

Authors:
Yi Wu、Daryl Chang、Jennifer She、Zhe Zhao、Li Wei、Lukasz Heldt
Paper:
https://arxiv.org/abs/2408.06512
Introduction and Related Work
In the realm of large video recommendation systems, the process typically involves several stages: candidate generation, multitask model scoring, ranking, and re-ranking. The primary focus of this paper is on the ranking stage, where user behavior predictions are combined to optimize long-term user satisfaction. Traditional approaches often rely on heuristic ranking functions optimized through hyperparameter tuning. However, these methods face challenges in scalability and adaptability. The authors propose a novel approach by formulating the problem as a slate optimization problem aimed at maximizing long-term user satisfaction.
Key Contributions
- Modeling User-Slate Interaction: The authors model the user-slate interaction using a cascade click model and propose an algorithm to optimize slate-wise long-term rewards.
- Constrained Optimization Algorithm: A novel constrained optimization algorithm based on dynamic linear scalarization is introduced to ensure stability in multi-objective optimization.
- Deployment on YouTube: The paper details the deployment of the Learned Ranking Function (LRF) on YouTube, along with empirical evaluation results.
Problem Formation
MDP Formulation
The problem of ranking videos is modeled as a Markov Decision Process (MDP) with the following components:
– State Space (S): Represents the user state and a set of candidate videos.
– Action Space (A): All permutations of the candidate videos.
– State Transition Probability (P): Defines the probability of transitioning from one state to another.
– Reward Function (r): Immediate reward vector for taking an action in a given state.
– Discounting Factor (γ): A factor between 0 and 1 that discounts future rewards.
– Policy (π): A mapping from user state to a distribution on actions.
The objective is to maximize the cumulative reward for a primary objective while satisfying constraints on secondary objectives.
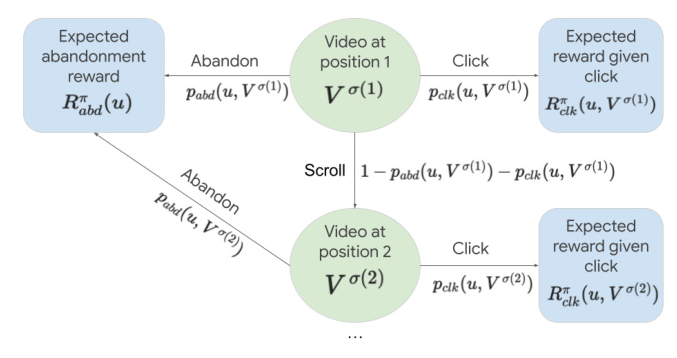
Lift Formulation with Cascade Click Model
The authors factorize the expected cumulative reward into user-item functions and introduce the concept of lift, which is the difference in future rewards associated with a user clicking on an item versus abandoning the slate. The cascade click model is used to describe user interactions with a list of items sequentially.
Optimization Algorithm
Single Objective Optimization
The optimization algorithm employs an on-policy Monte Carlo approach, iteratively applying training and inference steps:
1. Training: Building function approximations for various components using data collected by applying an initial policy.
2. Inference: Modifying the policy to maximize the approximated function, with some exploration.
Constraint Optimization
For multi-objective optimization, linear scalarization is used to reduce the problem to an unconstrained optimization problem. The weights for combining objectives are dynamically updated based on offline evaluation.
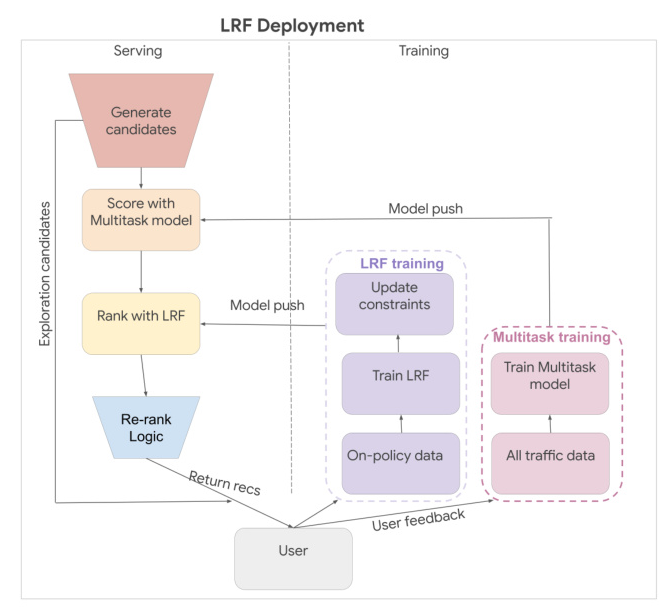
Deployment and Evaluation
Deployment of LRF System
The LRF system was initially launched on YouTube’s Watch Page, followed by the Home and Shorts pages. The system applies an on-policy RL algorithm and is continuously trained with user trajectories from the past few days. The primary reward function is defined as user satisfaction on watches.
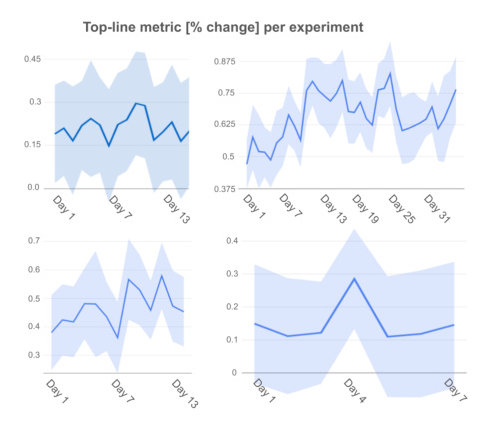
Evaluation
A/B experiments were conducted on YouTube to evaluate the effectiveness of the LRF. The primary objective was to measure long-term cumulative user satisfaction. The experiments showed significant improvements in user satisfaction metrics compared to the previous heuristic ranking system.
[illustration: 9]
Conclusion
The Learned Ranking Function (LRF) system combines short-term user-item behavior predictions to optimize slates for long-term user satisfaction. Future directions include applying more reinforcement learning techniques and incorporating re-ranking algorithms into the LRF system.
This blog post provides an overview of the paper “Learned Ranking Function: From Short-term Behavior Predictions to Long-term User Satisfaction,” detailing the problem formulation, optimization algorithm, deployment, and evaluation of the LRF system. The approach represents a significant advancement in optimizing recommendation systems for long-term user satisfaction.