

Authors:
Xiao Wang、Chao wang、Shiao Wang、Xixi Wang、Zhicheng Zhao、Lin Zhu、Bo Jiang
Paper:
https://arxiv.org/abs/2408.10487
Introduction
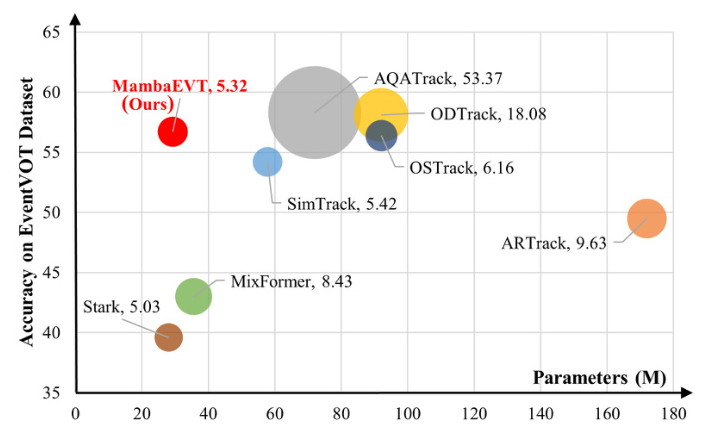
Event camera-based Visual Object Tracking (VOT) has garnered significant attention due to its unique imaging principles and advantages, such as low energy consumption, high dynamic range, and dense temporal resolution. Traditional event-based tracking algorithms are facing performance bottlenecks due to the reliance on vision Transformers and static templates for target localization. This paper introduces MambaEVT, a novel visual tracking framework that leverages the state space model with linear complexity as its backbone network. The framework integrates a dynamic template update strategy using the Memory Mamba network, aiming to balance accuracy and computational cost effectively.
Related Work
Event-based Visual Object Tracking
Event-based VOT has evolved significantly, with early works focusing on methods like event-guided support vector machines and particle filters. Recent advancements include the fusion of RGB frames and event streams, hierarchical knowledge distillation, and the development of spiking Transformer networks. However, these methods often suffer from high computational complexity and static target templates, limiting their performance in long-term tracking and scenarios with significant appearance variations.
Dynamic Template Updating
Dynamic template updating is crucial for adapting to appearance changes during tracking. Early methods combined dynamic template updating with Kalman filters or used LSTM with spatial attention. Recent approaches like Memformer and STARK have introduced efficient neural networks and template update mechanisms to enhance tracking accuracy. The Memory Mamba network proposed in this paper aims to improve tracking performance by capturing temporal changes in appearance features.
State Space Model
State space models (SSMs) have gained popularity for their ability to handle long sequences with lower computational complexity. The Mamba architecture enhances SSMs with selective scan operators and hardware-aware algorithms, making them suitable for visual tasks. This paper leverages the Mamba model to build a pure Mamba-based single object tracking algorithm, achieving a balance between accuracy and computational cost.
Research Methodology
Preliminary: Mamba
The Mamba architecture enhances the raw state space model by introducing selective scan operators and hardware-aware algorithms. This allows for efficient modeling of visual information, making it suitable for event-based visual tracking.
Overview
The proposed MambaEVT framework follows the Siamese tracking framework. Event streams are stacked into event frames, and the target template and search region are cropped as inputs. These inputs are embedded into event tokens and fed into the vision Mamba backbone network for feature extraction and interactive learning. The tracking head takes the tokens corresponding to the search region for target localization. A dynamic template generation module using Memory Mamba addresses significant appearance variations.
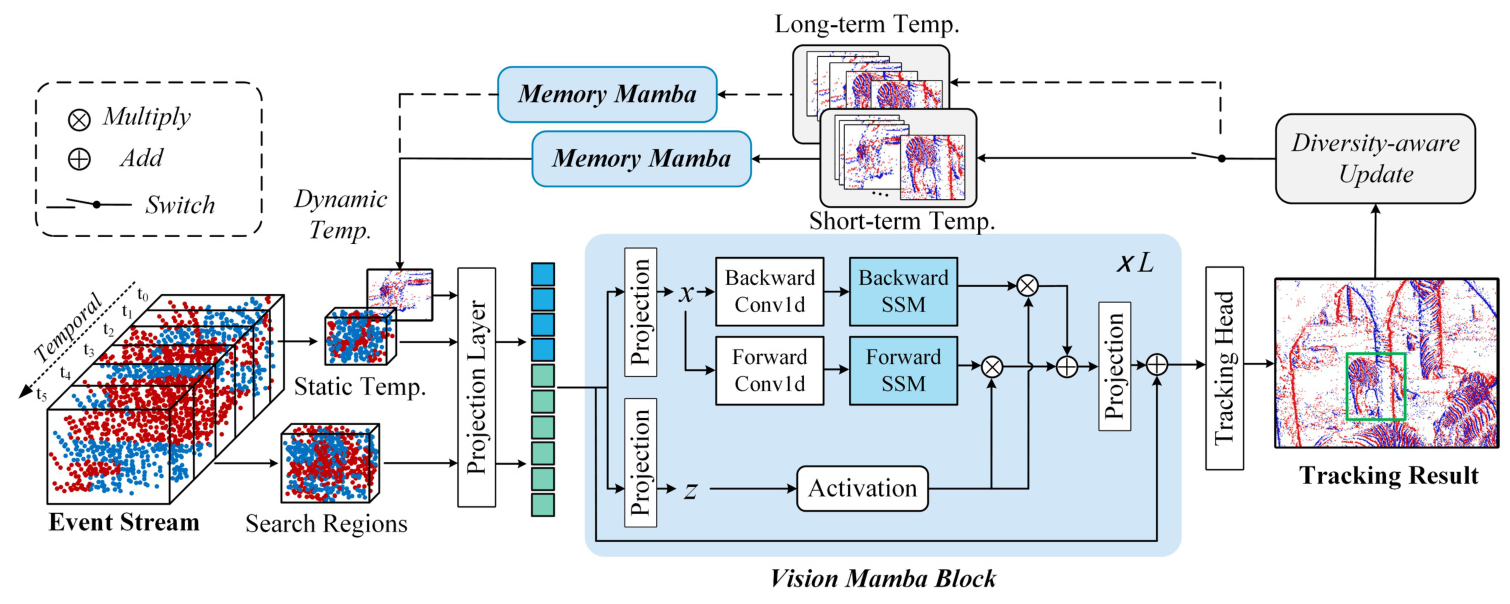
Input Representation
Event streams are represented as sequences of event points, each with spatial coordinates, timestamp, and polarity. The event image is obtained by splitting the event stream into fixed-length sequences. The initial template and search region are extracted from the first frame and represented as event tokens.
Mamba-based Tracking
The search region and static template are embedded and flattened into one-dimensional tokens. These tokens are concatenated with dynamic features and passed through the Vision Mamba block for feature extraction, interaction, and fusion. The tracking head, implemented as a Fully Convolutional Network (FCN), produces a target classification score map, local offset, and normalized bounding box size for target detection.
Dynamic Template Update Strategy
The Memory Mamba network collects tracking results and generates an adaptive dynamic template. The template library is updated using long-term and short-term memory libraries. The Memory Mamba network fuses these templates into a single dynamic template, enhancing the tracker’s ability to adapt to appearance changes.
Loss Function
The loss functions used in the framework include a weighted combination of focal loss, L1 loss, and Generalized Intersection over Union (GIoU) loss. The overall loss function is defined as:
[
\mathcal{L} = \lambda_{1}L_{1} + \lambda_{2}\mathcal{L}{focal} + \lambda{3}\mathcal{L}_{GIoU}
]
Experimental Design
Datasets and Evaluation Metrics
Experiments were conducted on three event-based tracking datasets: EventVOT, FE240hz, and VisEvent. Evaluation metrics included Precision Rate (PR), Normalized Precision Rate (NPR), and Success Rate (SR).
Implementation Details
The tracker was implemented using Python and PyTorch, with experiments conducted on NVIDIA RTX 3090 GPUs. Two variants were proposed: MambaEVT and MambaEVT-P. The backbone network was initialized using the Vim-S model pre-trained on ImageNet-1K and trained for 50 epochs. The number of dynamic templates was set to 7 during training, with both long-term and short-term memories fully populated during testing.
Results and Analysis
Comparison with State-of-the-art
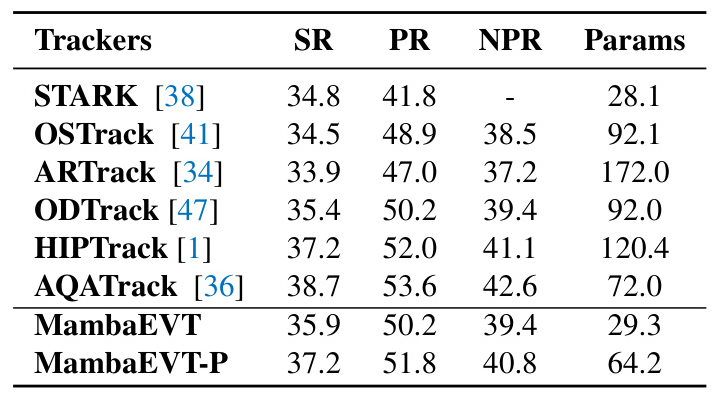
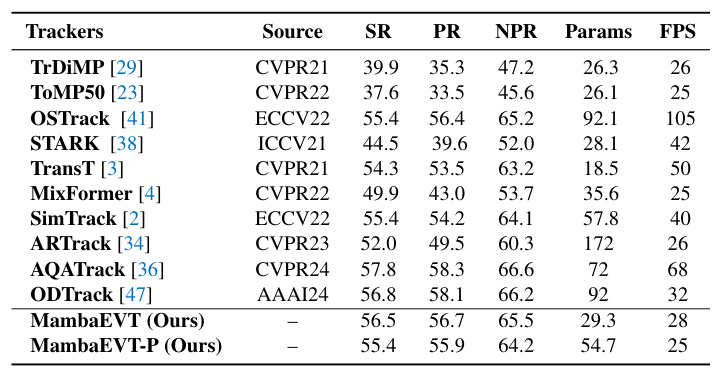
- EventVOT Dataset: MambaEVT achieved competitive performance with significantly fewer parameters compared to other state-of-the-art trackers.
- FE240hz Dataset: MambaEVT demonstrated a good balance between performance and parameter efficiency.
- VisEvent Dataset: MambaEVT showed competitive tracking performance with fewer parameters, highlighting its efficiency.
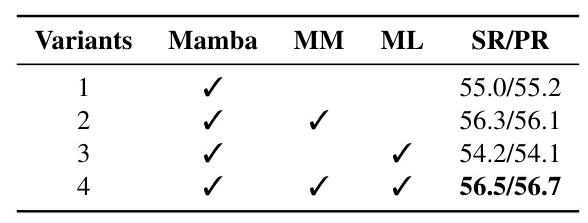

Ablation Study
- Component Analysis: The integration of the Memory Mamba module and Memory Library strategy significantly improved model performance.
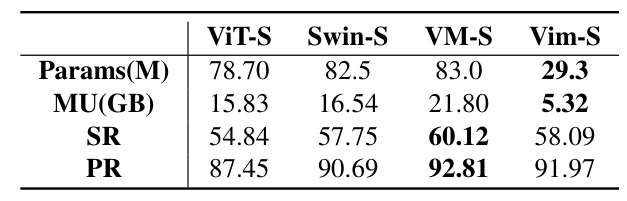
- Backbone Networks: The Vim-S model was chosen for its balance between performance and computational resource usage.
- Memory Library Capacities: Increasing the long-term memory queue capacity improved tracking performance.
- Dynamic Templates: The optimal number of dynamic templates was found to be 11.
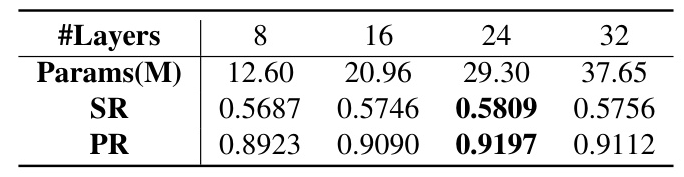
- Number of Layers: The optimal number of Mamba layers was 24.
- Hyper-parameters: A sampling interval of 5 provided the best performance.
- Temporal Windows: Smaller temporal windows resulted in better performance.

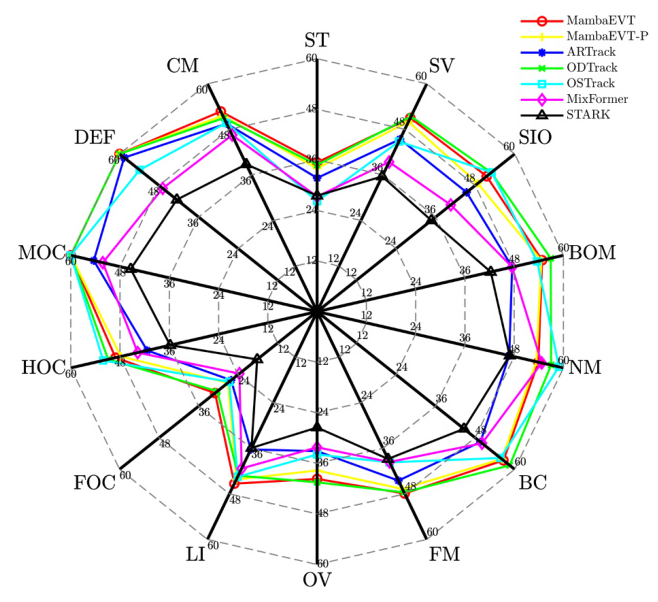
Visualization
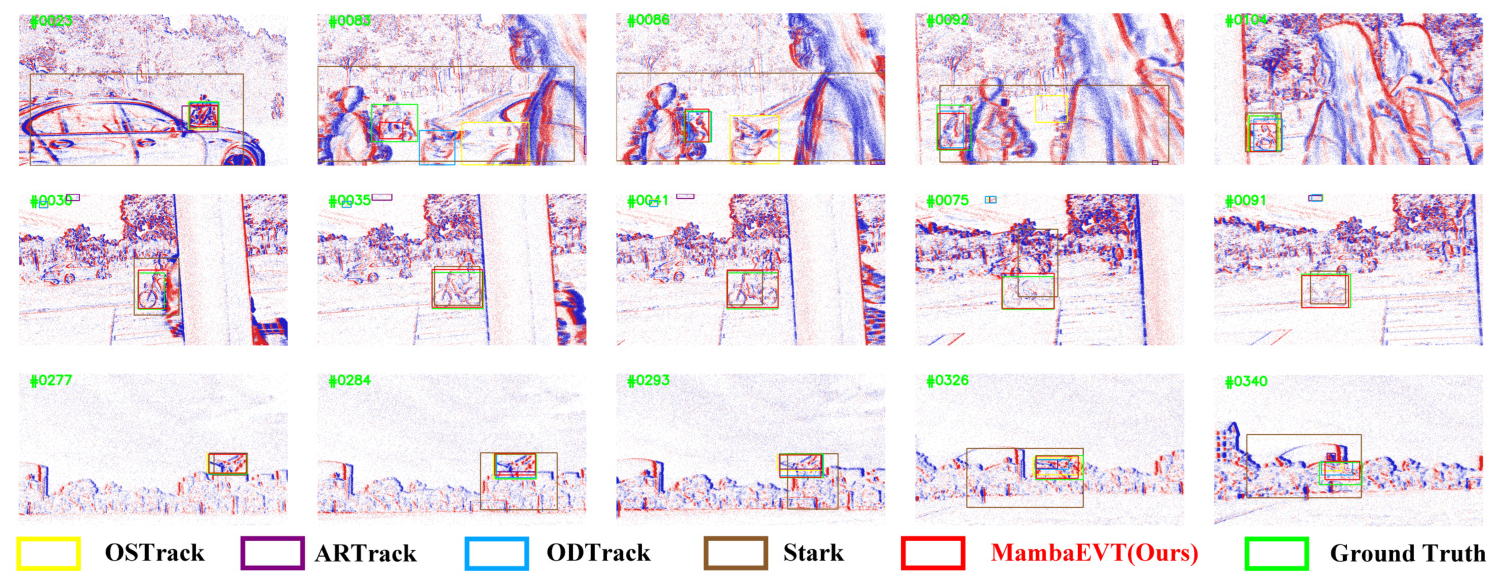
Visual comparisons with other state-of-the-art trackers demonstrated the effectiveness of MambaEVT in various challenging scenarios. The response maps confirmed the tracker’s ability to accurately focus on target objects.
Limitation Analysis
Despite achieving a good balance between performance and parameters, MambaEVT suffers from a relatively low FPS. Further design improvements are needed to enhance tracking speed and fully leverage the Mamba model’s capabilities.
Overall Conclusion
The Mamba-based visual tracking framework introduced in this paper represents a significant advancement in event camera-based tracking systems. By leveraging the state space model with linear complexity and integrating a dynamic template update strategy, MambaEVT achieves a favorable balance between tracking accuracy and computational efficiency. Extensive experiments validated the robustness and effectiveness of the proposed method across multiple large-scale datasets. Future work will focus on improving the running efficiency and reducing energy consumption during the tracking phase. The source code will be released to facilitate further research and development in event camera-based tracking systems.
Code:
https://github.com/event-ahu/mambaevt