

Authors:
Paper:
https://arxiv.org/abs/2408.10921
MTFinEval: A Comprehensive Multi-domain Chinese Financial Benchmark
Introduction
In the rapidly evolving field of economics, Large Language Models (LLMs) have emerged as powerful tools for providing insights and enhancing the efficiency of economic industry development. However, with the increasing specialization of these models, a critical question arises: how can we effectively measure their performance and ensure their reliability in real-world applications? Traditional benchmarks, often focused on specific scenarios, fail to capture the theoretical depth and generalization capabilities required for comprehensive economic analysis. This study introduces MTFinEval, a new benchmark designed to evaluate the foundational economic knowledge of LLMs, ensuring their robustness and reliability in diverse economic contexts.
Related Work
The application of LLMs in finance and economics has shown significant promise, with models like BloombergGPT and FinMA demonstrating capabilities in financial natural language processing (NLP) tasks such as market trend analysis, investment report generation, and risk assessment. However, existing evaluations often focus on general NLP tasks, lacking the depth required to assess economic reasoning and theoretical understanding. The EconNLI dataset, for instance, highlights deficiencies in LLMs’ economic reasoning abilities, underscoring the need for more rigorous and specialized benchmarks. Additionally, the integration of economic theory into LLMs has been shown to enhance their performance in financial analysis and forecasting, further emphasizing the importance of systematic evaluation.
Research Methodology
Dataset Statistics
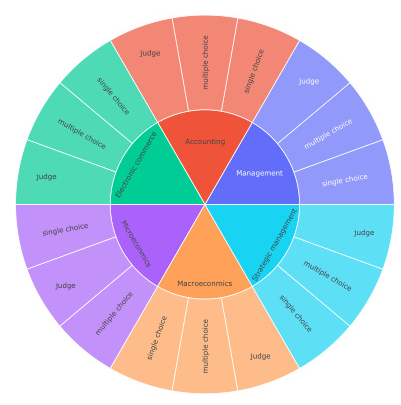
MTFinEval comprises 360 questions sourced from university textbooks and exam papers across six major economic disciplines: macroeconomics, microeconomics, accounting, management, e-commerce, and strategic management. The questions are categorized into single choice, multiple choice, and true or false formats, ensuring a comprehensive assessment of the models’ theoretical knowledge. The data collection process involved meticulous manual entry and expert review to ensure accuracy and clarity.
Formulation
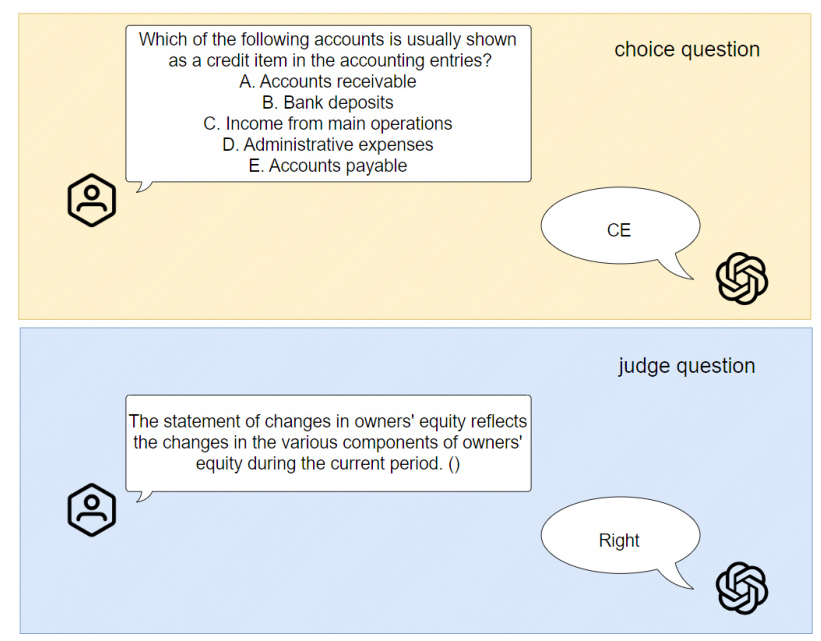
The benchmark evaluates LLMs in a zero-shot scenario, where models are provided with questions and must generate answers without prior exposure to the specific questions. The objective functions for different question types (true or false, single choice, multiple choice) are defined to assess the models’ ability to recall and apply relevant economic knowledge from their training data.
Experimental Design
Experimental Setup
To simulate real-world use cases, the questions are presented with brief prompts under zero-shot conditions. The prompts guide the models to provide answers based on their financial knowledge without outputting the reasoning process. The evaluation focuses on open-source models released in 2024, ensuring a level playing field for comparison.
Results
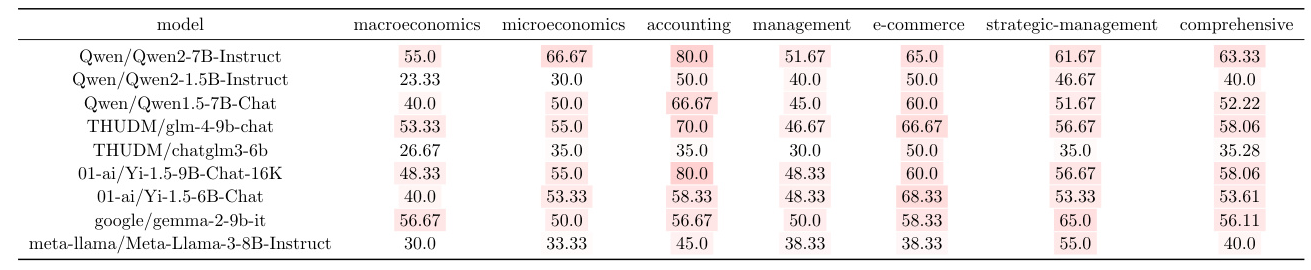
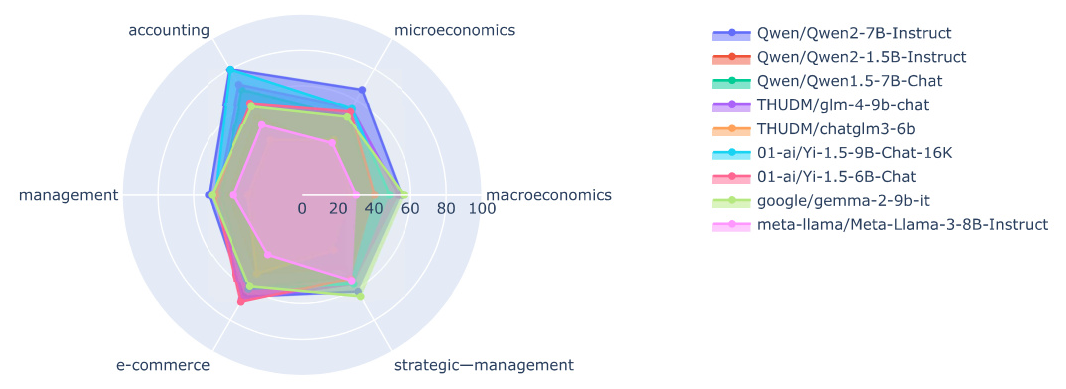
The performance of various LLMs on the MTFinEval benchmark reveals significant insights into their capabilities and limitations. The Qwen/Qwen2-7B-Instruct model emerged as the top performer with a comprehensive score of 63.33, demonstrating proficiency across multiple economic disciplines. In contrast, models like the meta-llama/Meta-Llama-3-8B-Instruct scored lower, indicating potential gaps in their training data or architectural limitations.
Results and Analysis
Specialization in Subjects
Certain models exhibited expertise in specific domains. For instance, the 01-ai/Yi-1.5-9B-Chat-16K model excelled in accounting, e-commerce, and strategic management, likely due to its rich dataset in these areas. Similarly, the THUDM/glm-4-9b-chat model showed a strong understanding of macroeconomics, reflecting its exposure to diverse economic data.
Overall Performance
The Qwen/Qwen2-7B-Instruct model’s high overall score suggests a well-rounded training approach, equipping it to handle a variety of economic analyses. This model’s performance indicates its potential to set a new standard for financial LLMs, possibly outperforming previous models like Llama in certain applications.
Reflection on Weaker Performances
Models with lower scores, such as the meta-llama/Meta-Llama-3-8B-Instruct, may benefit from more diverse and pertinent training data. Continuous updates and refinements to the model architecture, informed by performance data, can further enhance their capabilities.
Overall Conclusion
MTFinEval provides a rigorous and comprehensive benchmark for evaluating the foundational economic knowledge of LLMs. The experimental results highlight significant gaps in current models’ theoretical understanding of economics, emphasizing the need for ongoing improvements. This research contributes to the field by offering a robust evaluation framework that can guide future developments in LLMs, ensuring they are better equipped to navigate complex and dynamic economic environments.
By focusing on the fundamental theoretical knowledge, MTFinEval sets a new standard for assessing the capabilities of LLMs in the financial domain, paving the way for more reliable and effective applications in the real world.