

Authors:
Yuhang Zhang、Xiuqi Zheng、Chenyi Liang、Jiani Hu、Weihong Deng
Paper:
https://arxiv.org/abs/2408.10614
Generalizable Facial Expression Recognition: A Comprehensive Overview
Facial expression recognition (FER) is a crucial aspect of human-computer interaction, enabling machines to understand human emotions. However, current state-of-the-art (SOTA) FER methods often fail when applied to test sets with domain gaps from the training set. This blog delves into a novel approach to enhance the zero-shot generalization ability of FER methods, ensuring robust performance across diverse, unseen test sets.
1. Introduction
Background and Problem Statement
Facial expression recognition (FER) is essential for applications in human-computer interaction, security, and healthcare. Despite significant advancements in deep learning, existing FER methods struggle with generalization across different domains. When trained on a specific dataset, these models often perform poorly on unseen test sets with domain gaps. This limitation hinders the real-world deployment of FER systems, where the distribution of test samples is unknown and diverse.
Objective
The primary goal of this study is to improve the zero-shot generalization ability of FER methods using only one training set. Inspired by human cognition, the proposed method aims to extract expression-related features from face images, leveraging generalizable face features from large models like CLIP. The approach involves learning sigmoid masks on fixed face features to enhance generalization and reduce overfitting.
2. Related Work
Facial Expression Recognition
Extensive research has been conducted to enhance FER performance. Traditional methods often rely on crowd-sourcing, model ensembling, and loss variants to improve intra-class similarity and inter-class separation. However, these methods typically assume no domain gap between training and test sets, leading to significant performance drops when applied to domain-different test sets.
Domain Generalization
Domain Generalization (DG) aims to improve model performance on unseen target domains by reducing feature discrepancies among multiple source domains or augmenting training data. However, existing DG methods in FER often require access to labeled or unlabeled target samples for fine-tuning, which is impractical for real-world deployment. This study focuses on enhancing FER generalization without accessing target domain samples.
3. Research Methodology
Problem Definition
The study aims to train an FER model on a single training set and evaluate its performance on various unseen test sets with domain gaps. The model should generalize well to real-world test sets, where the distribution of target domains is unknown. The proposed method involves learning masks on fixed face features to selectively extract expression-related features, inspired by human cognition.
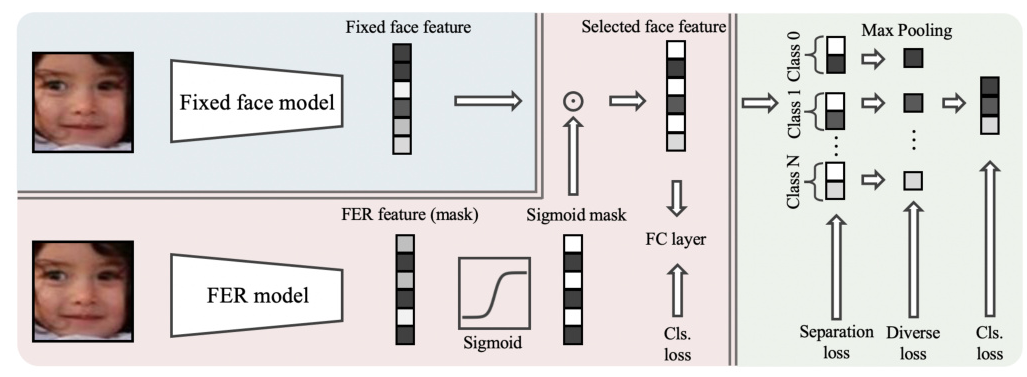
Proposed Method: CAFE
The Cognition of humAn for Facial Expression (CAFE) method mimics human perception by first extracting face features and then focusing on expression-related features. The framework involves:
- Fixed Face Features: Extracting generalizable face features using pre-trained models like CLIP.
- Sigmoid Mask Learning: Training an FER model to learn masks on fixed face features, regularized by a sigmoid function to prevent overfitting.
- Channel Separation and Diverse Loss: Separating masked features into pieces corresponding to expression classes and introducing a channel-diverse loss to enhance generalization.
4. Experimental Design
Datasets
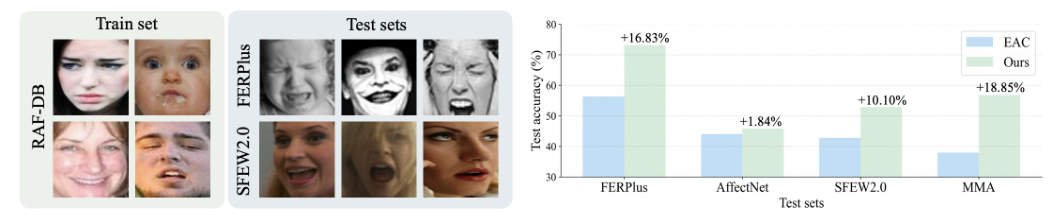
The study utilizes five FER datasets: RAF-DB, FERPlus, AffectNet, SFEW2.0, and MMA. Each dataset contains images annotated with seven basic expressions, providing a diverse set of training and test samples.
Implementation Details
The experiments use ResNet-18 as the backbone, with the ViT-B/32 CLIP model for face feature extraction. The learning rate is set to 0.0002, and the Adam optimizer is used with a weight decay of 0.0001. The weights for the channel-wise loss and diverse loss are set to 1.5 and 5, respectively.
5. Results and Analysis
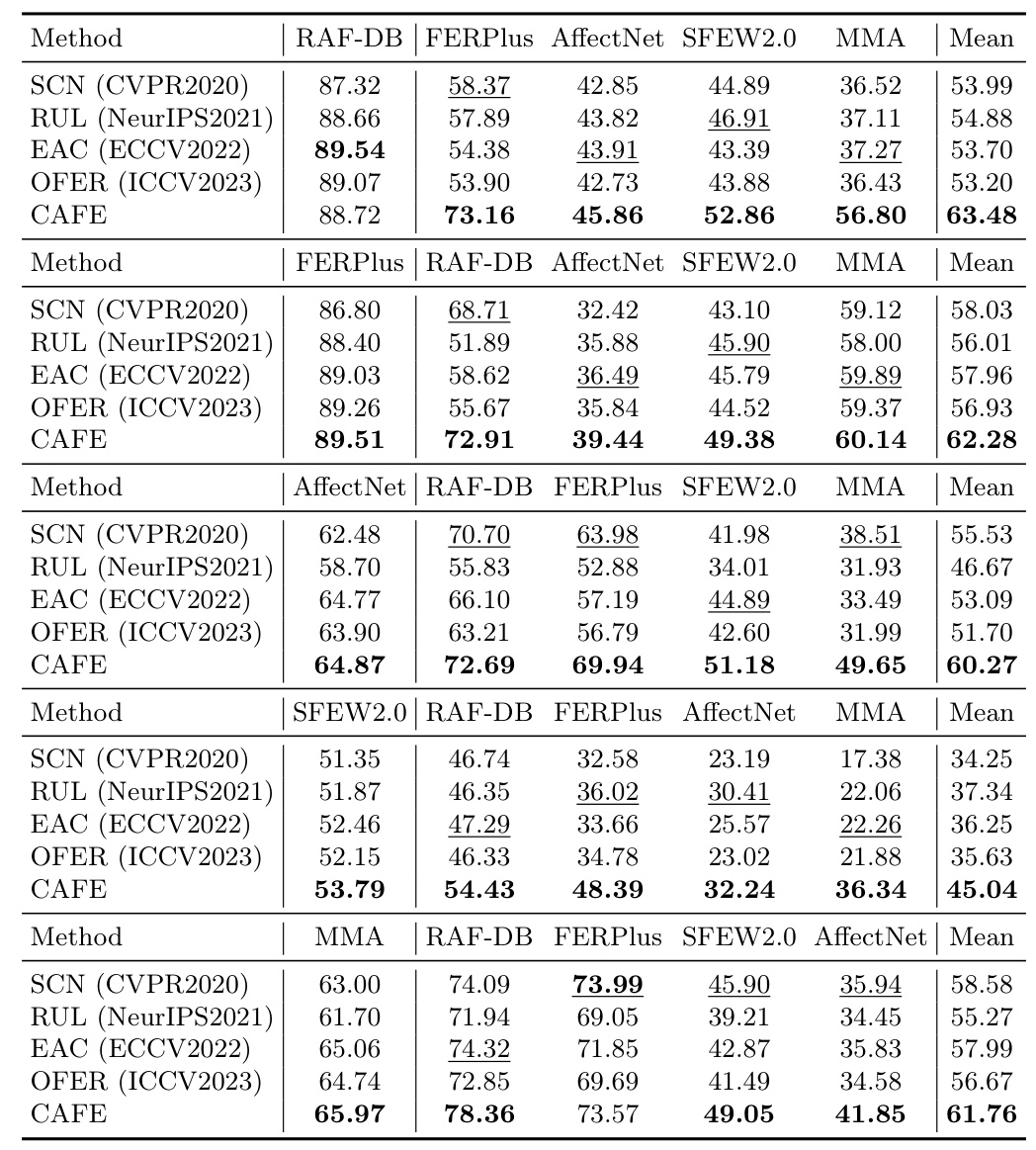
Main Experiments
The proposed method is evaluated by training on one FER dataset and testing on all five datasets. The results demonstrate that the method significantly outperforms SOTA FER methods on unseen test sets, highlighting its superior generalization ability.
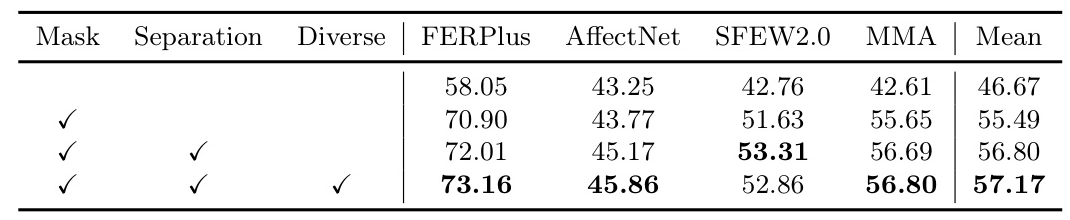
Ablation Study
An ablation study is conducted to assess the effectiveness of each module in the proposed method. The results show that the sigmoid mask learning, channel separation, and diverse loss modules each contribute to the overall performance improvement.
Comparison with CLIP+Finetune
The proposed method is compared with a baseline that fine-tunes a fully connected layer on concatenated features from a fixed CLIP model. The results confirm that the designed method effectively leverages CLIP’s generalization potential for FER.

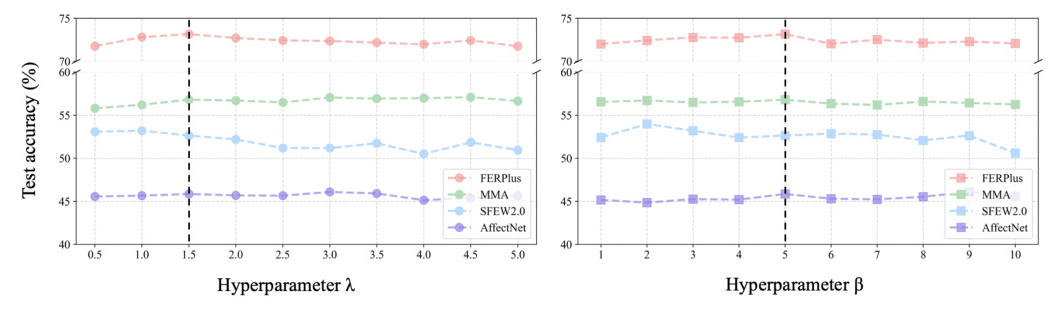
Hyperparameter Study
The influence of hyperparameters on the method’s performance is analyzed, showing that the method is robust to a wide range of values for the separation loss weight (λ) and diverse loss weight (β).
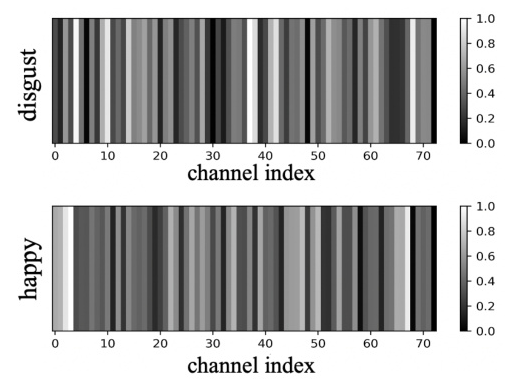
Visualization Results
GradCAM visualizations of FERPlus test samples by models trained on RAF-DB reveal that the proposed method focuses on the whole face and learns better expression-related features compared to existing methods.
6. Overall Conclusion
This study presents a novel method to enhance the zero-shot generalization ability of FER methods using only one training set. By learning sigmoid masks on fixed face features and introducing channel-separation and channel-diverse modules, the proposed method achieves superior performance on unseen test sets. Extensive experiments validate the effectiveness of the approach, making it a promising solution for real-world FER deployment.
The proposed method, CAFE, not only improves FER accuracy but also ensures robust performance across diverse domains, addressing a critical challenge in facial expression recognition.
For more details and access to the code, visit the GitHub repository.
Code:
https://github.com/zyh-uaiaaaa/generalizable-fer