

Authors:
Eashan Adhikarla、Kai Zhang、John Nicholson、Brian D. Davison
Paper:
https://arxiv.org/abs/2408.09650
Introduction
Low-light image enhancement is a critical task in computer vision, with applications ranging from consumer gadgets like phone cameras to sophisticated surveillance systems. Traditional techniques often struggle to balance processing speed and high-quality results, especially with high-resolution images. This leads to issues like noise and color distortion in scenarios requiring quick processing, such as mobile photography and real-time video streaming.
Recent advancements in foundation models, such as transformers and diffusion models, have shown promise in various domains, including low-light image enhancement. However, these models are often limited by their computational complexity and slow inference times, making them unsuitable for real-time use on edge devices with limited processing power and battery constraints.
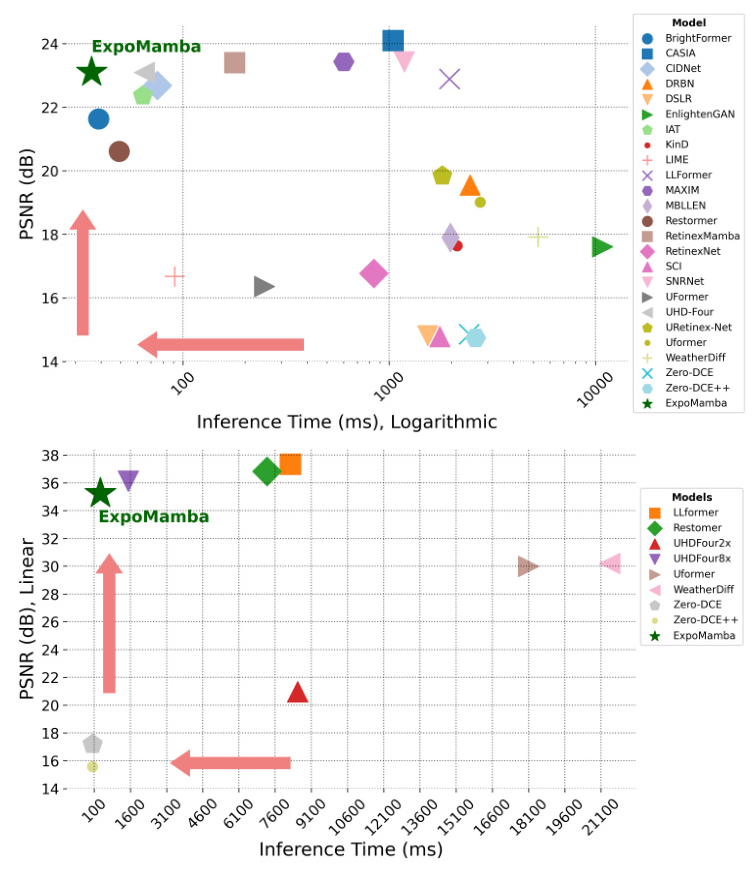
To address these challenges, we introduce ExpoMamba, a novel architecture that integrates components of the frequency state space within a modified U-Net. This model is specifically optimized to handle mixed exposure challenges—a common issue in low-light image enhancement—while ensuring computational efficiency. Our experiments demonstrate that ExpoMamba enhances low-light images up to 2-3 times faster than traditional models, with an inference time of 36.6 ms and a PSNR improvement of approximately 15-20% over competing models.
Related Work
Limitations of Current Approaches
Foundation models have revolutionized computer vision, including low-light image enhancement, by introducing advanced architectures that model complex relationships within image data. Transformer-based and diffusion-based low-light techniques have made significant strides. However, the sampling process requires a computationally intensive iterative procedure, and the quadratic runtime of self-attention in transformers makes them unsuitable for real-time use on edge devices.
Innovations such as linear attention, self-attention approximation, windowing, striding, attention score sparsification, hashing, and self-attention operation kernelization have aimed to address these complexities. However, these often come at the cost of increased computation errors compared to simple self-attention.
Purpose
With the rising need for better images, advanced small camera sensors in edge devices have made it more common for customers to capture high-quality images and use them in real-time applications like mobile, laptop, and tablet cameras. However, they all struggle with non-ideal and low lighting conditions in the real world. Our goal is to develop an approach that has high image quality for enhancement but also at high speed.
Contributions
Our contributions are summarized as follows:
– We introduce the use of Mamba for efficient low-light image enhancement (LLIE), specifically focusing on mixed exposure challenges.
– We propose a novel Frequency State Space Block (FSSB) that combines two distinct 2D-Mamba blocks, enabling the model to capture and enhance subtle textural details often lost in low-light images.
– We describe a novel dynamic batch training scheme to improve the robustness of multi-resolution inference in our proposed model.
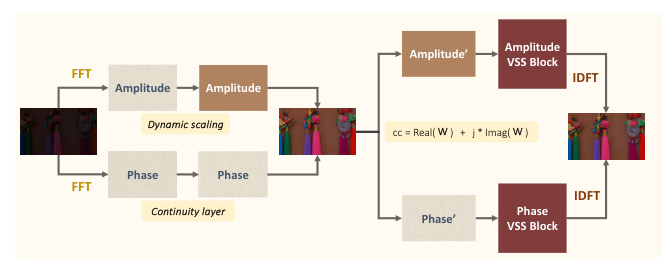
– We implement dynamic processing of the amplitude component to highlight distortion (noise, illumination) and the phase component for image smoothing and noise reduction.
Research Methodology
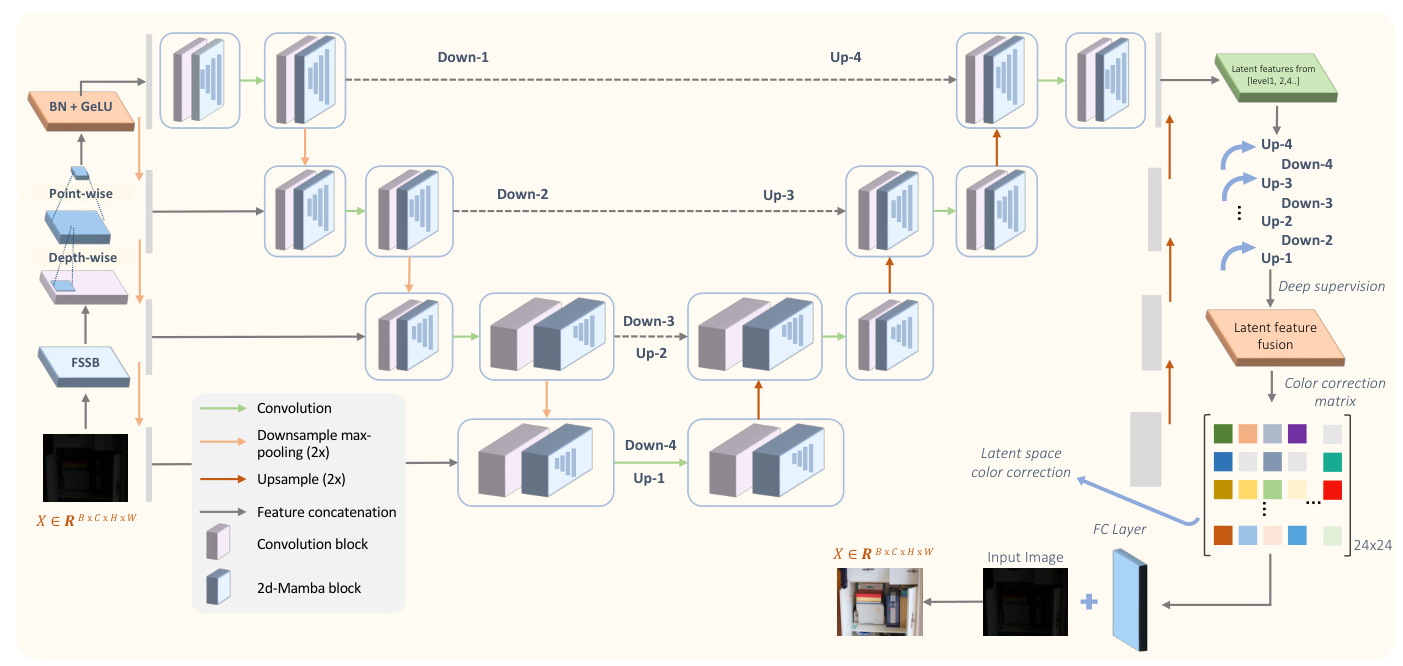
ExpoMamba Architecture
ExpoMamba combines frequency state-space blocks with spatial convolutional blocks. This combination leverages the advantages of frequency domain analysis to manipulate features at different scales and frequencies, crucial for isolating and enhancing patterns challenging to detect in the spatial domain, like subtle textural details in low-light images or managing noise in overexposed areas.
Our proposed architecture utilizes a 2D scanning approach to tackle mixed-exposure challenges in low-light conditions. This model incorporates a combination of U-Net and M-Net, supporting 2D sRGB images with each block performing operations using a convolutional and encoder-style SSM.
Frequency State Space Block (FSSB)
The FSSB addresses the computational inefficiencies of transformer architectures, especially when processing high-resolution images or long-sequence data. The FSSB initiates its processing by transforming the input image into the frequency domain using the Fourier transform. This transformation allows for the isolation and manipulation of specific frequency components, which is particularly beneficial for enhancing details and managing noise in low-light images.
The core of the FSSB comprises two 2D-Mamba (Visual-SSM) blocks to process the amplitude and phase components separately in the frequency domain. These blocks model state-space transformations, capturing the transformed information from the input features. This dual-pathway setup within the FSSB processes amplitude and phase in parallel.
After processing through each of the VSS blocks, the modified amplitude and phase components are recombined and transformed back to the spatial domain using the inverse Fourier transform. This method preserves the structural integrity of the image while enhancing textural details that are typically lost in low-light conditions.
Multi-modal Feature Learning
The inherent complexity of low-light images, where both underexposed and overexposed elements coexist, necessitates a versatile approach to image processing. Traditional methods, which typically focus either on spatial details or frequency-based features, fail to adequately address the full spectrum of distortions encountered in such environments. By contrast, the hybrid modeling approach of ExpoMamba leverages the strengths of both the spatial and frequency domains, facilitating a more comprehensive and nuanced enhancement of image quality.
Dynamic Patch Training
Dynamic patch training enhances the 2D scanning model by optimizing its scanning technique for various image resolutions. In ExpoMamba, 2D scanning involves sequentially processing image patches to encode feature representations. We create batches of different resolution images where in a given batch the resolution is fixed and we dynamically randomize the different batch resolutions of input patches during training. This way, the model learns to adapt its scanning and encoding process to different scales and levels of detail.
Experimental Design
Datasets
To test the efficacy of our model, we evaluated ExpoMamba on four datasets:
1. LOL: This dataset has v1 and v2 versions. LOLv2 is divided into real and synthetic subsets. The training and testing sets are split into 485/15, 689/100, and 900/100 on LOLv1, LOLv2-real, and LOLv2-synthetic with 3 × 400 × 600 resolution images.
2. LOL4K: An ultra-high definition dataset with 3×3, 840×2, 160 resolution images, containing 8,099 pairs of low-light/normal-light images, split into 5,999 pairs for training and 2,100 pairs for testing.
3. SICE: Includes 4,800 images, real and synthetic, at various exposure levels and resolutions, divided into training, validation, and testing sets in a 7:1:2 ratio.
Experimental Setting
The proposed network is a single-stage end-to-end training model. The patch sizes are set to 128×128, 256×256, and 324 × 324 with checkpoint restarts and batch sizes of 8, 6, and 4, respectively, in consecutive runs. For dynamic patch training, we use different patch sizes simultaneously. The optimizer is RMSProp with a learning rate of 1 × 10−4, a weight decay of 1 × 10−7, and momentum of 0.9. A linear warm-up cosine annealing scheduler with 15 warm-up epochs is used, starting with a learning rate of 1 × 10−4. All experiments were carried out using the PyTorch library on an NVIDIA A10G GPU.
Loss Functions
To optimize our ExpoMamba model, we use a set of loss functions tailored to enhance the performance of the model across different metrics.
Results and Analysis
Quantitative Evaluation
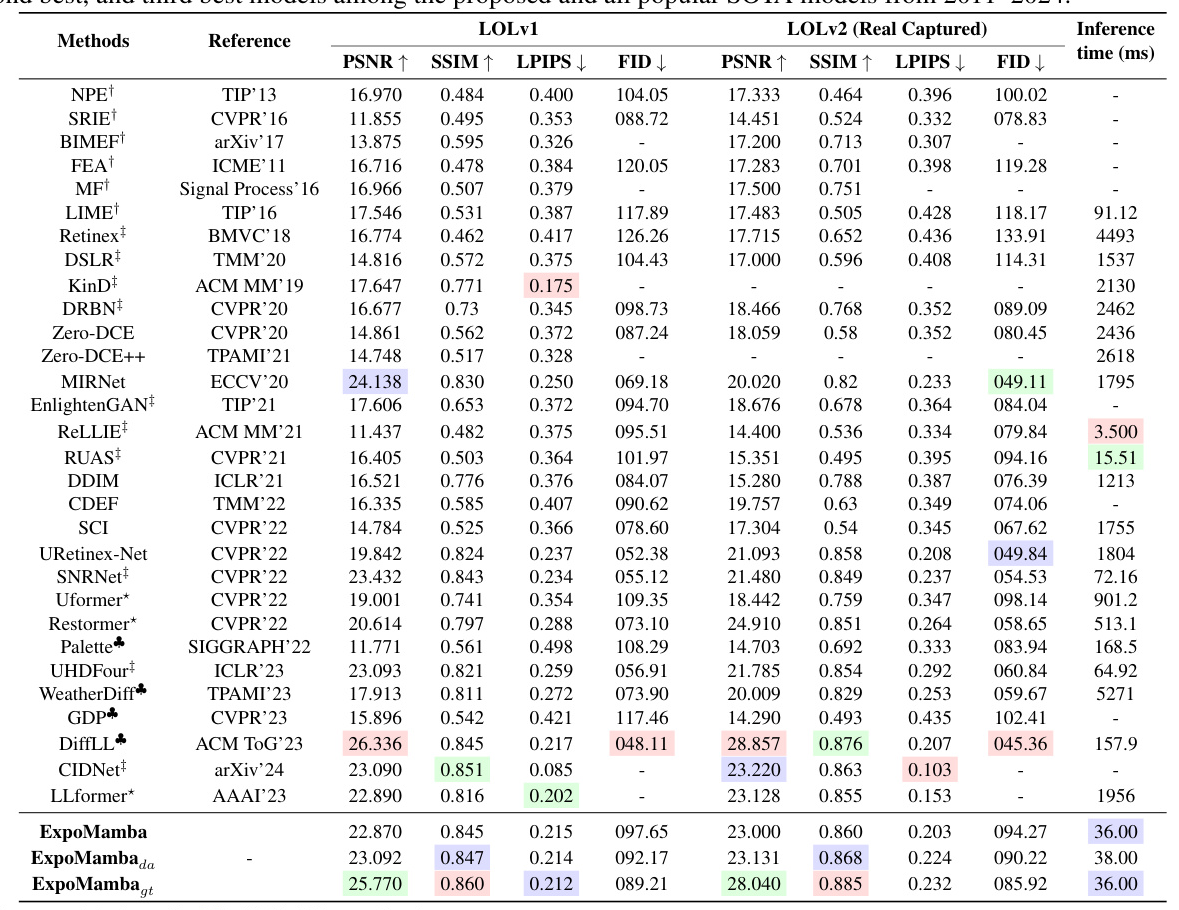
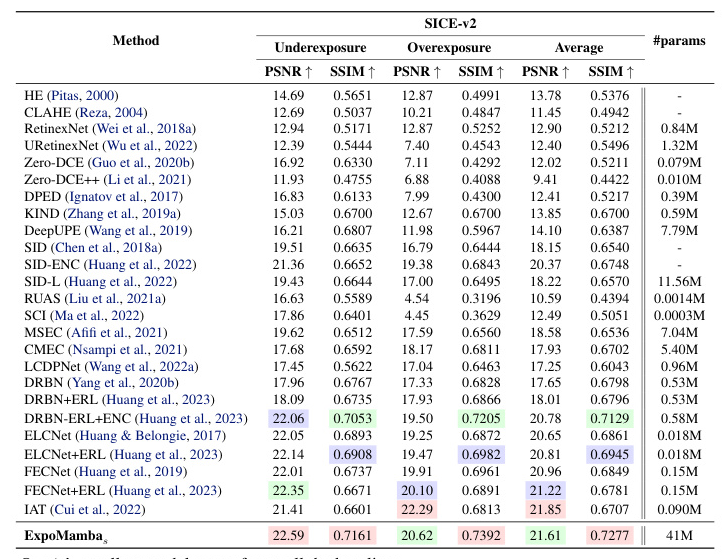
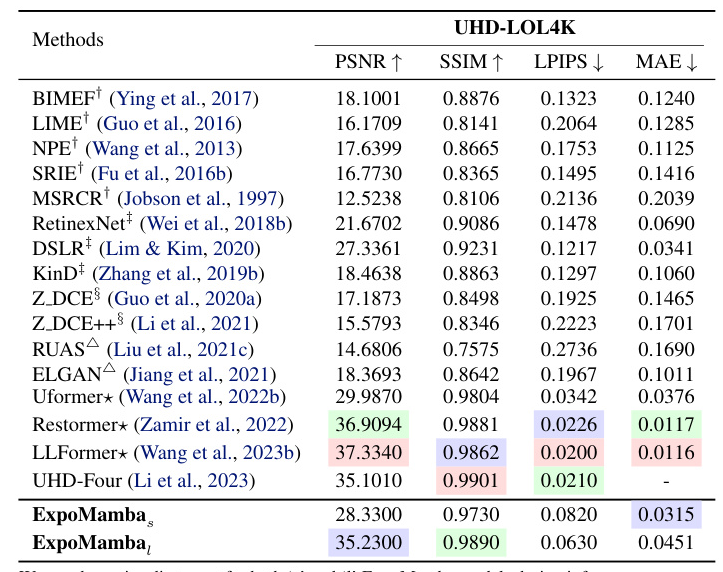
We compare our performance to 31 state-of-the-art baselines, including lightweight and heavy models. We evaluate ExpoMamba’s performance using SSIM, PSNR, LPIPS, and FID. ExpoMamba achieves an inference time of 36 ms, faster than most baselines and the fastest among comparable models. Models like DiffLL, CIDNet, and LLformer have comparable results but much longer inference times.
Memory Efficiency
Despite being a 41 million parameter model, ExpoMamba demonstrates remarkable storage efficiency, consuming approximately one-fourth the memory compared to CIDNet, which, despite its smaller size of 1.9 million parameters, consumes significantly more memory. This is because ExpoMamba’s state expansion fits inside the GPU’s high-bandwidth memory and removes the quadratic bottleneck, significantly reducing the memory footprint.
Performance on Different Datasets
ExpoMamba shows superior performance across various datasets, including LOL, LOL4K, and SICE. It consistently outperforms traditional algorithms and state-of-the-art models in terms of PSNR, SSIM, and other metrics, demonstrating its robustness and adaptability to different low-light conditions.
Overall Conclusion
We introduced ExpoMamba, a model designed for efficient and effective low-light image enhancement. By integrating frequency state-space components within a U-Net variant, ExpoMamba leverages spatial and frequency domain processing to address computational inefficiencies and high-resolution challenges. Our approach combines robust feature extraction of state-space models, enhancing low-light images with high fidelity and achieving impressive inference speeds. Our novel dynamic patch training strategy significantly improves robustness and adaptability to real-world hardware constraints, making it suitable for real-time applications on edge devices. Experimental results show that ExpoMamba is much faster and comparably better than numerous existing transformer and diffusion models, setting a new benchmark in low-light image enhancement.

Code:
https://github.com/eashanadhikarla/expomamba