

Authors:
Xukun Zhou、Fengxin Li、Ziqiao Peng、Kejian Wu、Jun He、Biao Qin、Zhaoxin Fan、Hongyan Liu
Paper:
https://arxiv.org/abs/2408.09357
Introduction
Background
Audio-driven 3D talking face animation has become increasingly prevalent in various sectors, including gaming, live streaming, and animation production. These applications leverage advanced technologies such as 3D parametric models, Neural Radiance Fields, and Gaussian splatting to achieve accurate lip synchronization and facial emotions. Despite significant progress, the intricate relationship between facial expressions and accompanying audio still needs to be explored, particularly in the context of speaking style adaptation.
Problem Statement
Most existing approaches for audio-driven 3D face animation are designed for specific individuals with predefined speaking styles, neglecting the adaptability to varied speaking styles. This limitation poses a significant challenge in creating flexible and straightforward methods for speaking style adaptation that utilize minimal data.
Objective
To address this limitation, the paper introduces MetaFace, a novel methodology meticulously crafted for speaking style adaptation. Grounded in the novel concept of meta-learning, MetaFace aims to facilitate rapid adaptation with minimal data, significantly outperforming existing baselines and establishing a new state-of-the-art.
Related Work
Lip Synchronization in 3D Face Animation
Early methods for 3D face animation primarily relied on audio produced by Text-to-Speech technologies and real-life facial motion videos animated using visemes to extract features synchronized with audio. However, these methods posed significant challenges in creating animations tailored to individual users. To overcome these limitations, deep learning-based approaches were introduced, leveraging neural networks to generate mesh movements directly from audio features. Despite remarkable progress, these methods primarily focused on improving lip synchronization, overlooking the equally important question of personalized speaking style adaptation.
Speaking Style Adaptation in 3D Face Animation
Recent advancements in 3D face animation have increasingly focused on adapting speaking styles. Studies primarily explore two approaches: utilizing external personality labels and decoupling facial features from audio. Although these approaches mark significant progress, they still face substantial challenges, such as the necessity of a considerable amount of data for effective speaking style distillation and the prevalent use of cross-training technologies for speaking style adaptation, which requires paired sentences, reducing application flexibility.
Meta-learning and Parameter Adaptation
Meta-learning enables deep models to adapt to novel categories with minimal training data. The concept of meta-learning was first introduced to adapt the learning rate for novel category adaptation. Subsequently, model-agnostic meta-learning approaches for fast adaptation were proposed, utilizing the concept of learning to learn. Advancements in model pretraining have significantly influenced meta-learning, with techniques like LoRA (Low-Rank Adaptation) reducing computational costs while maintaining performance. Despite numerous meta-learning methods and parameter adaptation techniques being proposed and widely applied across various domains, their potential in efficient 3D face animation still needs to be explored.
Research Methodology
Method Overview
MetaFace explores the critical issue of personalized speaking style adaptation, advocating for a “meta-face” methodology tailored explicitly for superior adaptation to novel individuals. The final objective is to construct a model, denoted by ( f_{\theta} ), by leveraging samples from a diverse dataset. This model is subsequently refined through fine-tuning with the personalized dataset, enhancing the model’s efficacy on the dataset specific to individual users.
Robust Meta Initialization Stage (RMIS)
The RMIS updates the model’s weights to produce an initial weight configuration, equipping a pretrained 3D talking face animation model with the capability to learn an individual’s unique speaking style. This stage involves training a meta face model as a robust initialization for adapting to new samples, allowing the model to rapidly assimilate basic cues from a new individual efficiently.
Low-rank Matrix Memory Reduction Approach
Following the RMIS, the subsequent phase involves meticulous model fine-tuning, enabling the model to assimilate additional, intricate details specific to each individual. This phase adopts a low-rank decomposition approach to reduce the memory footprint significantly, enhancing the model’s ability to capture and replicate the nuanced characteristics inherent in the speaking style of the subject.
Dynamic Relation Mining Neural Process (DRMN)
The DRMN enables the model to discern the domain disparities between previously modeled individuals and the new subject, unearthing intrinsic relationships and promoting model adaptability to the speaking style domain of the new individual. This enhancement facilitates the model’s ability to establish additional connections between training and testing samples, further enhancing the performance of speaking style adaptation.
Experimental Design
Experimental Details
To assess the efficacy of MetaFace, experiments are conducted using two publicly recognized datasets: VOCASet and BIWI. The VOCASet includes 480 sentences captured from 12 subjects, while the BIWI dataset contains 15,000 frames featuring 20 subjects engaged in speech. Audio features are extracted using the wav2vec model. The meta-learning framework employs an 11-way 1-shot pretraining strategy, with specific learning rates and loss weights assigned for the global and fine-tuning stages.
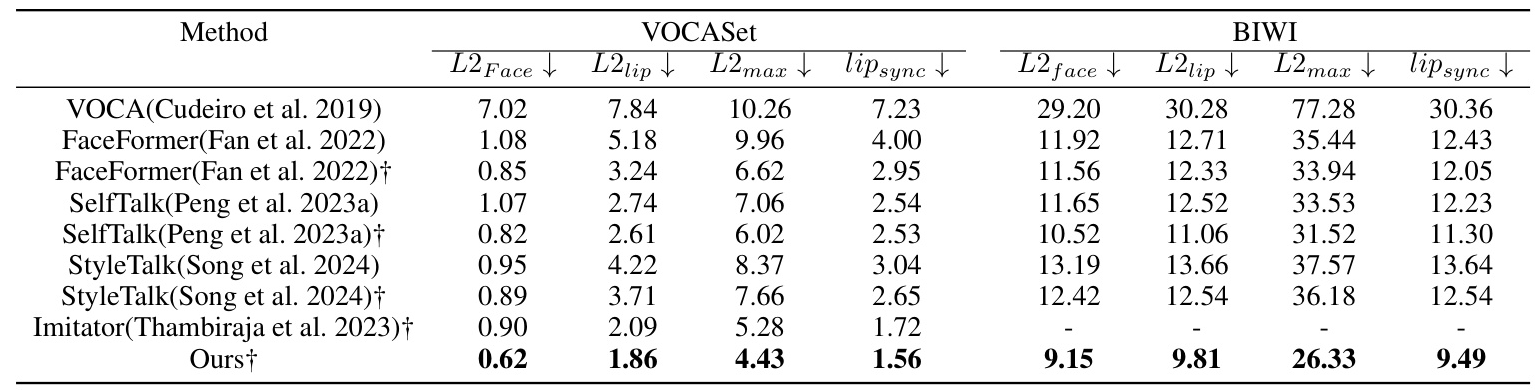
Evaluation Metrics
For evaluation, the L2 vertex error across the entire face (l2face) and within the lip regions (l2lip) is measured to assess the accuracy of the facial animations. Additionally, Dynamic Time Warping (DTW) is employed to evaluate lip synchronization (lipsync), and the mean of the maximum error per frame (lipmax) is used to gauge performance.
Results and Analysis
Quantitative Evaluation
MetaFace is compared with leading-edge methodologies such as VOCA, FaceFormer, SelfTalk, StyleTalk, and Imitator. As delineated in Table 1, MetaFace outperforms all compared methods in terms of reduced facial animation errors and enhanced lip synchronization. These exemplary results signify substantial enhancements in both overall facial movements and lip motions.
Qualitative Evaluation
A series of visualization results demonstrate that MetaFace surpasses competing methods in terms of visual outcomes. Notably, MetaFace exhibits the most lifelike facial movements for various sounds, aligning more closely with the ground truth results.

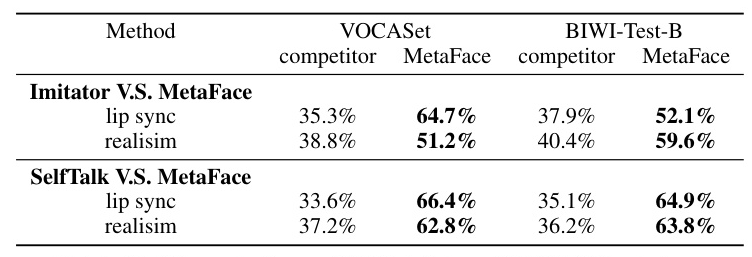
User Study
A user study is conducted to explore the practical efficacy of 3D face animation. Participants view videos from each method side-by-side and select the most realistic animation. MetaFace achieves a support ratio of 66.4% against Imitator on the VOCASet, emphasizing its superior performance in realistic facial animation.
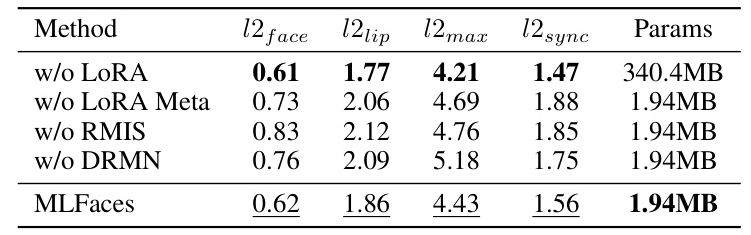
Ablation Study
An ablation study demonstrates the effectiveness of key design components within MetaFace. The robust meta initialization, dynamic relation mining neural process, and low-rank matrix memory reduction approach each contribute significantly to the overall performance, enhancing lip synchronization and reducing face motion error.
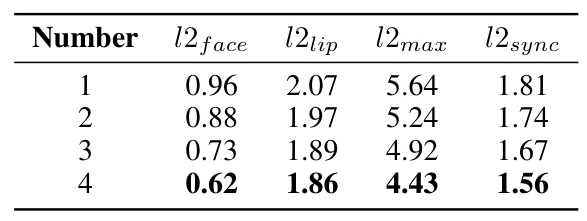
Generalization Test
The generalization ability of MetaFace concerning the number of adaptation samples is investigated. Results indicate that increasing the sample count significantly reduces the l2face error, demonstrating that a greater number of samples notably improves the model’s generalization capability in facial feature reconstruction.
Overall Conclusion
MetaFace introduces a novel model for audio-driven 3D face animation that addresses the challenge of personalized speaking style adaptation. Comprising three key components—the Robust Meta Initialization Stage (RMIS), the Dynamic Relation Mining Neural Process (DRMN), and the Low-rank Matrix Memory Reduction Approach—MetaFace significantly surpasses existing baselines and sets a new benchmark in the field. By leveraging the foundational principles of meta-learning, MetaFace facilitates rapid adaptation with minimal data, showcasing superior performance in both overall facial movements and lip motions.