Authors:
Yerim Jeon、Subeen Lee、Jihwan Kim、Jae-Pil Heo
Paper:
https://arxiv.org/abs/2408.09734
Introduction
Object counting has seen significant advancements with the advent of deep learning. Traditional methods, however, are often limited to specific categories like humans or cars and require extensive labeled data. Few-shot object counting aims to address these limitations by enabling the counting of arbitrary objects in a query image based on a few exemplar images. The prevalent extract-and-match approach, while effective, suffers from a target confusion problem, especially in multi-class scenarios. This is because query and exemplar features are extracted independently, leading to insufficient target awareness. To tackle this, the authors propose a novel framework called Mutually-Aware Feature Learning (MAFEA), which ensures that query and exemplar features are mutually aware from the outset, thereby enhancing target specificity and reducing confusion.
Related Work
Class-Specific Object Counting
Class-specific object counting focuses on counting objects of a specific class, such as people or cars. Traditional methods often use detection-based approaches, which generate pseudo-bounding boxes from point-level ground truth. However, these methods struggle with scale variation and occlusion. Regression-based approaches have emerged as alternatives, treating the task as dense regression to predict object density maps. While effective, these methods cannot handle unseen object classes.
Few-Shot Object Counting
Few-shot object counting aims to count objects of arbitrary categories in a query image using a few exemplar images. Existing methods typically follow an extract-and-match approach, where query and exemplar features are extracted independently and then correlated. While these methods have achieved impressive performance, they do not sufficiently address the target confusion issue. The proposed MAFEA framework aims to solve this by computing query and exemplar features dependently on each other throughout the feature extraction process.
Vision Transformer
Transformers have shown great success in natural language processing and have been adapted for vision tasks like image classification, object detection, and semantic segmentation. For few-shot object counting, transformer-based architectures have been used to capture self-similarity priors. Unlike previous methods, MAFEA uses a mutually-aware feature extractor that computes query and exemplar features in a unified embedding space, incorporating a background token to distinguish target objects from background features.
Research Methodology
Overall Pipeline
The MAFEA architecture consists of a Vision Transformer (ViT) encoder, a relation learner, and a CNN decoder. Given a query image and a set of exemplar images, the images are split into patches and converted into query and exemplar features. These features are refined by the ViT encoder, which incorporates mutual relation modeling. The relation learner and CNN decoder then produce a density map, from which the number of objects in the query image is computed.
Mutual Relation Modeling
MAFEA encodes features based on self-relations within each image and co-relations between different images. This bi-directional interaction allows the model to refine query features to focus more on target-specific traits. The output sequences of the encoder layers are adapted based not only on their inherent self-relations but also on their interrelated correlations.
Background Token
To prevent background features from being represented by exemplar features, MAFEA introduces a background token. This token is designed to learn the general features of the background region and is incorporated into the self-relation and co-relation modeling. This helps in distinguishing target objects from background features, including non-target objects.
Target-Background Discriminative Loss
The background token is trained using a Target-Background Discriminative (TBD) loss, which encourages the token to align with background features. The alignment score represents the degree of alignment between query features and the background token. The TBD loss ensures that the background token aligns only with background features, enhancing the model’s ability to differentiate between target and background regions.
Training Loss
The training loss comprises the object-normalized L2 loss, which measures the mean squared error between the predicted and ground truth density maps, and the auxiliary loss for intermediate density maps. The full objective function includes weights for the auxiliary loss and TBD loss.
Experimental Design
Implementation Details
The MAFEA framework includes a ViT encoder, relation learner, and CNN decoder. The ViT encoder is initialized with self-supervised pre-trained weights, while the relation learner and CNN decoder are randomly initialized. The model is trained using the AdamW optimizer with a batch size of 8 and an initial learning rate of 1e-4, halved every 40 epochs. Training is performed on a single RTX3090 GPU for 100 epochs.
Datasets and Metrics
Experiments are conducted on three benchmark datasets: FSCD-LVIS, FSC-147, and CARPK. FSCD-LVIS contains complex scenes with multiple class objects, while FSC-147 consists of simpler scenes with single-class objects. CARPK is used to validate the model’s generalization capability. The evaluation metrics include Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE).
Configuration of Multi-Class Subset
To assess the model’s ability to identify the target class in multi-class scenarios, a multi-class subset of FSC-147 (FSC-147-Multi) is constructed. This subset includes images where non-target objects constitute more than 20% of the target class objects.
Results and Analysis
Comparison with State-of-the-Art
MAFEA outperforms state-of-the-art methods in both multi-class and single-class scenarios. On FSCD-LVIS, MAFEA shows an 11% improvement in MAE and a 4.6% improvement in RMSE compared to the second-best performer. On FSC-147-Multi, MAFEA achieves a 26.30% improvement in MAE and a 24.63% improvement in RMSE.

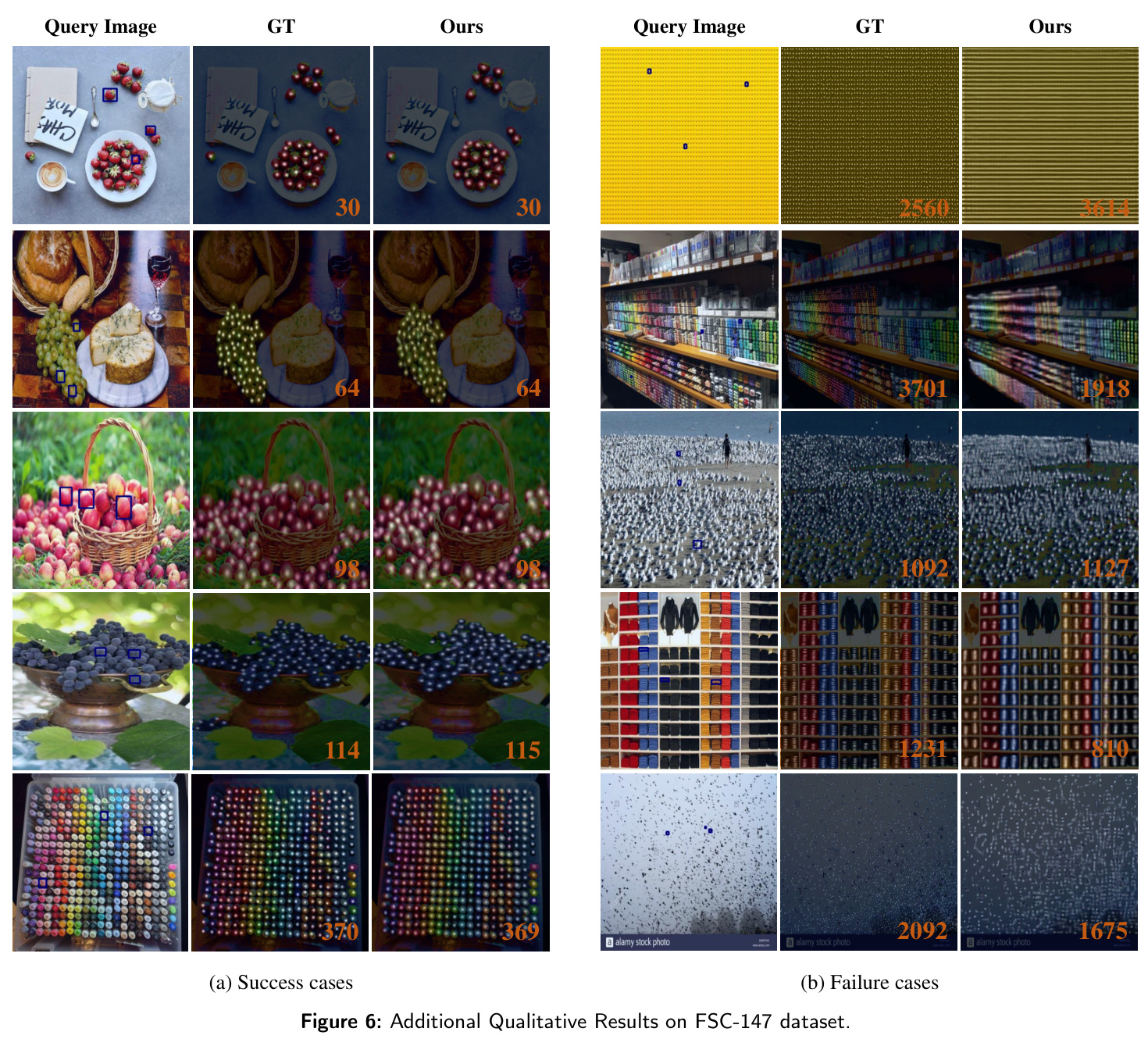
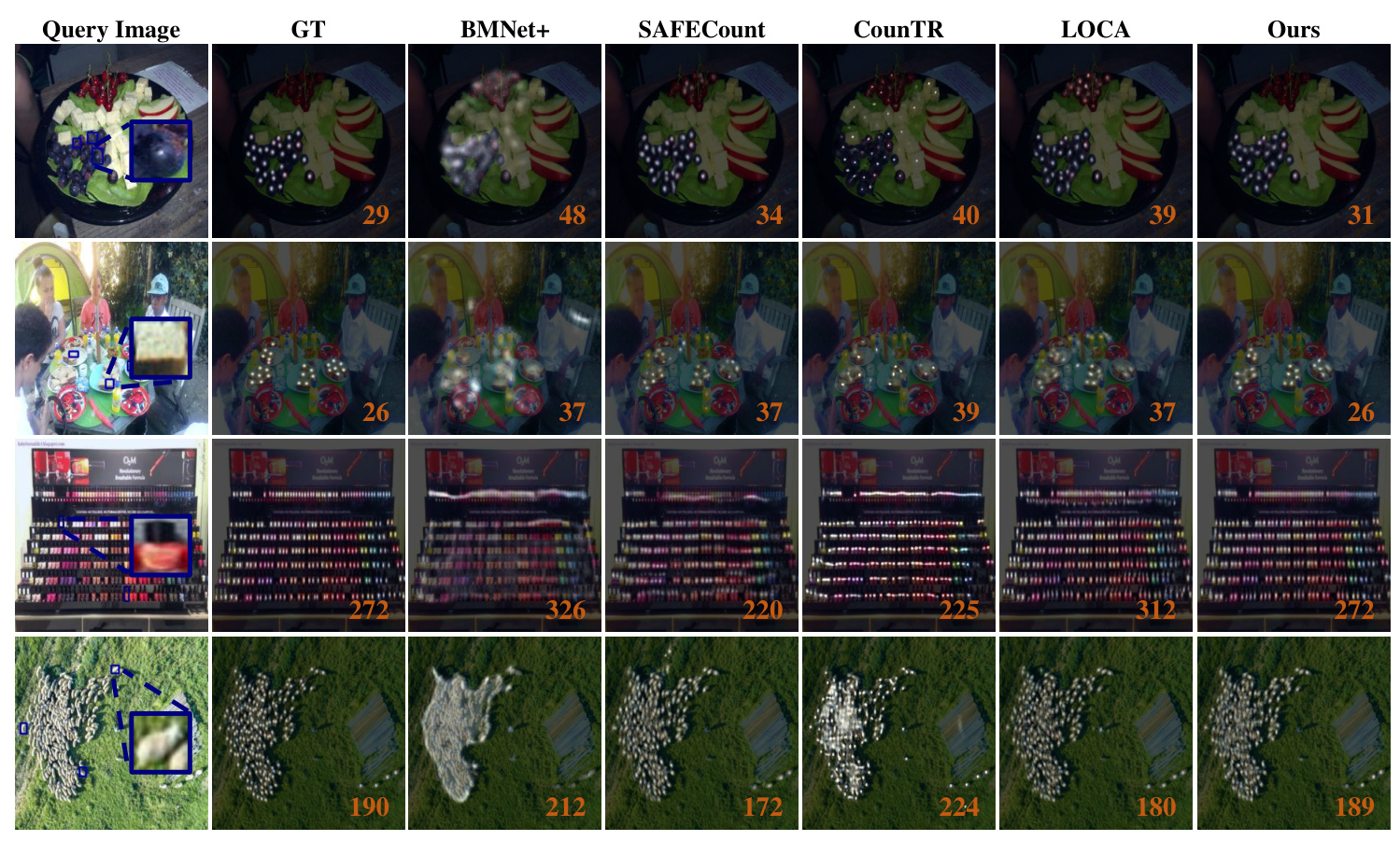
Qualitative Results
Qualitative results demonstrate that MAFEA accurately distinguishes target objects based on exemplar images, even in dense scenes. Prior methods often count non-target objects sharing similar scale or appearance properties, while MAFEA excels in target specificity.
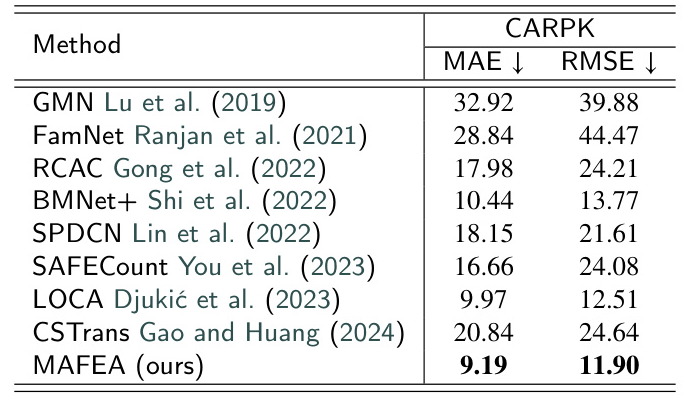
Cross-Dataset Generalization
MAFEA shows robust generalization performance on the CARPK dataset, outperforming current state-of-the-art methods without fine-tuning. This demonstrates the model’s robustness in cross-dataset generalization.
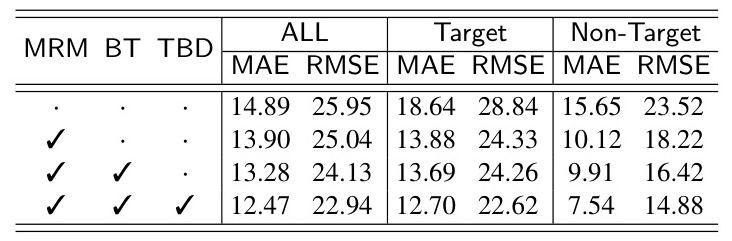
Ablation Study
Ablation studies confirm the effectiveness of mutual relation modeling, the background token, and the TBD loss. These components significantly enhance target recognition and reduce target confusion. The evaluation within target and non-target regions further validates the model’s ability to count only the target objects.
Overall Conclusion
The proposed MAFEA framework addresses the target confusion problem in few-shot object counting by ensuring mutual awareness between query and exemplar features from the outset. The incorporation of mutual relation modeling, a background token, and the TBD loss enables the model to produce highly target-aware features, effectively distinguishing target objects from background features. Extensive experiments demonstrate the robustness and effectiveness of MAFEA, achieving state-of-the-art performance in both multi-class and single-class scenarios. The framework’s ability to generalize across datasets further highlights its practical applicability.