

Authors:
Padmanaba Srinivasan、William Knottenbelt
Paper:
https://arxiv.org/abs/2408.10713
Offline Model-Based Reinforcement Learning with Anti-Exploration: A Detailed Interpretive Blog
Introduction
Reinforcement Learning (RL) has made significant strides in developing policies for sequential decision-making tasks, aiming to maximize expected rewards. Traditional online RL methods alternate between interacting with the environment to collect new data and improving the policy using previously collected data. However, offline RL, where the policy cannot interact with the real environment and can only access a static dataset of trajectories, presents unique challenges. These datasets often have limited coverage and quality, making it difficult to generalize and extrapolate beyond the provided data.
Model-Based Reinforcement Learning (MBRL) offers a promising approach by learning a dynamics model from collected data and using it to generate synthetic trajectories, thus enabling faster learning. However, MBRL is fraught with challenges, especially in offline settings, due to approximation errors in the dynamics model and the potential for divergence in temporal difference updates.
In this context, the paper “Offline Model-Based Reinforcement Learning with Anti-Exploration” by Padmanaba Srinivasan and William Knottenbelt introduces Morse Model-based offline RL (MoMo). MoMo extends the anti-exploration paradigm found in offline model-free RL to the model-based space, aiming to address the challenges of offline MBRL by incorporating uncertainty estimation and policy constraints.
Related Work
Reinforcement Learning
Reinforcement Learning (RL) is typically framed as a Markov Decision Process (MDP), consisting of a state space, action space, reward function, transition dynamics, initial state distribution, and discount factor. The goal is to learn a policy that maximizes the expected discounted reward over time.
Model-Free Offline RL
Offline RL methods learn from a static dataset without interacting with the environment. These methods generally fall into two categories: critic regularization, which penalizes out-of-distribution (OOD) action-values, and policy constraint, which minimizes divergence between the learned policy and the behavior policy.
Anti-Exploration
Anti-exploration in model-free offline RL constrains the policy via explicit divergence minimization and augments policy evaluation with a value penalty to counteract overestimation. This approach has been effective in model-free settings but has not been widely explored in model-based RL.
Offline Model-Based RL
Offline MBRL injects samples from a learned dynamics model into the RL process, leveraging the diversity of simulated rollouts to augment the offline dataset. However, existing methods often rely on ensembles of dynamics models to estimate uncertainty and penalize OOD regions, which can be computationally expensive and challenging to generalize across tasks.
Research Methodology
Morse Neural Networks
The Morse neural network, developed by Dherin et al., is an uncertainty estimator that produces an unnormalized density in an embedding space. It combines a neural network function approximator with a Morse kernel, which measures the closeness of an embedding to a target. The Morse neural network is used to learn an implicit behavior policy and detect OOD states.
Anti-Exploration in MoMo
MoMo incorporates the Morse neural network into the anti-exploration framework, using it to estimate uncertainty and constrain the policy. The model-free version of MoMo uses the Morse network to detect and deal with OOD states, while the model-based version extends this to terminate synthetic rollouts that are excessively OOD.
Policy Constraint and Rollout Truncation
MoMo employs a policy constraint to ensure that the policy remains within the support of the dataset. Additionally, it uses a rollout truncation mechanism to stop synthetic rollouts when they deviate too far from the behavior policy, based on the uncertainty estimates from the Morse neural network.
Experimental Design
Datasets and Baselines
The experiments evaluate both model-free and model-based versions of MoMo on the D4RL Gym Locomotion and Adroit tasks. The performance of MoMo is compared with various baselines, including model-free methods like CQL, IQL, and TD3-BC, and model-based methods like MoREL, MOPO, and COMBO.
Hyperparameter Sensitivity
The experiments also include ablation studies to analyze the sensitivity of MoMo’s performance to hyperparameters such as the kernel scale (λ) and the truncation threshold (ϵtrunc). These studies help understand the robustness of MoMo across different settings.
Results and Analysis
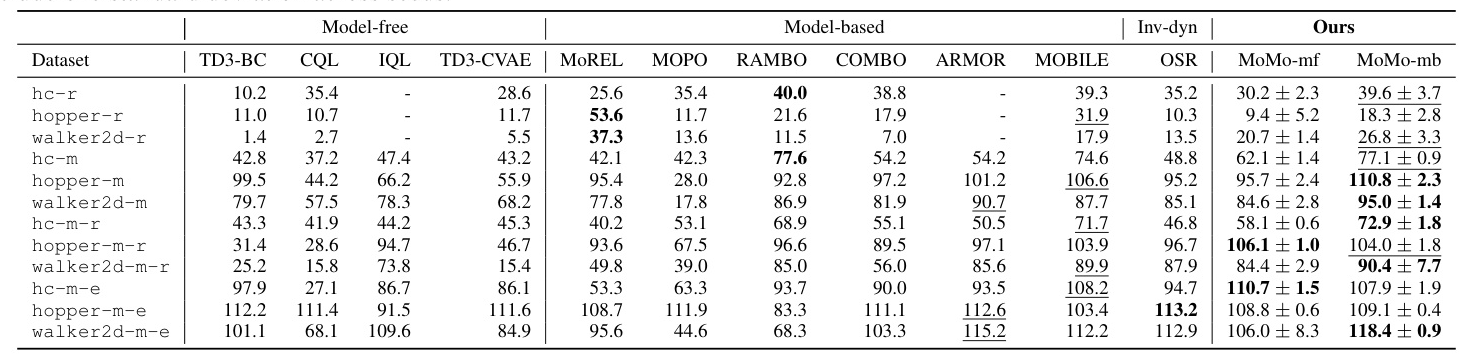
Performance on D4RL Datasets
MoMo demonstrates superior performance compared to recent baselines in both Gym Locomotion and Adroit tasks. The model-based version of MoMo achieves the highest scores in the majority of datasets, recovering expert performance in several cases.
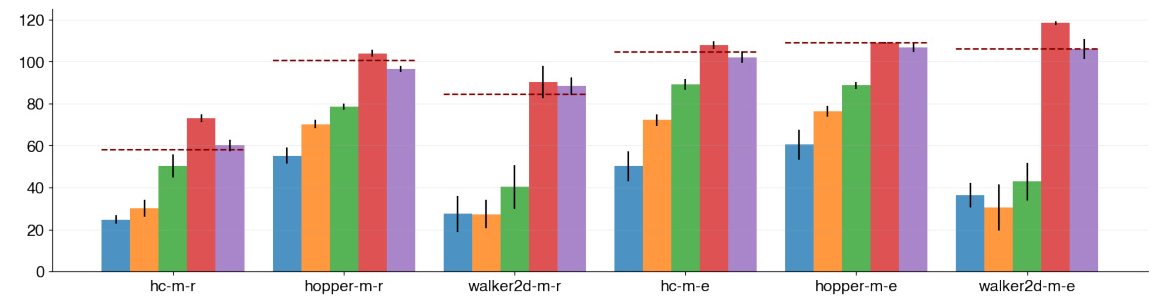
Ablation Studies
Truncation Threshold (ϵtrunc)
The ablation studies show that reducing the truncation threshold degrades performance, as it allows trajectories to deviate more from the behavior policy before being truncated. Increasing the threshold ensures that trajectories remain closer to the dataset, improving performance.
Kernel Scale (λ)
The kernel scale parameter controls the strength of the policy constraint. The studies reveal that a lower λ leads to a lax constraint, resulting in poor performance, while a higher λ overconstrains the policy. An optimal λ balances the constraint, leading to better performance.
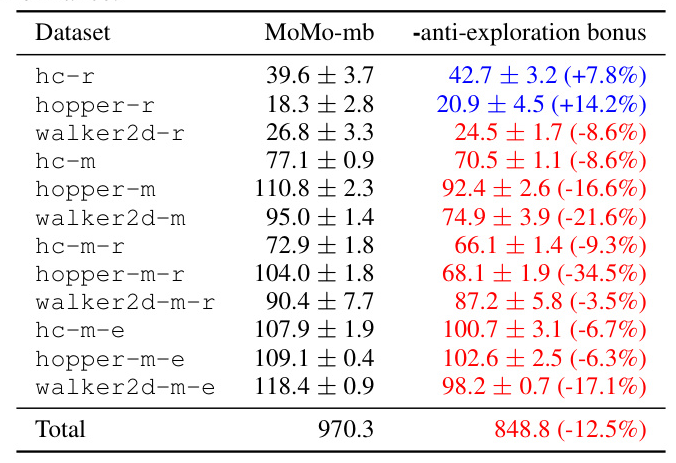
Importance of Anti-Exploration
The anti-exploration bonus is crucial for MoMo’s performance, as it helps curb value overestimation caused by off-policy evaluation. Removing the bonus results in a significant drop in performance, highlighting its importance in the anti-exploration framework.
Overall Conclusion
The paper presents MoMo, a novel approach to offline model-based RL that extends the anti-exploration paradigm to the model-based domain. By incorporating Morse neural networks for uncertainty estimation and policy constraints, MoMo addresses the challenges of offline MBRL, achieving superior performance compared to recent baselines. The experiments demonstrate the effectiveness of MoMo in both model-free and model-based settings, highlighting the benefits of incorporating dynamics models and the importance of anti-exploration.
Future work should explore how modern model-free offline RL approaches can be adapted for offline MBRL, further enhancing the robustness and generalization of these methods across different tasks and domains.