

Authors:
Kun Li、Xiantao Cai、Jia Wu、Bo Du、Wenbin Hu
Paper:
https://arxiv.org/abs/2408.09106
Fragment-Masked Molecular Optimization: A Detailed Interpretive Blog
Introduction
Background
Molecular optimization is a pivotal process in drug discovery, focusing on refining molecular structures to enhance drug efficacy and minimize side effects. Traditional methods of molecular optimization often rely on understanding specific drug target structures, which can be limiting due to the scarcity of available targets and the difficulty in capturing clear structures. This has led to the exploration of phenotypic drug discovery (PDD), which does not depend on well-defined target structures and can identify hits with novel polypharmacology signatures.
Problem Statement
Despite the advancements in target-based molecular optimization, challenges remain in innovative drug development due to the limited number of available targets and the difficulty in capturing clear structures. PDD offers a promising alternative by focusing on the phenotypic effects of molecules within biological systems. However, there is a lack of molecular optimization methods specifically designed for PDD. This study proposes a novel fragment-masked molecular optimization method (FMOP) to address this gap.
Related Work
Existing Molecular Optimization Methods
Molecular optimization aims to improve drug properties, including physicochemical and biomedical attributes. Existing methods can be broadly categorized into rule-based and deep learning-based methods. Rule-based methods rely on predefined structural rules, while deep learning-based methods, such as those utilizing denoising diffusion probabilistic models (DDPM), have shown great potential in molecular optimization.
Limitations of Current Techniques
Current molecular optimization techniques often fail to meet the requirements of PDD. They typically focus on optimizing physicochemical properties or target affinities, disregarding the complexity of cellular environments. Additionally, these methods often struggle with complex masking scenarios due to limited training data, restricting their applicability in PDD.
Research Methodology
Problem Formulation
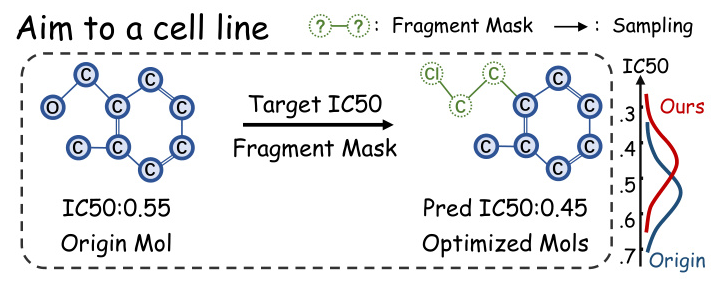
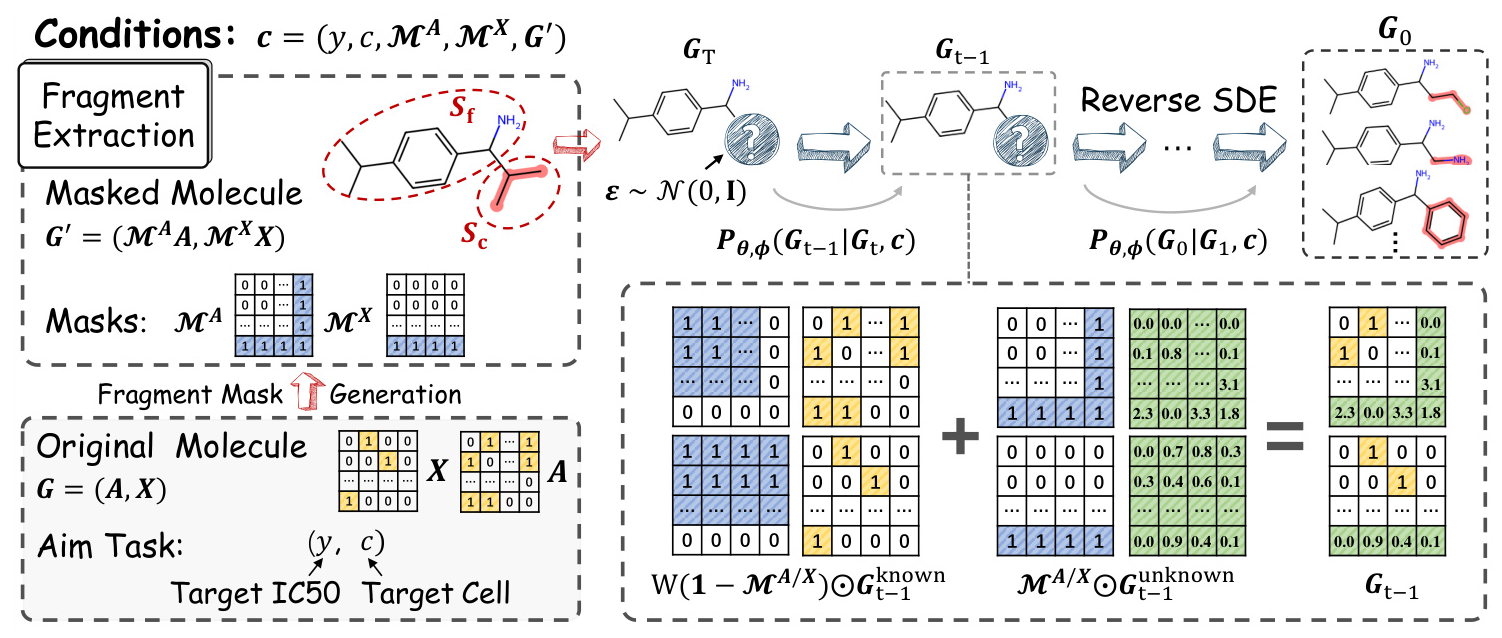
The goal of molecular optimization in the context of PDD is to enhance a molecule’s efficacy in a specific cell line, denoted by its IC50 value. The proposed FMOP method decomposes a molecule into a scaffold and side chains, with a mask marking the side chain’s fragment structure. The optimization process aims to generate new molecules with similar scaffolds but improved IC50 values.
Overview of FMOP
FMOP employs a regressor-free conditional diffusion method to optimize the masked regions of molecules. The method integrates specific conditions about the cell line and IC50 into the scoring estimation to guide the diffusion model. The molecule is split into its scaffold and side chain to generate fragment masks, which are then used to constrain the sampling process during optimization.
Experimental Design
Datasets
The study utilized two primary datasets: QM9 and GDSCv2. The QM9 dataset, containing approximately 133,885 molecules, was used for pre-training the model to enhance molecular diversity. The GDSCv2 dataset, comprising approximately 190,853 samples covering 945 cell lines and 220 drugs, was used for tasks related to drug response prediction.
Evaluation Criteria
The evaluation focused on molecules labeled with drug response for specific cell lines from the GDSCv2 dataset. The success of optimization was measured by the improvement in IC50 values before and after optimization. The efficacy of the optimized molecules was predicted using out-of-domain drug response prediction (OOD-DRP) methods due to the impracticality of wet lab validation for all generated molecules.
Results and Analysis
Overall Experiments
The FMOP method was compared with five baseline models: GDSS, DiGress, DruM2D, MOOD, and CDGS. The results demonstrated that FMOP achieved the best optimization and increase rate results, surpassing the second-best method by 36.0% and 76.7%, respectively. The visual comparison of results showed that FMOP maintained scaffold consistency while optimizing the masked region, unlike other methods that generated random molecules with good efficacy.
Ablation Study
The ablation study explored the impact of different components on the model’s performance. The results indicated that the fragment mask, task guidance, and rule-based chemical bond post-processing significantly contributed to the model’s overall performance. The absence of any of these components led to a drastic decline in success rates and efficacy improvements.
Visualization Analysis
The visual analysis of molecular structures generated by FMOP and baseline methods across different cell lines showed that FMOP consistently produced unique molecules tailored to each cell line. The predicted IC50 values for FMOP-generated molecules remained consistently low across different cell lines, indicating a competitive advantage over de novo designed molecules.
Overall Conclusion
The FMOP method addresses the challenge of generating molecules for PDD by employing a regression-free diffusion model to conditionally sample the masked regions of molecules for optimization. The method effectively generates new molecules with similar scaffolds and improved efficacy. The overall experiments demonstrated a high in-silico optimization success rate of 94.4% and an average efficacy increase of 5.3%. Extensive ablation studies and visualization experiments confirmed that FMOP is an effective and robust molecular optimization method with broad application prospects in PDD.

In conclusion, FMOP represents a significant advancement in molecular optimization for PDD, offering a scalable and automated solution to enhance drug discovery processes. The method’s ability to generate effective and diverse molecules tailored to specific cell lines highlights its potential to accelerate the development of new drugs for complex diseases.