

Authors:
Yusuke Ide、Yuto Nishida、Miyu Oba、Yusuke Sakai、Justin Vasselli、Hidetaka Kamigaito、Taro Watanabe
Paper:
https://arxiv.org/abs/2408.09639
Leveraging Large Language Models for Grammatical Acceptability Judgments
Introduction
The grammatical knowledge of language models (LMs) is often evaluated using benchmarks of linguistic minimal pairs, where models are presented with pairs of acceptable and unacceptable sentences and are required to judge which is acceptable. The dominant approach has been to calculate and compare the probabilities of paired sentences using LMs. However, this method has limitations, and large language models (LLMs) have not been thoroughly examined in this context. This study investigates how to make the most of LLMs’ grammatical knowledge to comprehensively evaluate it. Through extensive experiments with nine judgment methods in English and Chinese, the study demonstrates that certain methods, such as in-template LP and Yes/No probability computing, achieve particularly high performance, surpassing conventional approaches.
Related Work
Acceptability Judgments
Acceptability judgments are used to measure the grammatical knowledge of LMs. There are two main categories of benchmarks: single-sentence binary classification and minimal-pair (MP) benchmarks. MP benchmarks, which present minimally different pairs of sentences and ask which is acceptable, do not require task-specific training and provide a controlled way to generate quality data for model evaluation. Conventional experiments using MP benchmarks typically rely on sentence probability readout methods, which have been dominant across languages.
Previous Studies
Previous studies have shown that sentence probability readout methods generally outperform prompting methods. However, these studies have not thoroughly explored alternative methods or the impact of instruction-tuned models. Additionally, token length has been shown to influence the performance of sentence probability readout methods, with normalized measures like PenLP mitigating some of this bias.
Research Methodology
The study compares three different groups of methods to extract acceptability judgments from LLMs:
Sentence Probability Readout
In this method, each sentence of a given pair is input into a model to obtain the probabilities assigned to each token. The probabilities are then used to compute a probability score for each sentence, and the sentence with the higher score is predicted to be acceptable. The study experiments with three measures to compute the probability scores: LP, MeanLP, and PenLP.
In-template Probability Readout
This method follows the same steps as sentence probability readout but embeds the sentences in a template designed to draw focus to their grammaticality. There are two types of in-template inputs: in-template single and in-template comparative. The study applies each of the three measures (LP, MeanLP, PenLP) to the in-template single method and calculates LP for the in-template comparative input.
Prompting-based Methods
Prompting-based methods provide models with prompts that include a question. The study examines A/B prompting and Yes/No probability computing. In A/B prompting, the model is asked which of the paired sentences is acceptable. In Yes/No probability computing, the score of each sentence is computed as the normalized probability of “Yes” versus “No” given a prompt asking its acceptability.
Experimental Design
Models
The study uses six LLMs, including base models and instruct models that have undergone supervised fine-tuning on an instruction dataset. The models are publicly available on Hugging Face Hub, and 4-bit quantization is performed to compress the models during inference.
Benchmarks
Two MP acceptability judgment benchmarks are used: BLiMP for English and CLiMP for Chinese. BLiMP consists of minimal pairs from 67 different paradigms, while CLiMP consists of 16 paradigms. The benchmarks cover various linguistic phenomena.
Evaluation Metric
The methods are evaluated by accuracy, with random chance accuracy being 50% as the task is a binary classification.
Results and Analysis
Key Findings
- In-template LP and Yes/No probability computing show top performance, surpassing conventional methods.
- These methods have different strengths, with Yes/No probability computing being robust against token-length bias.
- Ensembling the two methods further improves accuracy, revealing their complementary capabilities.
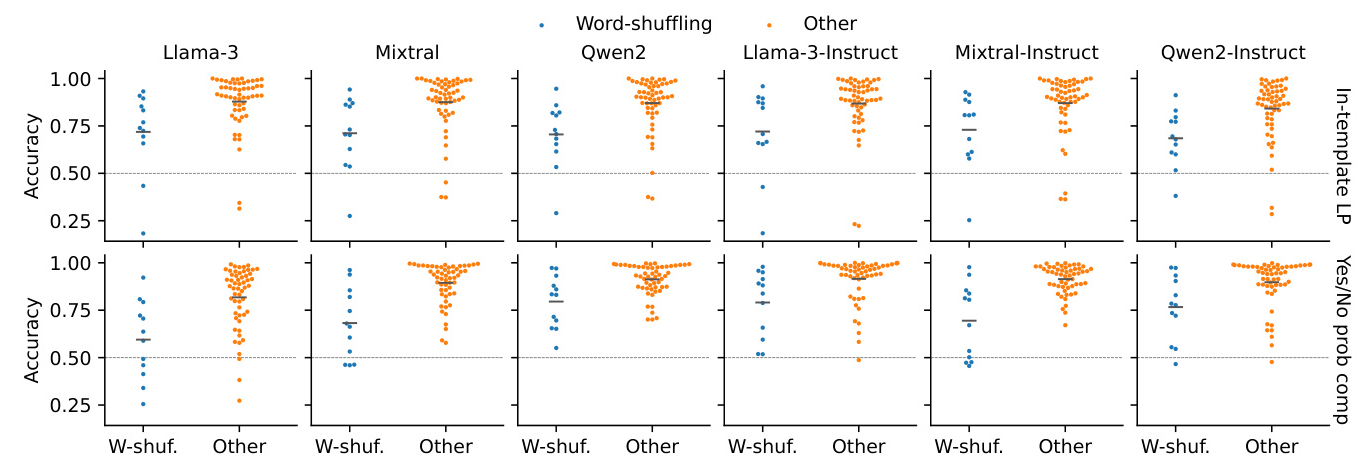
- All LLMs struggle with judgments where the unacceptable sentence can be obtained by shuffling the words in the acceptable one.
Detailed Analysis
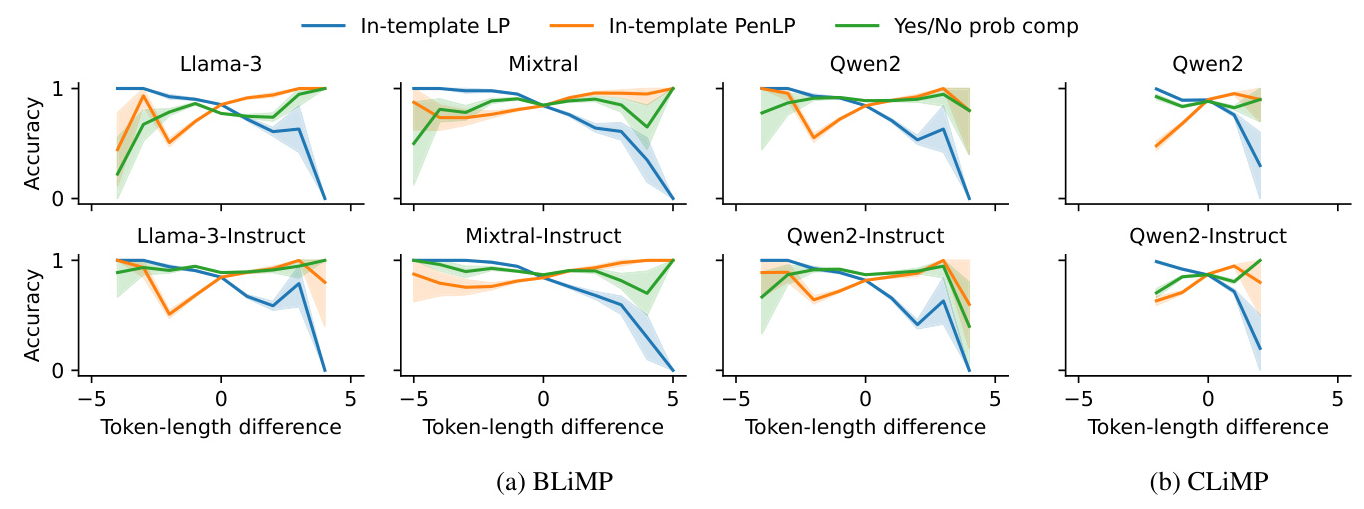
Token-length Bias
Yes/No probability computing is relatively robust against token-length bias, while in-template LP and other readout methods are affected by the token-length difference.
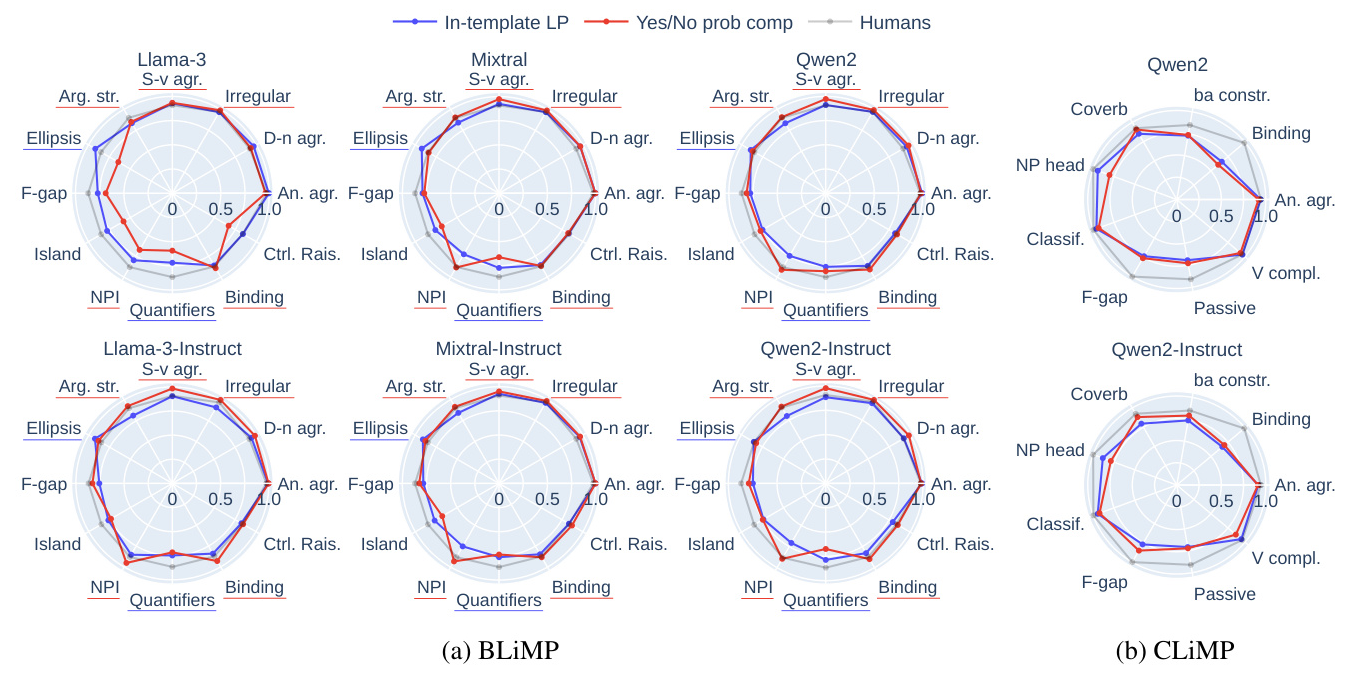
Linguistic Phenomena
In-template LP and Yes/No probability computing excel in different linguistic phenomena, indicating that they harness different aspects of LLMs’ grammatical knowledge.
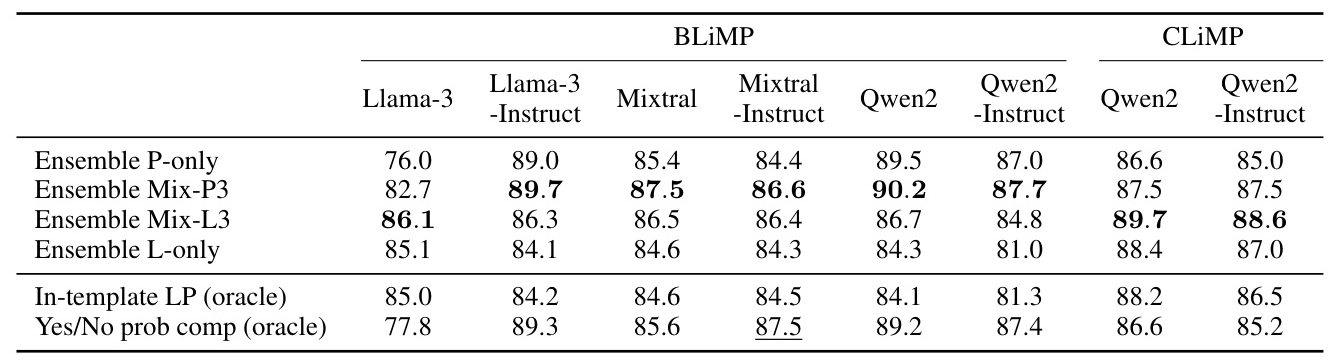
Ensembling Methods
Voting ensembles of in-template LP and Yes/No probability computing yield the best results, surpassing the oracle accuracies of single methods.
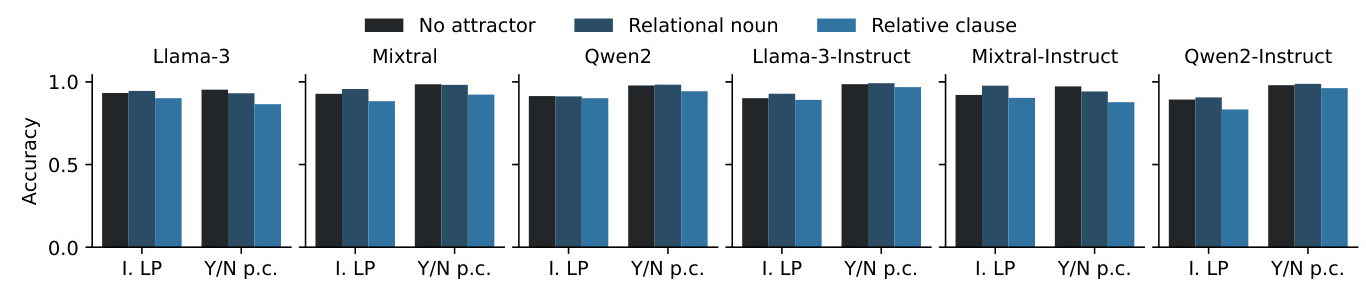
Attractors and Word-shuffling Paradigms
Both methods struggle with attractors in a relative clause and word-shuffling paradigms, which remain challenging for current LLMs.
Overall Conclusion
The study demonstrates that in-template LP and Yes/No probability computing outperform conventional sentence probability readout methods in evaluating LLMs’ grammatical knowledge. These methods excel in different linguistic phenomena, suggesting that they harness different aspects of LLMs’ knowledge. Therefore, diverse judgment methods should be used for a more comprehensive evaluation of LLMs.
Limitations
The study focused on zero-shot settings, and the reasons for the different strengths of in-template LP and Yes/No probability computing remain an open question. Future work could investigate the impact of providing few-shot examples in these methods to further improve accuracy.