

Authors:
Xingbo Fu、Zihan Chen、Binchi Zhang、Chen Chen、Jundong Li
Paper:
https://arxiv.org/abs/2408.09393
Federated Graph Learning with Structure Proxy Alignment: An In-Depth Analysis
Introduction
Graph Neural Networks (GNNs) have emerged as a powerful tool for learning from graph-structured data, enabling applications such as node classification and link prediction. However, traditional GNNs are typically trained in a centralized manner, which poses significant challenges in scenarios where data is distributed across multiple owners due to privacy concerns and commercial competition. Federated Learning (FL) offers a solution by allowing multiple data owners to collaboratively train models without sharing their private data. Federated Graph Learning (FGL) extends FL to graph data, but it faces unique challenges, particularly the issue of data heterogeneity and biased neighboring information for minority nodes. This paper introduces FedSpray, a novel FGL framework designed to address these challenges by learning and aligning structure proxies to provide unbiased neighboring information for node classification tasks.
Related Work
Federated Learning
Federated Learning (FL) has gained traction across various domains, including computer vision, healthcare, and social recommendation. The primary challenge in FL is data heterogeneity, where data samples are not independent and identically distributed (non-IID) across clients. Several approaches have been proposed to mitigate this issue, such as FedProx, which adds a proximal term to the local training loss, and Moon, which uses a contrastive loss to increase the distance between the current and previous local models. Personalized FL methods, like pFedHN and APFL, aim to learn customized models for each client while benefiting from collaborative training.
Federated Graph Learning
Federated Graph Learning (FGL) extends FL to graph data, addressing the data isolation issue. Recent studies have focused on various downstream tasks, such as node classification, knowledge graph completion, and graph classification. However, FGL faces the additional challenge of entangled node attributes and graph structures, exacerbating the data heterogeneity issue. Approaches like GCFL and FedStar have been proposed to handle this, but they do not fully address the divergent impact of neighboring information across clients for node classification.
Research Methodology
Problem Formulation
The primary challenge in FGL is the high heterophily of minority nodes, where neighbors are mostly from other classes, leading to biased node embeddings. FedSpray aims to learn personalized GNN models for each client while mitigating the impact of adverse neighboring information. The framework introduces global class-wise structure proxies to provide unbiased neighboring information and employs a global feature-structure encoder to generate reliable soft targets for nodes.
Algorithmic Design
FedSpray consists of personalized GNN models and a global feature-structure encoder. The GNN models follow the message-passing mechanism, aggregating information from neighbors to compute node embeddings. The feature-structure encoder generates soft targets using node features and structure proxies, which are then used to regularize local training of GNN models via knowledge distillation.
Experimental Design
Datasets and Baselines
The experiments are conducted on four real-world datasets: PubMed, WikiCS, Coauthor Physics, and Flickr. The distributed graph data is synthesized by splitting each dataset into multiple communities. FedSpray is compared with six baselines, including Local, FedAvg, APFL, GCFL, FedStar, and FedLit.
Hyperparameter Settings
Three representative GNN architectures are used as backbone models: GCN, SGC, and GraphSAGE. Each GNN model includes two layers with a hidden size of 64. The feature-structure encoder is implemented with one layer, and the size of feature embeddings and structure proxies is set to 64. The experiments run for 300 rounds with a local epoch set to 5.
Results and Analysis
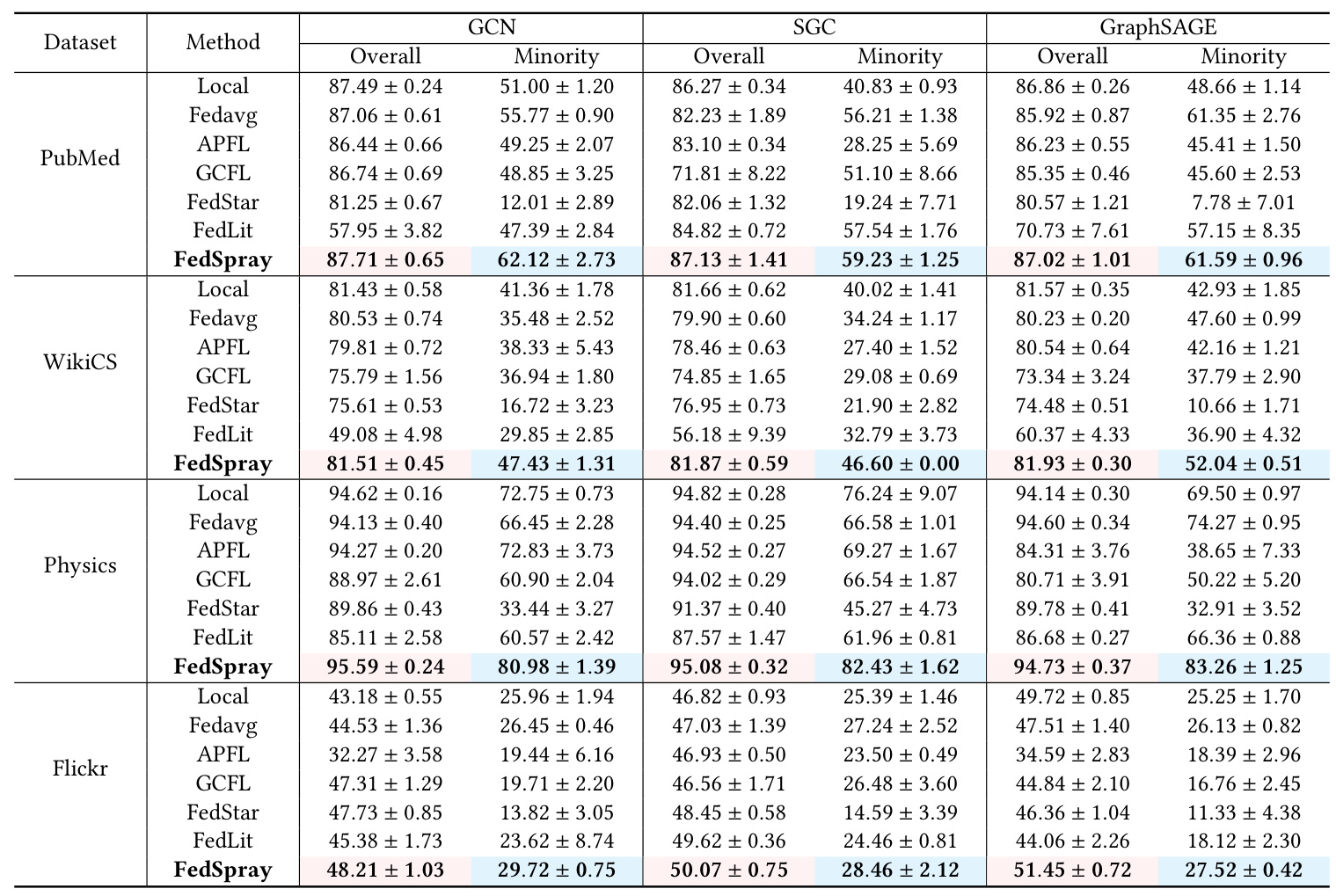
Overall Performance
FedSpray consistently outperforms all baselines on node classification accuracy for both overall test nodes and minority nodes across clients. The results demonstrate that FedSpray effectively mitigates the impact of adverse neighboring information, particularly for minority nodes.
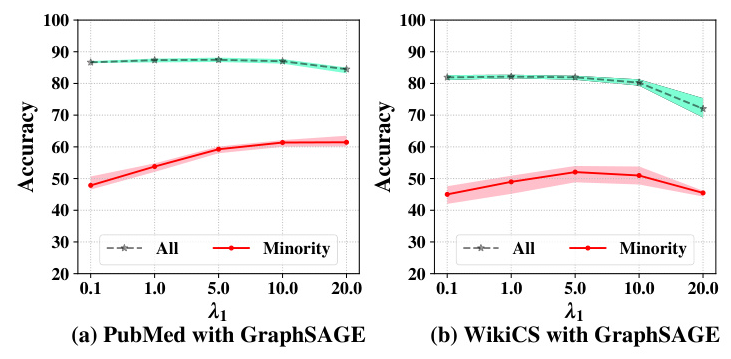
Influence of Hyperparameters
The sensitivity analysis on the hyperparameter 𝜆1 shows that the accuracy on all nodes remains high when 𝜆1 is relatively small. However, the accuracy of minority nodes decreases when 𝜆1 is too small, indicating insufficient regularization. When 𝜆1 is too large, the overall accuracy decreases, suggesting that the regularization term outweighs the label information.
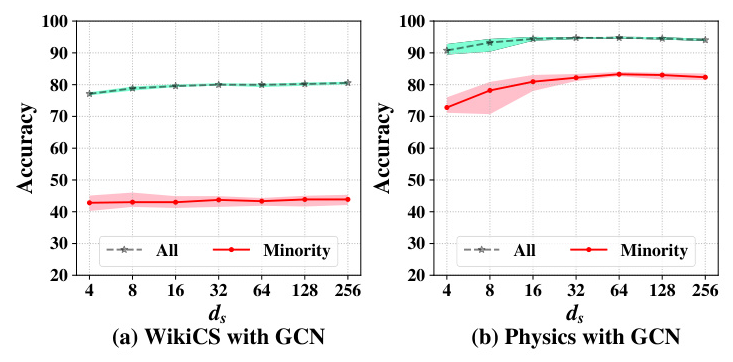
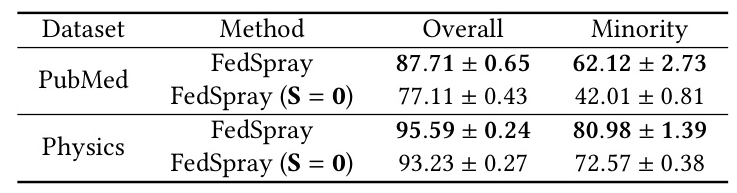
Effectiveness of Structure Proxies
The experiments validate the effectiveness of structure proxies in FedSpray. Removing structure proxies results in significant performance degradation, highlighting their importance in providing unbiased neighboring information for node classification.
Overall Conclusion
FedSpray addresses the unique challenges of Federated Graph Learning by introducing global class-wise structure proxies and a feature-structure encoder. The framework effectively mitigates the impact of adverse neighboring information, particularly for minority nodes, and consistently outperforms state-of-the-art baselines. The experimental results validate the superiority of FedSpray, making it a promising approach for collaborative training of GNN models in a federated setting.
In summary, FedSpray represents a significant advancement in Federated Graph Learning, offering a robust solution to the challenges of data heterogeneity and biased neighboring information. The framework’s ability to learn personalized GNN models while preserving data privacy makes it a valuable tool for various applications, from social recommendation to financial fraud detection.