

Authors:
Jamie Deng、Yusen Wu、Yelena Yesha、Phuong Nguyen
Paper:
https://arxiv.org/abs/2408.09043
Introduction
Venous thromboembolism (VTE), which includes deep vein thrombosis (DVT) and pulmonary embolism (PE), is a significant cardiovascular condition that poses serious health risks if not identified promptly. DVT involves the formation of blood clots in deep veins, typically in the lower extremities, while PE occurs when these clots travel to the lungs, potentially causing life-threatening complications. The timely and accurate identification of VTE is crucial for effective medical intervention, especially in postoperative patients where the risk of VTE can increase significantly.
The widespread adoption of electronic health records (EHRs) in hospitals provides an opportunity to leverage advanced data analytics for VTE classification. Radiology reports, which are rich in textual data, can be analyzed using Natural Language Processing (NLP) techniques to automatically identify VTE cases. This study builds on previous work that utilized deep learning and hybrid models for VTE detection, aiming to address the limitations of complexity and the need for expert feature engineering.
Related Work
Traditional Approaches
Traditional NLP systems for text classification often relied on rule-based methods or statistical machine learning approaches. These methods required significant manual effort for feature selection and large amounts of training data. For instance, Nelson et al. integrated statistical machine learning with rule-based NLP methods to detect postoperative VTE but faced challenges in accurately identifying VTE events from clinical notes.
Deep Learning and Hybrid Methods
Deep learning has shown promise in medical text classification tasks. Previous studies have utilized models like ClinicalBERT and Bi-LSTM for VTE identification. For example, Mulyar et al. explored various architectures for phenotyping using BERT representations of clinical notes, while Olthof et al. found that deep learning-based BERT models outperformed traditional approaches in classifying radiology reports.
Mamba Language Models
Mamba, a State Space Model (SSM) architecture, offers an efficient approach for handling long sequences of text, making it suitable for complex tasks like VTE classification. Grazzi et al. demonstrated that Mamba models could match the performance of Transformer networks in various applications, while Yang et al. leveraged Mamba’s efficiency to handle long sequences of clinical notes.
Research Methodology
SSM Fundamentals
Mamba is based on the State Space Model (SSM) architecture, which is effective for information-rich tasks like language modeling. SSMs use a set of input, output, and state variables to represent a system, evolving over time based on their current values and inputs. Mamba introduces innovations like the Selective Scan Algorithm and Hardware-Aware Algorithm to enhance efficiency and performance.
Classification Model
The Mamba-130M model, with 130 million parameters, serves as the backbone for the classifier. A linear layer is added as the classification head, allowing the model to output predicted labels. The Mamba block, a key component of the architecture, features linear projections, convolutional modes, and Selective SSMs for efficient processing of long text sequences.
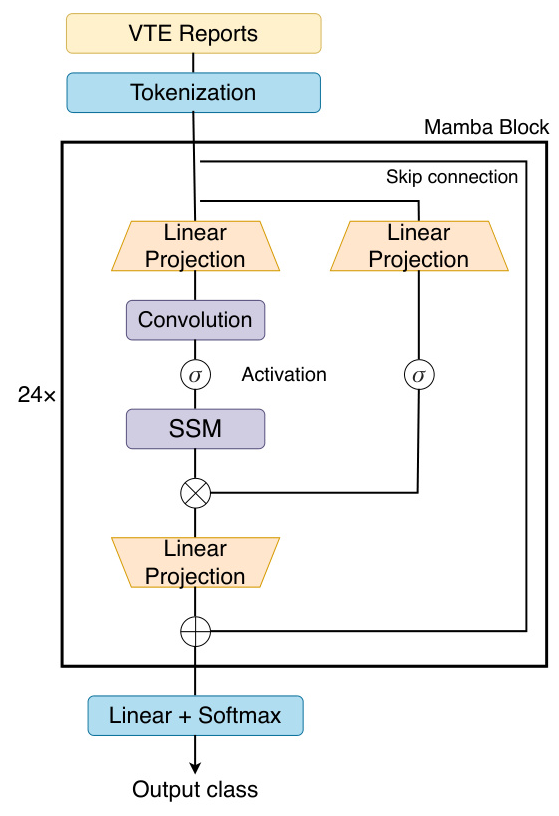
Experimental Design
VTE Datasets
Two datasets from previous work were used for VTE classification: one for DVT and one for PE. The DVT dataset includes 1,000 free-text duplex ultrasound imaging reports, classified into three categories by a radiologist. The PE dataset includes 900 free-text chest CT angiography scan reports, classified into two categories. Both datasets were de-identified and labeled by medical experts.
Experimental Settings
The datasets were divided into training, validation, and test sets. The input texts were truncated to match the input limits of the classifiers. The Mamba model, with a maximum input length of 8,000 tokens, was compared against baseline Transformer-based models (DistilBERT and DeBERTa) and a lightweight LLM (Phi-3 Mini).
Results and Analysis
Model Performance
The Mamba classifier demonstrated superior performance on both datasets, achieving high accuracy and F1 scores. The Phi-3 Mini model also outperformed the BERT models but was computationally intensive due to its larger parameter set.
DVT Dataset
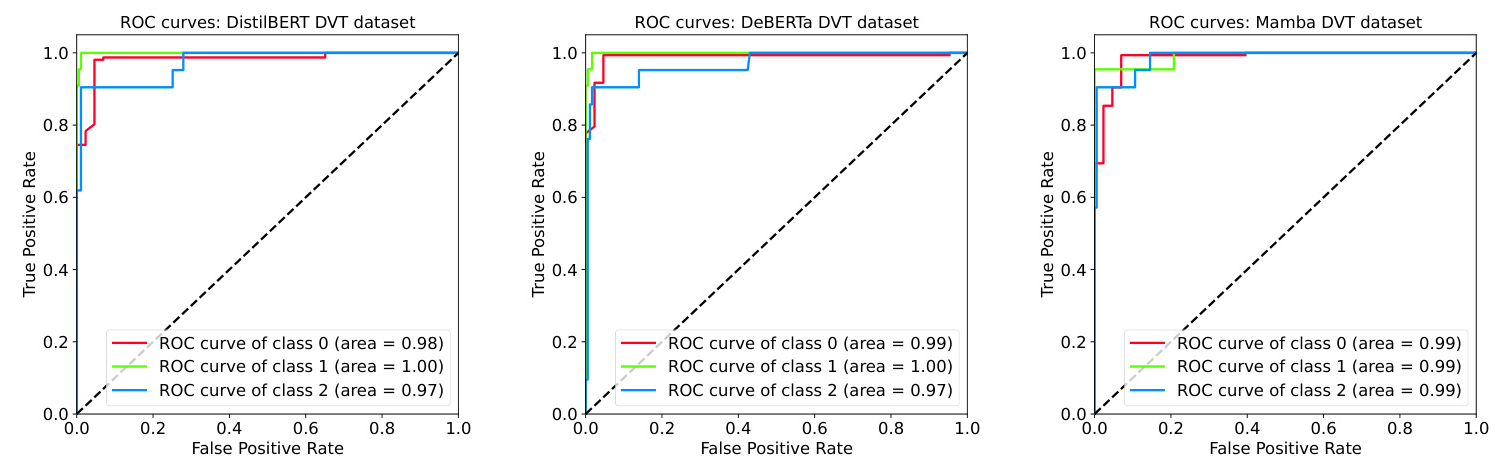
The Mamba model achieved a 97% accuracy and F1 score on the DVT dataset, comparable to the hybrid model from previous work. The ROC curves for the DVT dataset showed balanced results across all classes for the Mamba model.


PE Dataset
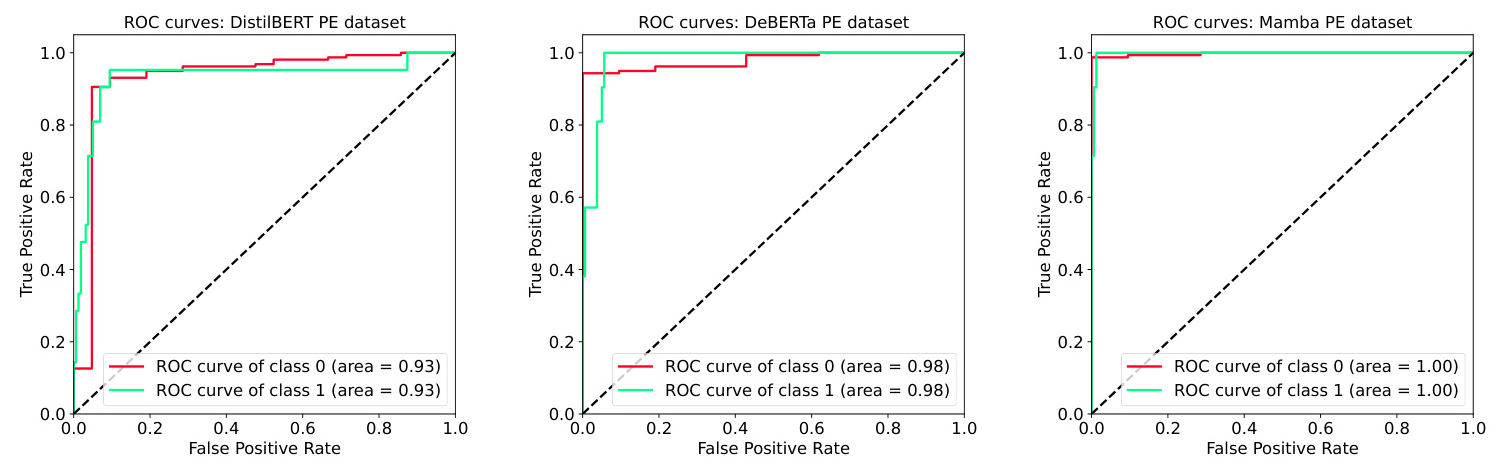
On the PE dataset, the Mamba model outperformed the BERT models, primarily due to its ability to handle longer text sequences. The ROC curves for the PE dataset highlighted the Mamba model’s superior performance.
Overall Conclusion
This study demonstrates the effectiveness of the Mamba architecture-based classifier for VTE identification from radiology reports. The Mamba model achieved impressive results, reducing the need for complex hybrid models and expert-engineered rules. The Phi-3 Mini model, while effective, was less efficient due to its larger parameter set. The findings support the use of Mamba-based models for medical text classification tasks, offering a streamlined and efficient solution for VTE identification.
Future research could focus on optimizing these models for deployment in clinical settings, exploring techniques like model pruning, quantization, and knowledge distillation to enhance efficiency and practicality.