

Authors:
Paper:
https://arxiv.org/abs/2408.09742
Introduction
Public narratives have a profound impact on society, influencing opinions and behaviors on various issues. Quantitative social scientists often analyze these narratives through the lens of “framing,” which involves highlighting certain aspects of reality to promote a particular interpretation. Traditional methods of framing analysis involve manual labeling of texts, which is labor-intensive and challenging to scale. This study introduces a novel method called “paired completion” that leverages large language models (LLMs) to detect and quantify issue framing in large text datasets efficiently and accurately.
Related Work
Framing Analysis
Framing analysis in computational literature lacks a clear definition, leading to varied approaches. Traditional methods often treat framing as a supervised machine-learning problem, requiring large amounts of labeled data. For instance, the Media Frames Corpus (MFC) and the Gun Violence Frame Corpus (GVFC) label dimensions of topics rather than conceptual frames. These methods are not generalizable beyond the topics under study and often achieve low accuracy.
Conceptual Framing Identification
Studies focusing on conceptual framing identification also face challenges due to the need for large labeled datasets. For example, Morstatter et al. (2018) and Mendelsohn et al. (2021) conducted multi-class classification studies but reported low accuracy scores. Guo, Ma, and Vosoughi (2022) proposed a method to quantify the similarity between news sources by fine-tuning LLMs, but this approach requires large amounts of text and is not feasible for less prominent sources.
Stance Detection
Stance detection, a related task, involves classifying the stance of a text towards a target into categories like “Favor,” “Against,” or “Neither.” Traditional NLP techniques with labeled data are commonly used. However, paired completion offers more nuanced insights by considering multiple perspectives rather than binary stances.
Research Methodology
Textual Alignment & Paired Completion
The study reconceptualizes framing as “textual alignment,” where two texts are considered aligned if they share a high likelihood of being expressed by the same entity. The paired completion method involves constructing prompt sequences from priming texts representing different framings and target texts. These sequences are passed to an LLM, which provides log-probabilities for each token. The difference in log-probabilities (Diff metric) indicates the degree of textual alignment.
The Diff Metric
The Diff metric is calculated as the difference between the conditional log-probabilities of a target text following different priming sequences. This approach is robust to the prior probabilities of both the conditioning sentences and the target text, making it a reliable measure of textual alignment.
Experimental Design
Synthetic Dataset Formation
Existing framing datasets are not suitable for this study, so synthetic data was generated. The synthetic dataset generation pipeline produces sentences reflecting different perspectives on a topic. This approach ensures balanced datasets with only the conceptual framing as the distinguishing feature.
Evaluation Approach
The study compares the paired completion method with four other approaches: TF-IDF vectors, word embedding vectors, LLM contextual embeddings, and LLM prompting. Each method was evaluated across multiple topics and configurations, resulting in 192 experiments.
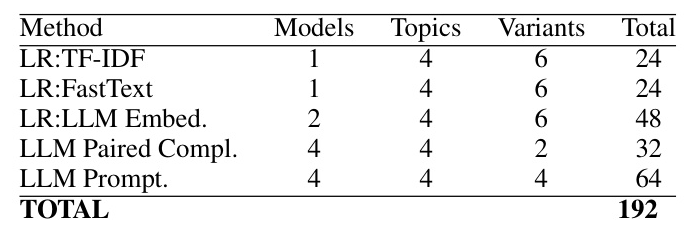
Results and Analysis
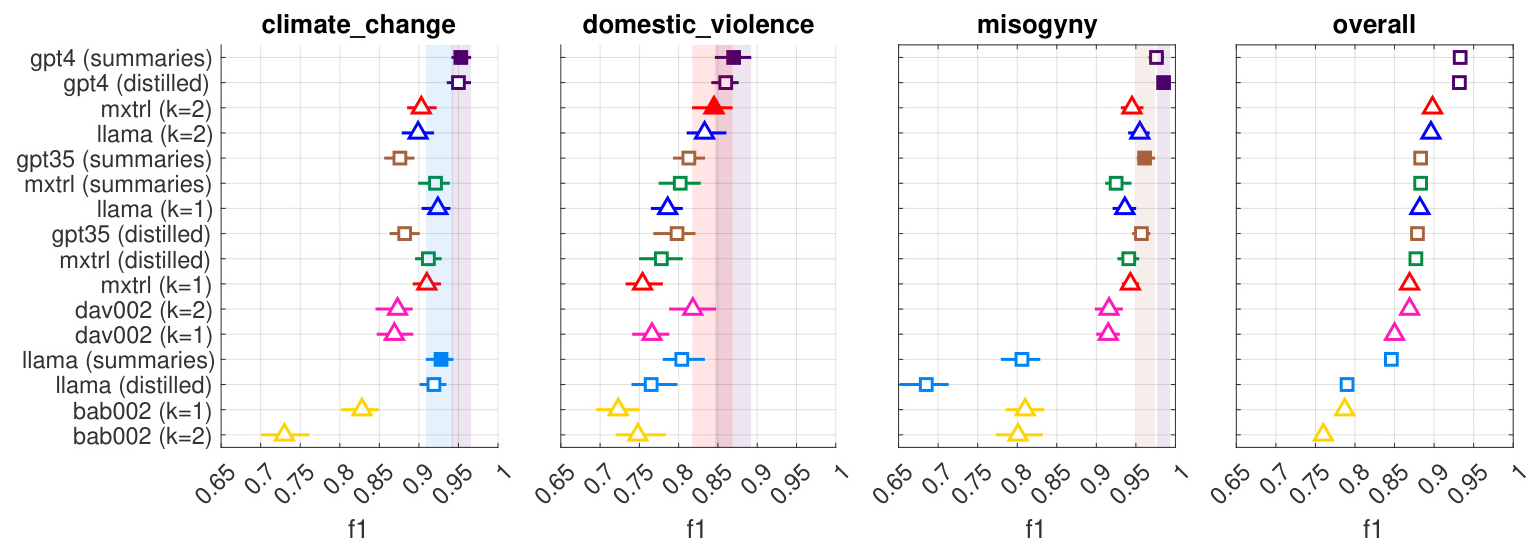
Comparative Analysis of Classification Methods
The experiments demonstrated strong performance for both prompt-based and paired completion methods. Paired completion methods generally performed better or similarly to prompt-based methods. Embedding-based methods were effective with sufficient data but performed poorly in few-shot learning contexts. Among LLM instruct models, GPT-4-Turbo outperformed others, while paired completion methods showed consistency across different models.
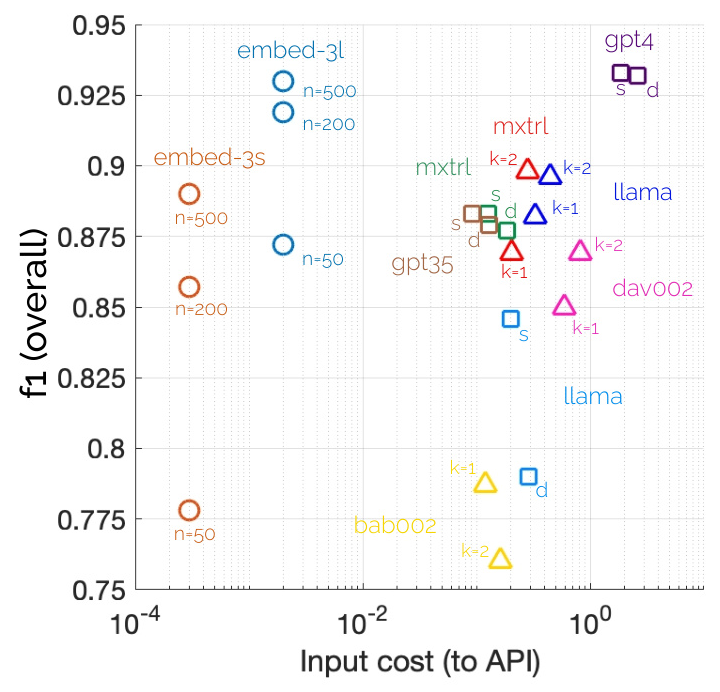
Cost vs. Performance
The cost-performance analysis revealed that paired completion with LLaMA-2-70b and Mixtral-8x7b was cost-effective for their performance level. GPT-4 had the best overall performance but was the most expensive. Embedding-based approaches were significantly cheaper but required more data.
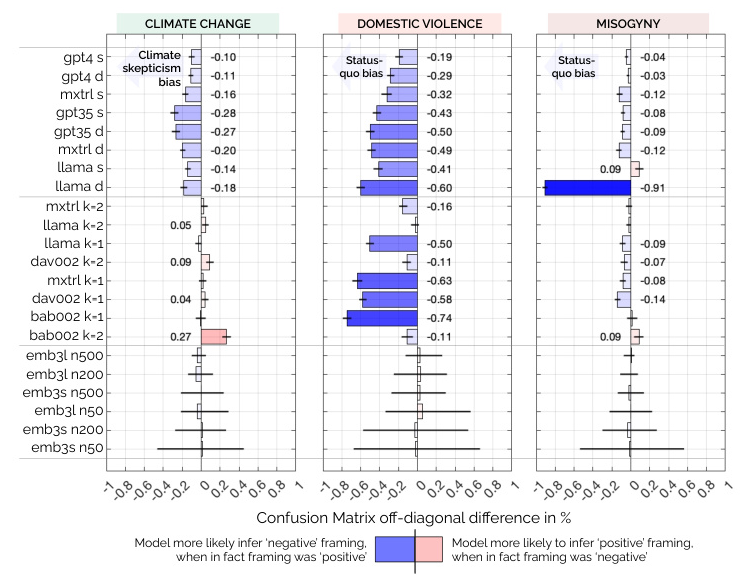
Model Bias
The study observed differences in model bias across datasets. Embedding-based approaches were most robust to bias, while LLM-based approaches showed bias in some scenarios. The k=2 paired completion configuration potentially reduced bias compared to k=1. Further studies are needed to examine the sources of these biases.
Overall Conclusion
The paired completion method offers a novel, efficient, and effective approach to issue framing analysis. It requires minimal examples, is low-bias, and is cost-effective compared to other methods. While synthetic data was used for evaluation, future work should involve human-labeled datasets to validate the findings. The study also highlights the need for further research on extending paired completion to multiple framings and understanding model biases.

In summary, paired completion represents a significant advancement in the scalable, accurate, and low-bias quantification of issue framing in large text corpora, providing valuable insights for social and political scientists, program evaluators, and policy analysts.