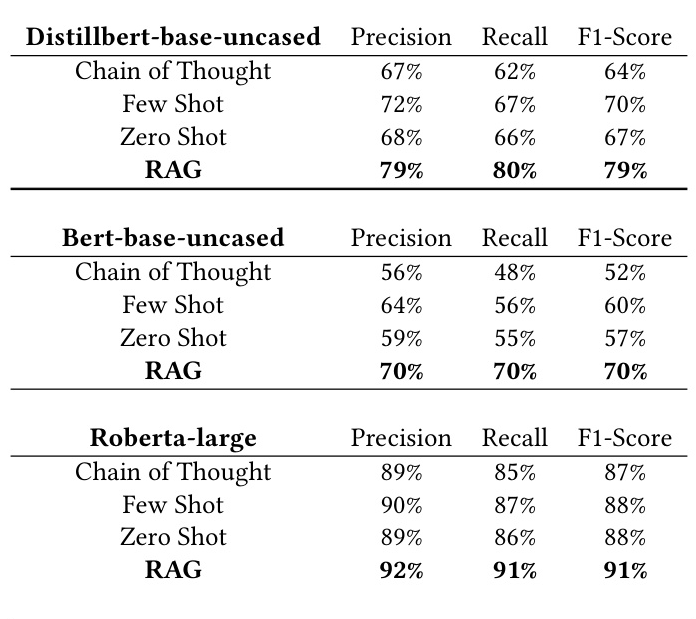
The study uses Precision, Recall, and F1-score to benchmark the topics generated by the LLM-augmented approach against manually generated topics. These metrics are adapted for text generation tasks using cosine similarity to measure the proportion of correctly identified positive cases.
Comparison of LLM Prompting Techniques
The results indicate that the RAG approach consistently outperforms other prompting techniques across all metrics, achieving the highest performance in terms of precision, recall, and F1-score.
Overall Conclusion
Key Learnings
- Approaching LLMs as Novice Research Assistants: Framing LLMs as novice collaborators helps in crafting better prompts and leveraging their capabilities effectively.
- Time and Resource Efficiency: LLMs significantly increase the efficiency of qualitative data analysis, reducing the time and effort required for manual coding.
- Enhanced Context and Interpretability: LLM-augmented approaches provide richer context and better interpretability compared to traditional NLP methods like LDA.
Recommendations
- Establishing Credibility: Incorporate mechanisms for member checks to ensure the accuracy of findings.
- Researcher Reflexivity: Acknowledge and address biases, and query the LLM for rationale behind extracted topics.
- Transparency: Document all decisions guiding the analysis process to enhance reliability and reproducibility.
Future Directions
Future research should establish guidelines and best practices for LLM-augmented qualitative analysis, ensuring rigor and trustworthiness. Ethical considerations, such as data privacy and algorithmic bias, must also be addressed to unlock the full potential of LLMs in talent management research.
By integrating LLMs as novice qualitative research assistants, talent management professionals can achieve a more comprehensive understanding of employee experiences and organizational dynamics, ultimately leading to more impactful insights and informed decision-making.