

Authors:
Alejandro Carrasco、Victor Rodriguez-Fernandez、Richard Linares
Paper:
https://arxiv.org/abs/2408.08676
Introduction
Large Language Models (LLMs) have revolutionized artificial intelligence, expanding their applications beyond text generation to becoming autonomous agents capable of making decisions based on contextual information. This study explores the use of fine-tuned LLMs for autonomous spacecraft control within the Kerbal Space Program Differential Games suite (KSPDG). Traditional Reinforcement Learning (RL) approaches face limitations in this domain due to insufficient simulation capabilities and data. By leveraging LLMs, specifically fine-tuning models like GPT-3.5 and LLaMA, this research demonstrates how these models can effectively control spacecraft using language-based inputs and outputs.
Background
Limitations of Reinforcement Learning in Space Applications
The space domain lacks publicly available simulation environments crucial for training AI agents in complex space operations. Allen et al. introduced SpaceGym, a set of non-cooperative game environments intended to spur development and act as proving grounds for autonomous and AI decision-makers in the orbital domain. Among these environments, the Kerbal Space Program Differential Games suite (KSPDG) is notable. However, KSPDG is unsuitable for RL training due to the KSP engine’s limitations and the creators’ focus on evaluation rather than training.
Leveraging LLMs for Autonomous Spacecraft Control
To overcome RL limitations, this study proposes using LLM-based agents to develop an “intelligent” operator that controls a spacecraft based on real-time telemetry, using language exclusively as the input and output of the system. The classic RL loop is redesigned by interfacing the KSPDG simulation environment with an LLM, transforming real-time observations into textual prompts processed by the LLM, which then generates control actions.
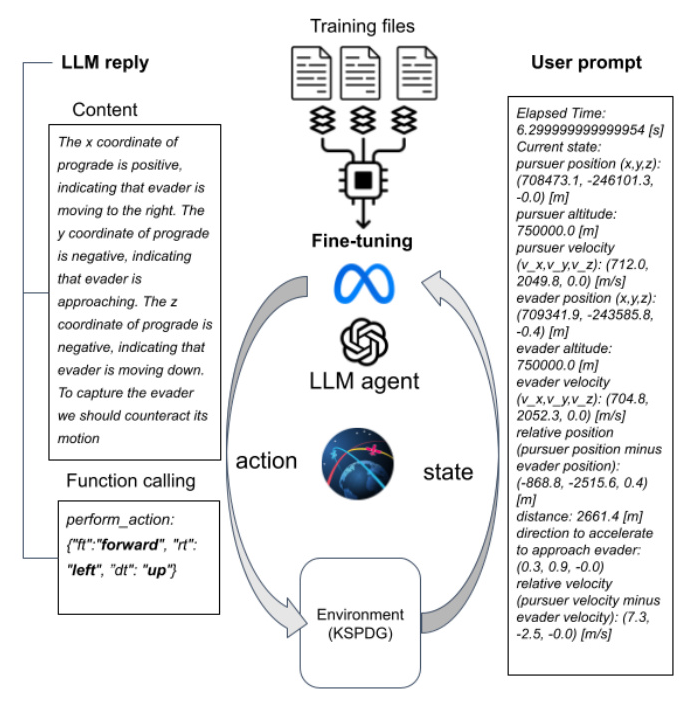
Methodology
Data Generation Process
The primary challenge in fine-tuning a model for KSPDG is the unavailability of varied mission scenarios and the lack of expert gameplay logs. To address this, a program and a bot were developed to generate pairs of randomized orbits for the pursuer and evader problem. The bot tracks the KSP navball’s information and aligns the vessel to its prograde, generating logs that are converted into text suitable for LLM processing.
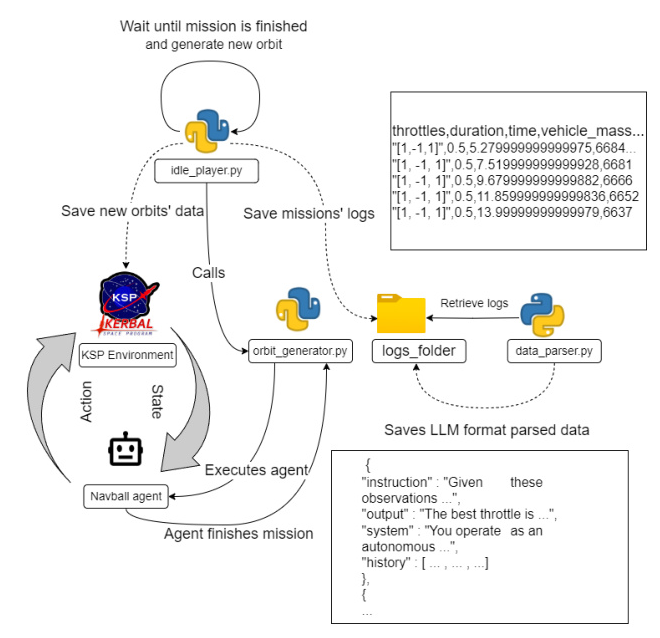
Fine-tuning Process
The study transitioned to an open-source model, LLaMA, for its flexibility and adaptability. Fine-tuning was conducted using a single workstation equipped with five RTX 4090 GPUs, employing several optimization techniques:
- Low-Rank Adaptation (LoRA): Reduces the number of trainable parameters by factorizing weight updates into low-rank matrices.
- Hugging Face Transformers Library: Facilitates the management of model architecture and training processes.
- Quantization: Reduces model size and enhances inference speed by converting weights and activations to lower precision.
- LLaMA Factory: Streamlines the fine-tuning process by efficiently managing datasets, pre-processing, and training tasks.
Training hyperparameters included a batch size of 2, a learning rate of 1e-4, a cosine learning rate scheduler, 3 epochs, and a LoRA configuration. The LLaMA dataset consisted of 50 top-performing randomly generated orbit missions, chosen for their optimal distance and approach speed.
Results
The results of fine-tuned GPT models using human gameplays and LLaMA models using navball agent gameplays are presented in Table 1. GPT models showed gradual improvement, surpassing the baseline after two training gameplays. LLaMA models consistently exceeded their baseline performance, with the best models performing exceptionally well, demonstrating the potential benefits of larger datasets.
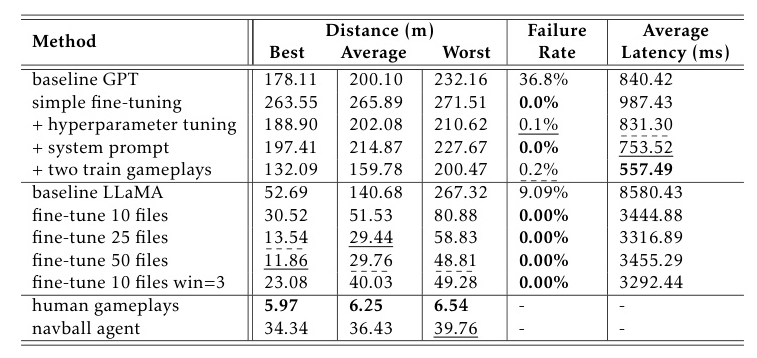
Performance Comparison
The fine-tuning trajectories indicate that the data ingested by the model aids in understanding the problem and determining appropriate actions. However, the model’s prior knowledge and reasoning still influence its performance. For instance, an incorrect hint can deteriorate the model’s performance, while an “agnostic” prompt can surpass the dataset results.
Discussion
The preliminary results demonstrate that LLMs possess the capability to perform technical tasks beyond generating verbose text. Fine-tuning these models enhances their reasoning for autonomous space control missions, yielding a generalized model that can interact as an agent in KSP rendezvous missions. The fine-tuned LLaMA model surpasses the navball agent results, even in average distance, highlighting the generalization capacity LLMs offer.
Future work will focus on more complex and dynamic scenarios requiring additional metrics. The close distances achieved by the LLaMA models pave the way for exploring docking operations, where increased complexity will test the robustness of the model’s chosen trajectories. Additionally, leveraging multi-modal LLMs, such as GPT-4o and the Phi-3 family, will be explored to create an agent with human-like decisions by utilizing vision capabilities in conjunction with language.
Conclusion
This study demonstrates the potential of fine-tuned LLMs for autonomous spacecraft control, using the Kerbal Space Program Differential Games suite as a testing environment. By leveraging LLMs, the limitations of traditional RL approaches can be overcome, paving the way for more advanced and flexible AI agents in space operations. The results highlight the promise of LLMs in performing technical tasks and open new avenues for future research in autonomous space control.
For more details, the code is available at this URL: https://github.com/ARCLab-MIT/kspdg.