

Authors:
Xiao Wang、Yuehang Li、Fuling Wang、Shiao Wang、Chuanfu Li、Bo Jiang
Paper:
https://arxiv.org/abs/2408.09743
Introduction
X-ray image-based medical report generation is a critical application of Artificial Intelligence (AI) in healthcare. The goal is to leverage AI models to generate high-quality medical reports from X-ray images, thereby reducing the workload of doctors and minimizing patient waiting times. Despite significant advancements, current models still struggle to match the expertise of professional physicians due to challenges such as data privacy concerns, lack of quality and diversity in training datasets, and the rarity of certain diseases. This paper introduces a novel context-guided efficient X-ray medical report generation framework, R2GenCSR, which aims to address these challenges by enhancing feature representation and discriminative learning.
Related Work
X-ray Medical Report Generation
Existing models for X-ray medical report generation can be categorized into CNN-based, RNN-based, and Transformer-based frameworks. For instance, Li et al. combined CNNs and RNNs to generate reports from chest X-ray images, while Jing et al. used an LSTM framework to predict diseases and generate reports. Transformer models have also been employed to leverage visual and text data for improved performance.
Large Language Models
Large Language Models (LLMs) have shown great promise in natural language processing tasks. Notable examples include Google’s BERT, Meta’s LLaMA, and OpenAI’s GPT series. In the medical domain, models like R2Gen-GPT and MedicalGPT have been developed to generate medical reports by combining image and text data.
State Space Models
State Space Models (SSMs) like S4 and Mamba have been proposed to achieve linear complexity in sequence modeling. These models have been successfully applied to various research fields, including vision-related tasks in medical report generation.
Context Sample Retrieval
Retrieval-Augmented Generation (RAG) combines retrieval and generation to enhance performance in tasks requiring extensive knowledge and contextual information. Techniques like BG-Former and CricaVPR have been used to mine relationships between samples and generate robust image features. In medical report generation, RAG can serve as a clinical decision support tool by combining medical databases and research papers.
Research Methodology
Preliminary: Mamba
The Mamba network is based on the continuous State Space Model (SSM), which maps a one-dimensional function or sequence through a hidden state. The discrete version of SSM is achieved using the Zero-Order Hold (ZOH) method. Mamba enhances the SSM by making the model time-varying and speeding up training and inference using hardware-aware algorithms.
Overview
The proposed R2GenCSR framework consists of three main parts: the Mamba vision backbone, context retrieval module, and large language model (LLM) for report generation. The framework extracts visual tokens from the input X-ray image using the Mamba backbone, retrieves context samples from the training subset, and generates high-quality medical reports by feeding the vision tokens, context residual tokens, and prompt statements into the LLM.
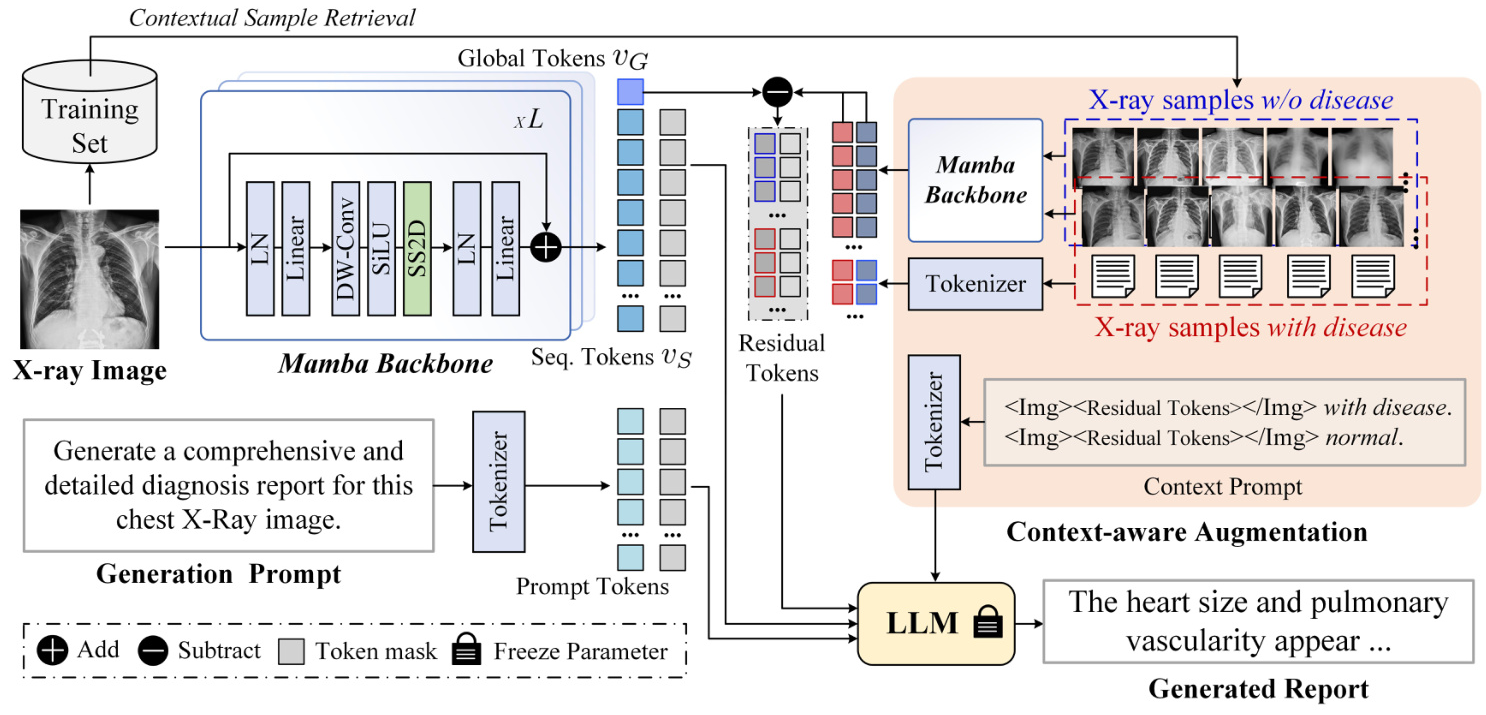
R2GenCSR Framework
Input Representation
The dataset contains N X-ray images, each represented by a feature map obtained using the VMamba backbone. Two distinct types of representations are generated: global features and sequential tokens.
Context Sample Retrieval
Context samples are retrieved based on keywords in the medical reports. Positive and negative samples are selected using approaches like CheXbert and keyword matching. The residual tokens, which measure the difference between the input and context samples, are calculated and used to guide the LLM in generating accurate medical reports.
LLM Head & Loss Function
The LLM generates detailed and accurate medical reports from the composite prompt, which includes visual and textual residuals. The cross-entropy loss function measures the difference between the generated reports and ground truth annotations, optimizing the R2GenCSR framework.
Experimental Design
Datasets and Evaluation Metrics
The performance of the model is evaluated on three datasets: IU-XRay, MIMIC-CXR, and CheXpert Plus. The evaluation metrics include CIDEr, BLEU, ROUGE-L, and METEOR, which measure the quality of the generated reports by comparing them to reference texts.
Implementation Details
The input X-ray image is resized to 224 × 224, and beam search is used for report generation. The training procedure is conducted on a server with NVIDIA A800 80GB GPUs using mixed precision. The model is trained for 20 and 25 epochs on the MIMIC-CXR and IU-Xray datasets, respectively.
Results and Analysis
Comparison on Public Benchmarks
Results on IU-Xray Dataset
The proposed R2GenCSR framework demonstrates competitive performance, achieving a BLEU-4 score of 0.206, surpassing existing methods. The framework also attains high precision in ROUGE-L, METEOR, and CIDEr scores.
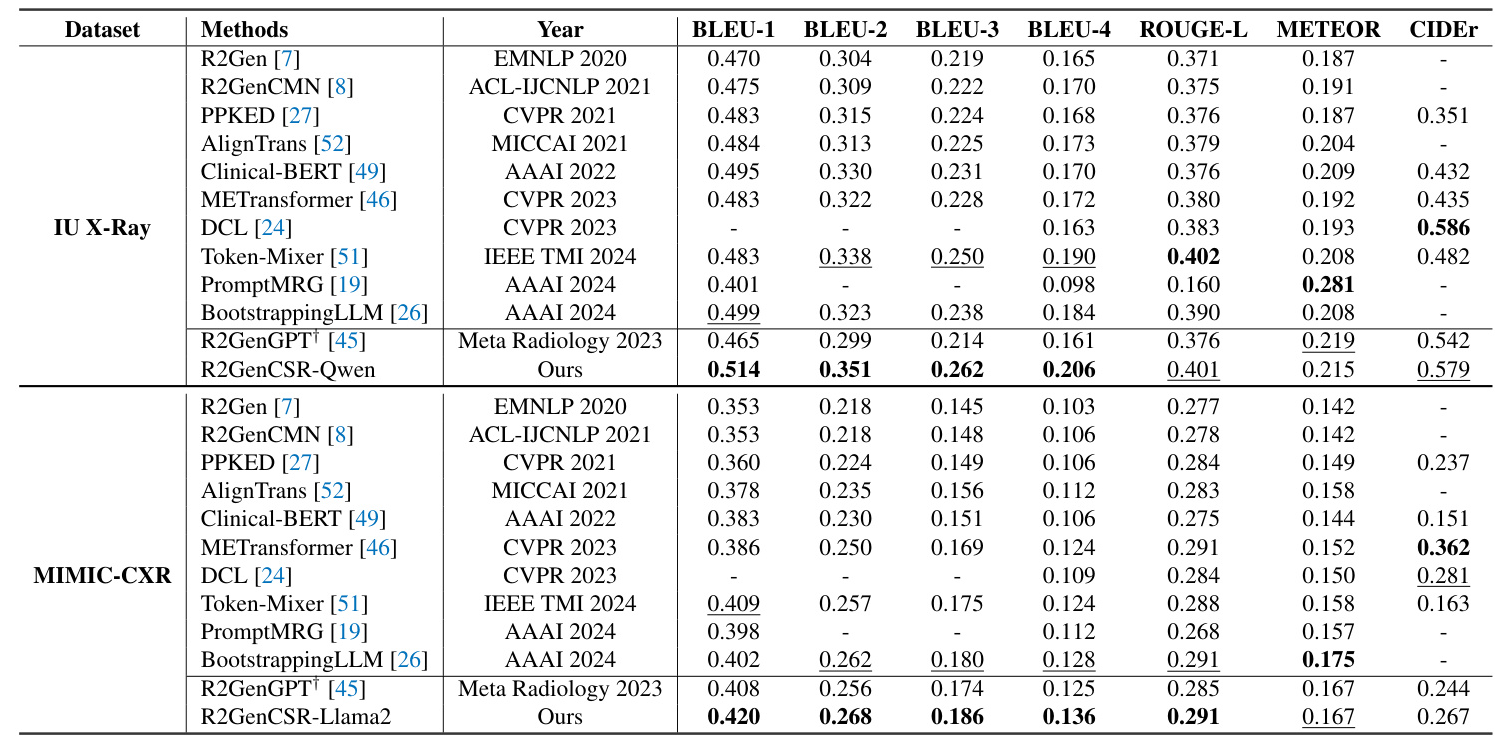
Results on MIMIC-CXR Dataset
The method achieves a BLEU-1 score of 0.420, a BLEU-4 score of 0.136, and a ROUGE-L score of 0.291, indicating its ability to generate precise and contextually relevant medical reports.
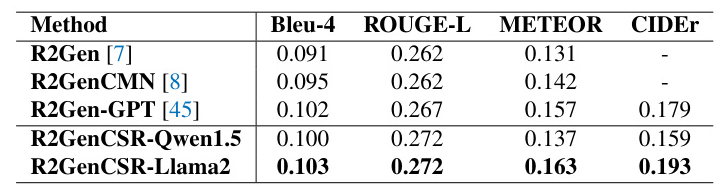
Results on CheXpert Plus Dataset
The R2GenCSR-Llama2 model outperforms the R2Gen-GPT model, improving on all four evaluation metrics, validating the effectiveness of the proposed modules.
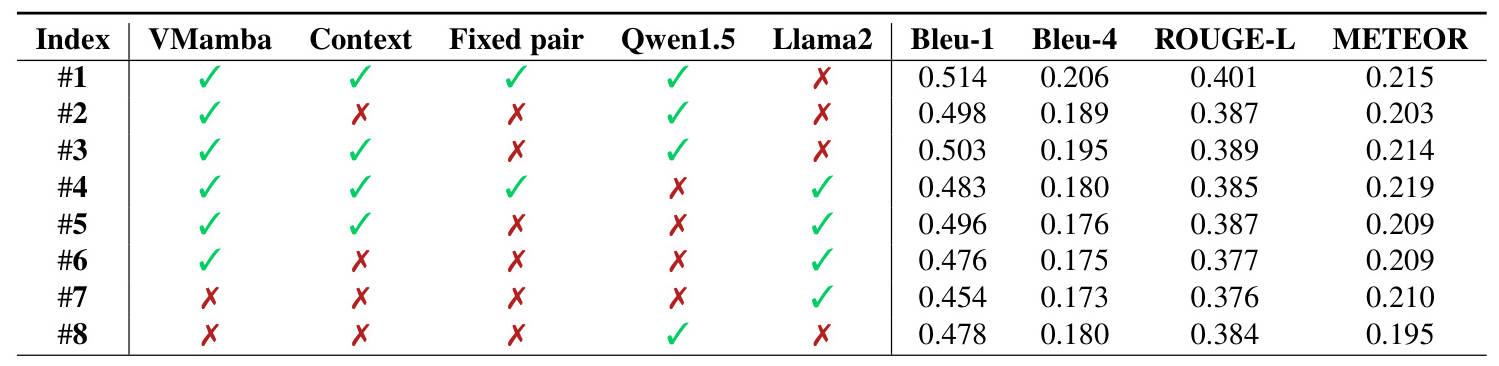
Component Analysis
A detailed component analysis on the IU-Xray dataset investigates the impact of key modules, including VMamba, context information, fixed pair strategy, and different language models. The results confirm that the VMamba module outperforms the Swin Transformer in extracting efficient visual features.
Ablation Study
Analysis of Different VMamba Backbones
The Base version of VMamba demonstrates the best overall performance, confirming that a larger VMamba backbone can capture more intricate visual features.
Analysis of Different Context Sample Retrieve Methods
The Keyword method retrieves samples based on keyword matching and is the most effective approach, surpassing other methods on all evaluated metrics.
Analysis of Different Stages for Feature Subtraction
Feature subtraction in the LLM projection space yields better results, demonstrating the importance of feature subtraction at different stages.
Analysis of Different Resolutions for Report Generation
The performance metrics improve as the resolution decreases, indicating that the VMamba model is adept at processing and extracting meaningful features from images of specific resolutions.
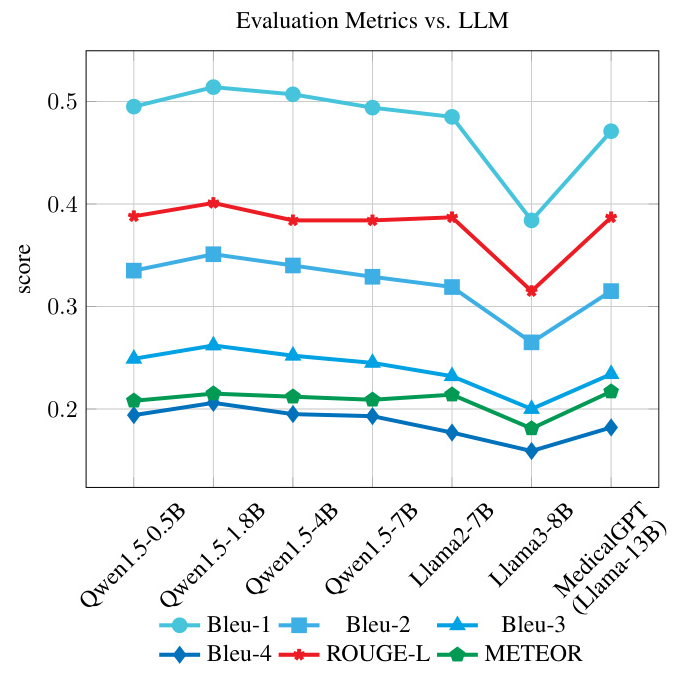
Analysis of Different LLMs for Report Generation
The Qwen1.5-1.8B model demonstrates notable improvement in metrics, while the specialized MedicalGPT model exhibits competitive performance, highlighting the benefits of domain-specific fine-tuning.
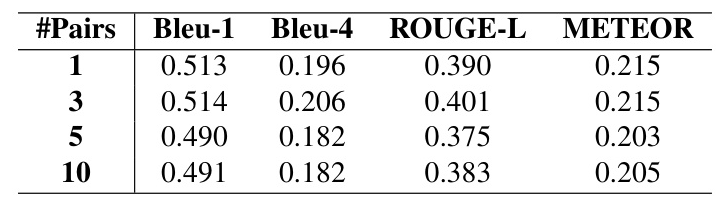
Analysis of Different Number of Context Samples
An optimal point is found at three context sample pairs, indicating that a moderate amount of context enhances the learning process.
Analysis of VMamba and Swin-Transformer for Report Generation
The VMamba model demonstrates superior efficiency compared to the Swin Transformer, despite having slightly more trainable parameters and memory consumption.
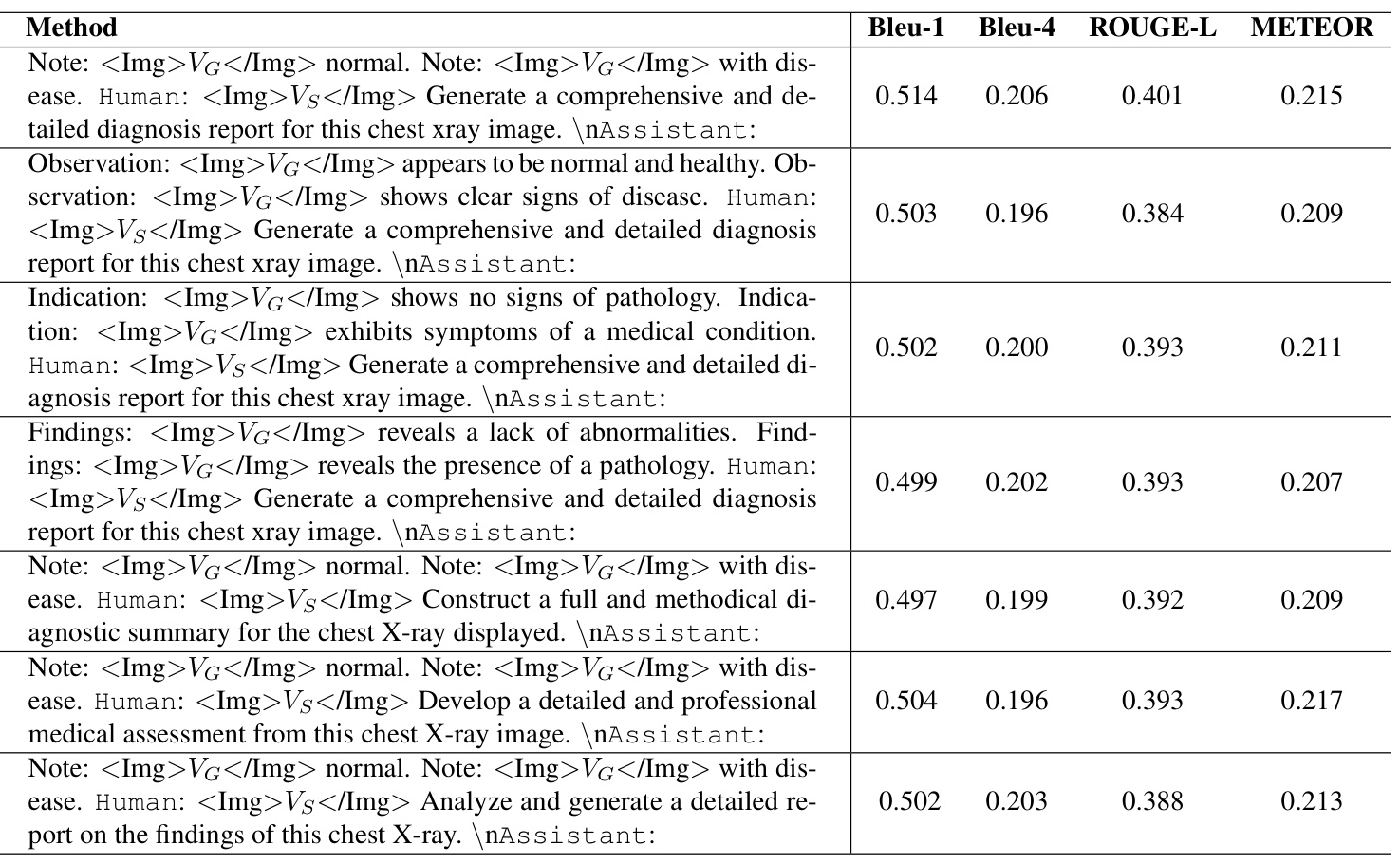
Analysis of Positive-Negative Context-Instructed Text and Instruction Prompt
Optimizing prompts can subtly affect the model’s output, with different instruction prompts resulting in slight variations in performance metrics.
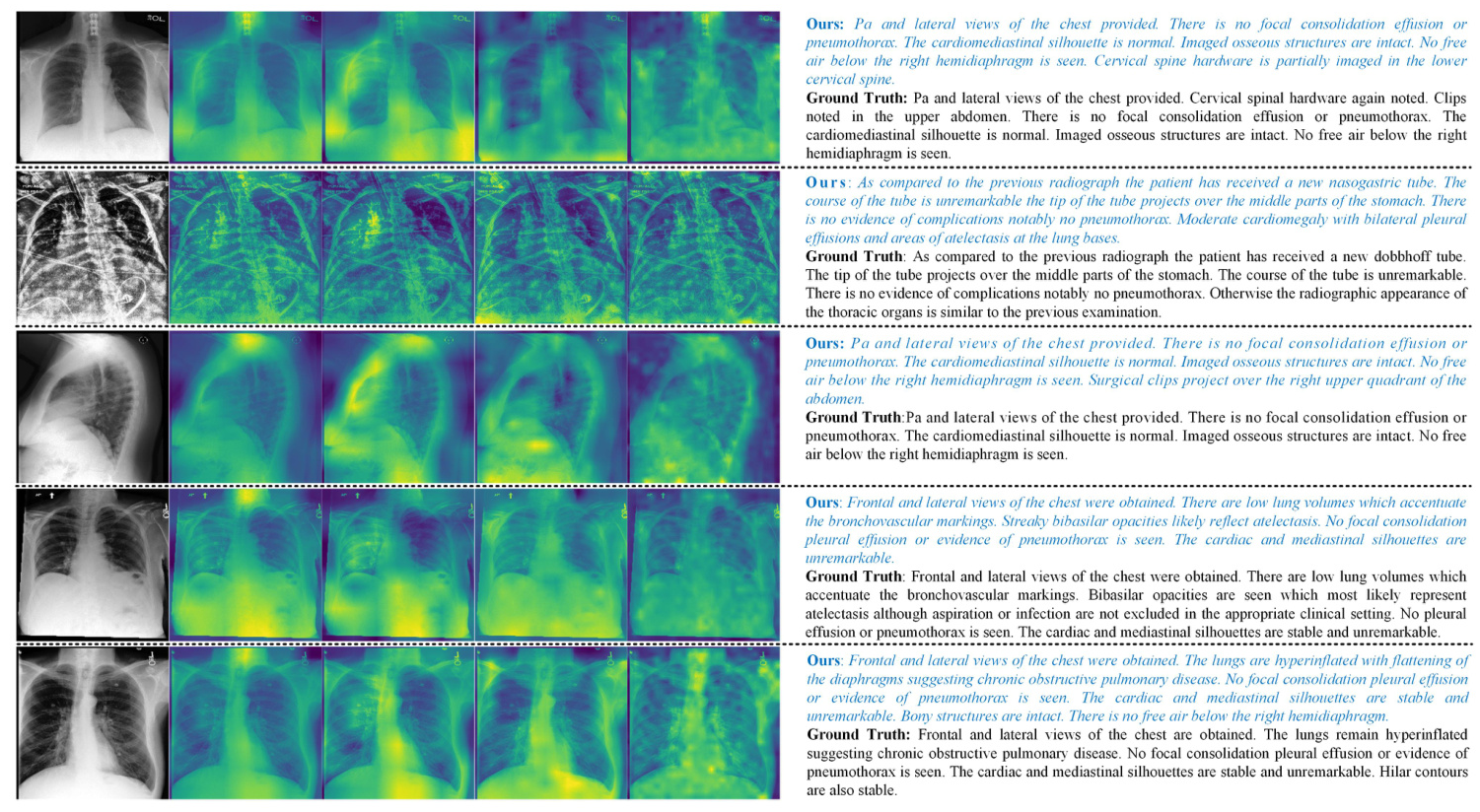
Visualization
Feature Maps
The VMamba vision backbone effectively extracts discriminative visual features from X-ray images, emphasizing regions of interest such as lesions and organs.
X-ray Medical Report
The generated reports closely align with the ground truth, with minor discrepancies highlighted in mismatching terms.
Overall Conclusion
The R2GenCSR framework introduces a novel context-guided efficient X-ray medical report generation approach, leveraging the Mamba model as a linear complexity vision backbone. The integration of vision tokens, context information, and prompt statements facilitates the generation of high-quality medical reports by the LLM. Extensive evaluations on the IU-Xray, MIMIC-CXR, and CheXpert Plus datasets demonstrate the efficacy and state-of-the-art performance of the proposed framework. This work contributes to the advancement of automated medical report generation and provides valuable insights for leveraging LLMs in other domains.
