Authors:
Yongjin Yang、Haneul Yoo、Hwaran Lee
Paper:
https://arxiv.org/abs/2408.06816
Introduction
Large Language Models (LLMs) have shown remarkable capabilities in various tasks, including solving mathematical problems, acquiring world knowledge, and summarizing texts. However, they still suffer from producing plausible but incorrect responses, often referred to as hallucinations. To address this, recent research has focused on uncertainty quantification to predict the correctness of responses. This paper investigates previous uncertainty quantification methods under the presence of data uncertainty, which arises from irreducible randomness, unlike model uncertainty, which stems from a lack of knowledge.
Contributions
The paper makes two primary contributions:
1. Proposing a new Multi-Answer Question Answering dataset, MAQA, consisting of world knowledge, mathematical reasoning, and commonsense reasoning tasks to evaluate uncertainty quantification regarding data uncertainty.
2. Assessing five uncertainty quantification methods across diverse white- and black-box LLMs.
Evaluation Settings
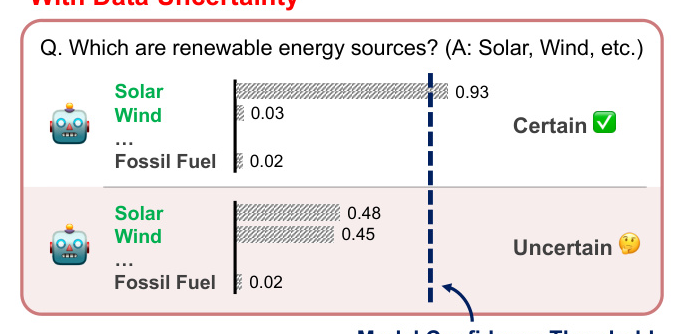
The evaluation settings are illustrated in Figure 1, showing scenarios with and without data uncertainty. When evaluating questions with multiple answers, it becomes challenging to distinguish between model uncertainty and data uncertainty due to the existence of multiple possible answers.
Related Work
Question and Answering Dataset with Multi Answers
Several datasets include questions requiring multiple answers, but they often contain a limited number of such questions or arise from ambiguity. The MAQA benchmark covers over 2,000 questions requiring multiple answers across various tasks, including world knowledge, mathematical reasoning, and commonsense reasoning.
Uncertainty Quantification for LLMs
Uncertainty quantification has emerged as a significant task to increase the reliability of LLM responses. There are two main approaches: white-box methods, which use internal states of LLMs, and black-box methods, which use the responses of LLMs to estimate confidence.
Multi Answer Dataset
The MAQA dataset consists of 2,042 question-answer pairs, each requiring more than one answer. It covers three tasks: world knowledge, mathematical reasoning, and commonsense reasoning.
Data Collection
MAQA was generated by modifying existing benchmarks and creating new question-answer sets. The dataset includes 642 world knowledge pairs, 400 mathematical reasoning pairs, and 1,000 commonsense reasoning pairs.

Data Analysis
The dataset has a diverse range of answers, making it suitable for analyzing data uncertainty. The final dataset comprises 2,042 QA pairs, covering three different tasks with varying numbers of answers for each question.
Experimental Setting
The experiments aim to answer three key research questions:
1. How do white-box and black-box based uncertainty quantification methods perform in the presence of data uncertainty?
2. How does uncertainty quantification performance vary across different tasks?
3. Can previous uncertainty quantification methods correlate with how many answers are correct among all ground-truth answers (i.e., recall)?
Datasets
The evaluation uses both multi-answer datasets (MAQA) and single-answer datasets to compare the effects of the multi-answer setting.
Uncertainty Quantification Methods
White-box LLMs
Several methods measure uncertainty using the internal states of white-box LLMs, such as logit information. The methods include Max Softmax Logit, Entropy, and Margin.
Black-box LLMs
For black-box LLMs, uncertainty quantification uses only the responses of LLMs. The methods include Verbalized Confidence and Response Consistency.
Evaluation Metrics
The correctness of single answers is measured using accuracy, while multiple answers are evaluated using precision, recall, and F1 score. Uncertainty quantification performance is primarily evaluated using the Area Under the Receiver Operating Characteristic Curve (AUROC).
Implementation Details
The experiments use various white-box and black-box LLMs, including Llama3, Qwen, Zephyr, Mistral, Mixtral, Gemma, GPT-3.5, and GPT-4. The evaluation uses greedy sampling for white-box LLMs and top-p sampling for black-box LLMs.
Experimental Results
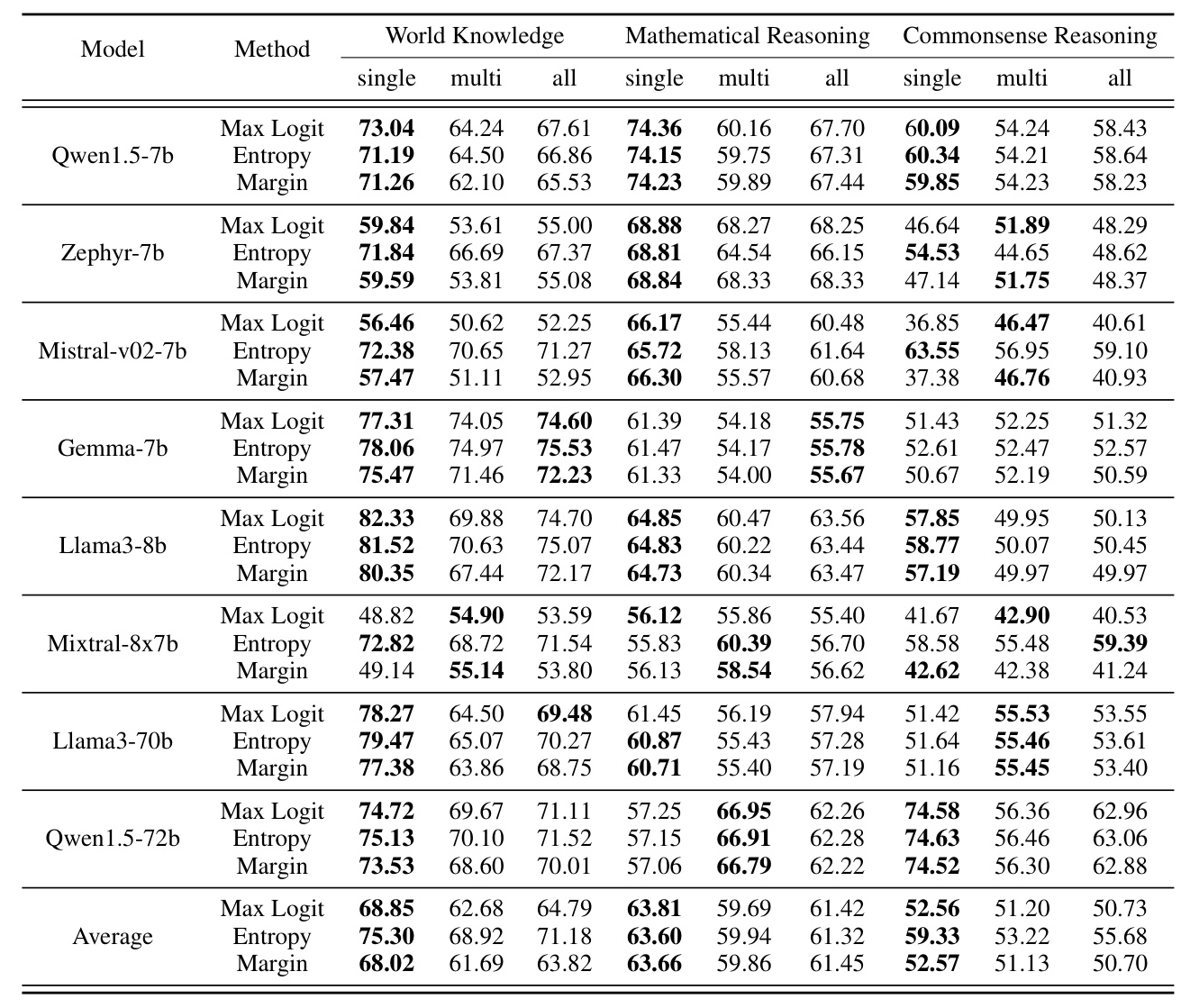
Uncertainty Quantification Results of White-box LLMs
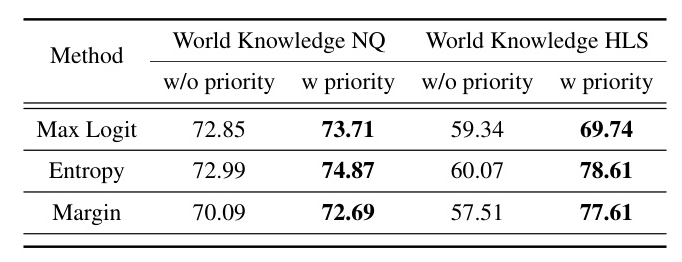
The AUROC scores for different uncertainty quantification methods across various tasks and models show that data uncertainty impacts logit distributions in the world knowledge task. However, entropy remains useful for predicting the correctness of answers.
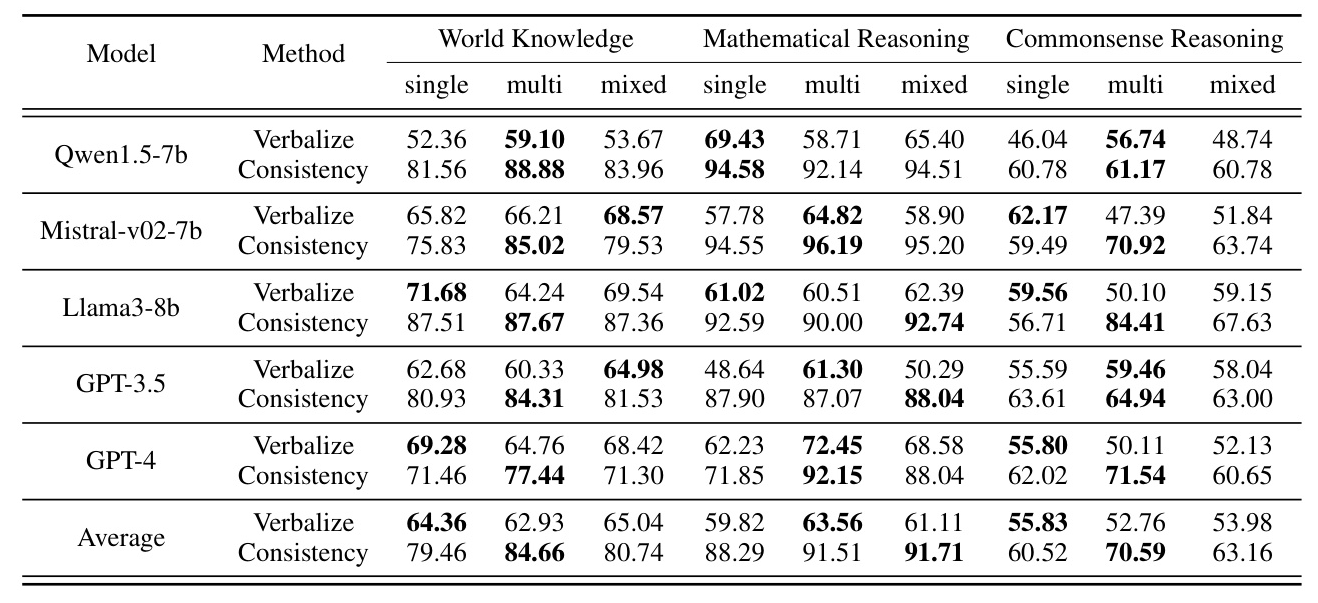
Uncertainty Quantification Results of Black-Box LLMs
The results show that verbalized confidence struggles significantly due to overconfidence, while response consistency works extremely well across all tasks, especially on multi-answer datasets.
Recall and F1 Score
Both logit-based and response-based methods can predict recall and F1 score even when the number of answers grows large, demonstrating their effectiveness in uncertainty quantification.
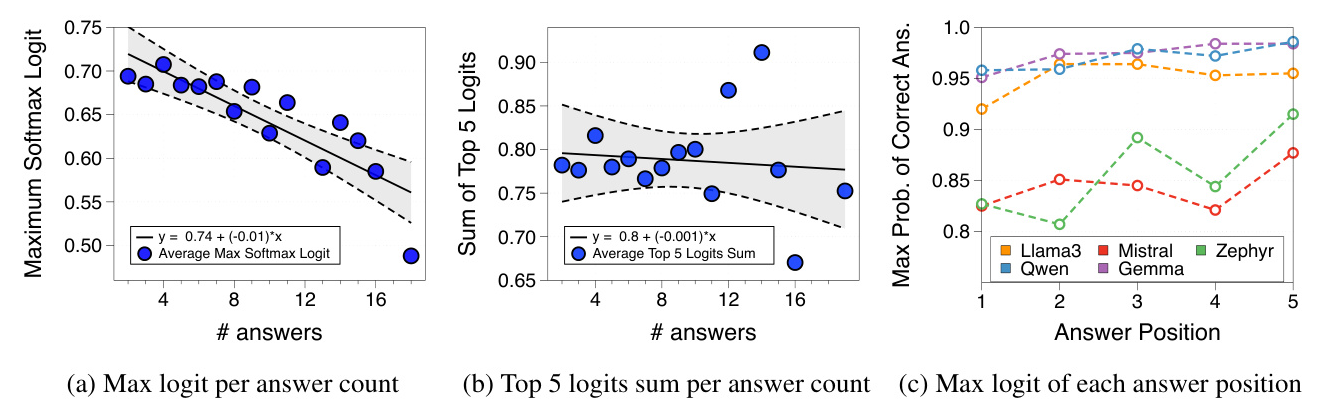
Conclusion
This paper contributes to uncertainty quantification in LLMs by proposing the MAQA benchmark and investigating various methods in the presence of data uncertainty. The findings highlight the challenges and effectiveness of different approaches, providing a foundation for future research in more realistic settings.
Limitations
The MAQA dataset, despite quality checks, may contain some ambiguous questions or unclear answers. Future work should investigate hyperparameter settings and establish guidelines for uncertainty quantification methods.
Ethics Statement
Addressing hallucinations in LLMs is crucial to ensure ethical AI deployment. Uncertainty quantification methods can help identify and flag potentially unreliable information, enhancing the trustworthiness of AI-generated content.
Acknowledgements
The authors thank Namgyu Ho for feedback on the paper’s outline and Jimin Lee for discussions on dataset annotation.