

Authors:
Rui Yang、Jiahao Zhu、Jianping Man、Li Fang、Yi Zhou
Paper:
https://arxiv.org/abs/2408.10819
Introduction
Knowledge Graphs (KGs) are structured semantic knowledge bases that organize entities, concepts, attributes, and their relationships in a graph format. They are pivotal in various applications such as semantic search, recommendation systems, and natural language processing (NLP). However, due to limited annotation resources and technical constraints, existing KGs often have missing key entities or relationships, limiting their functionality. Knowledge Graph Completion (KGC) aims to infer and fill in these missing entities and relationships, thereby enhancing the value and effectiveness of KGs.
Traditional KGC methods, such as link prediction and instance completion, typically focus on either static knowledge graphs (SKGs) or temporal knowledge graphs (TKGs). These methods often address only within-scope triples, leaving a gap in discovering new facts beyond the closed KG. This paper introduces a novel generative completion framework called Generative Subgraph-based KGC (GS-KGC), which employs a question-answering format to directly generate target entities, addressing the challenge of questions having multiple possible answers.
Related Work
Knowledge Graph Completion
KGC is generally categorized into embedding-based and text-based approaches:
- Embedding-based KGC: Methods like TransE, TransH, TransD, DistMult, ComplEx, and RotatE map entities and relationships into a low-dimensional vector space and use scoring functions to evaluate triples for reasoning. These methods primarily focus on the structural information of KGs but often fail to capture the high-level semantic features of entities and relationships.
- Text-based KGC: Models like KG-BERT and SimKGC utilize pre-trained language models (PLMs) to capture detailed semantic information of entities. These methods enhance semantic understanding but often struggle to integrate both the structural and semantic information of KGs.
LLMs Enhance KGC
Recent advancements in large language models (LLMs) like GPT-4, Llama, and Qwen have shown exceptional generative capabilities across various fields, inspiring researchers to explore their potential applications in KGC tasks. Techniques such as chain-of-thought prompting and parameter-efficient fine-tuning (PEFT) have significantly enhanced the reasoning capabilities of LLMs.
LLM-based KGC
Frameworks like KICGPT, CP-KGC, and KG-LLM have successfully guided LLMs to generate rich contextual paragraphs using a triple-based KGC retriever, supporting small-scale KGC models and significantly enhancing their performance. These approaches demonstrate the potential for integrating various enhancement methods to improve overall performance in KGC tasks.
Research Methodology
GS-KGC Framework
The GS-KGC framework comprises three modules:
- Subgraph Partition: Divides the graph into several subgraphs, each containing a comparable number of entities, serving as efficient context for training.
- QA Template Mapping: Transforms the traditional KGC task into a question-answering task, implementing KGC through a fine-tuned large model.
- Evaluation of Generative KGC: Assesses generative KGC by discovering new triples within or outside the KG, allowing LLMs to transcend the closed-world KGC paradigm.
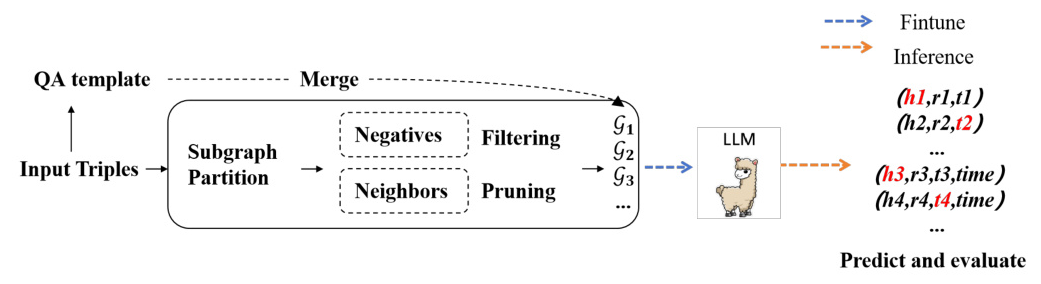
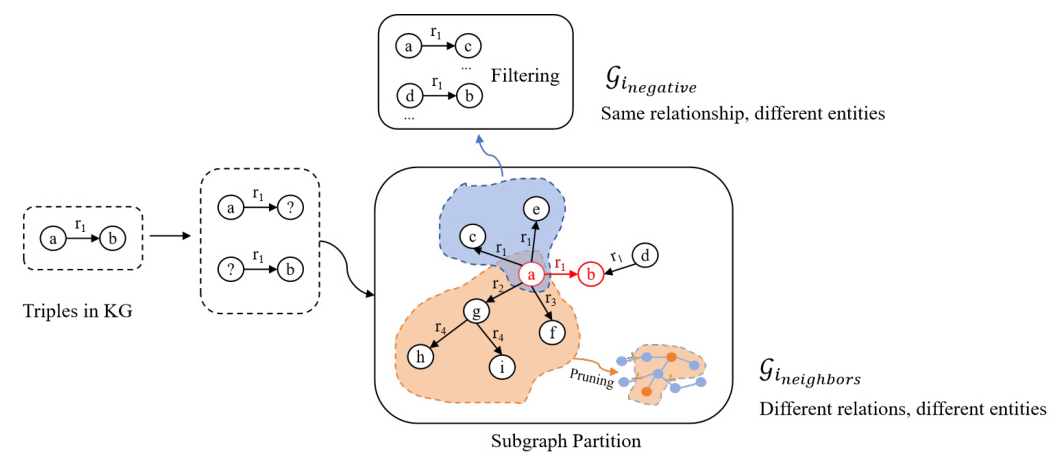
Subgraph Partition
A KG is defined as ( G = {E, R, T} ), where ( E ) is the entity set, ( R ) is the relation set, and ( T ) is the triple set. The subgraph partitioning strategy involves:
- Negative Sampling: Generates negative samples using known facts to facilitate the discovery of new information.
- Optimal Neighborhood Information Supplementation: Collects and refines neighborhood path data of known entities, providing contextual information to enhance reasoning in LLMs.
QA Template Mapping
LLMs have demonstrated outstanding capabilities in NLP tasks such as question-answering. The GS-KGC framework employs a simple question-answer format to implement the KGC task. For a missing triple ((h, r, ?)), a basic question-answer template is designed, incorporating negative samples and neighborhood information to assist LLMs in adapting to specific events and complex logical relationships.
Model Training
Instruction-based fine-tuning is employed to optimize LLM performance on specific tasks. The LoRA technique is used to efficiently fine-tune the model by adjusting a small number of parameters, reducing computational resource demands while maintaining the model’s generalization ability.
Experimental Design
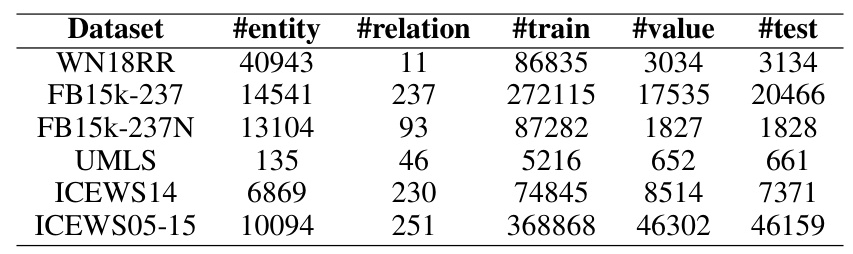
Datasets
Experiments were conducted on several popular KGs, including four SKGs (WN18RR, UMLS, FB15k-237, and FB15k-237N) and two TKGs (ICEWS14 and ICEWS05-15). These datasets are challenging and widely used benchmarks in KGC research.
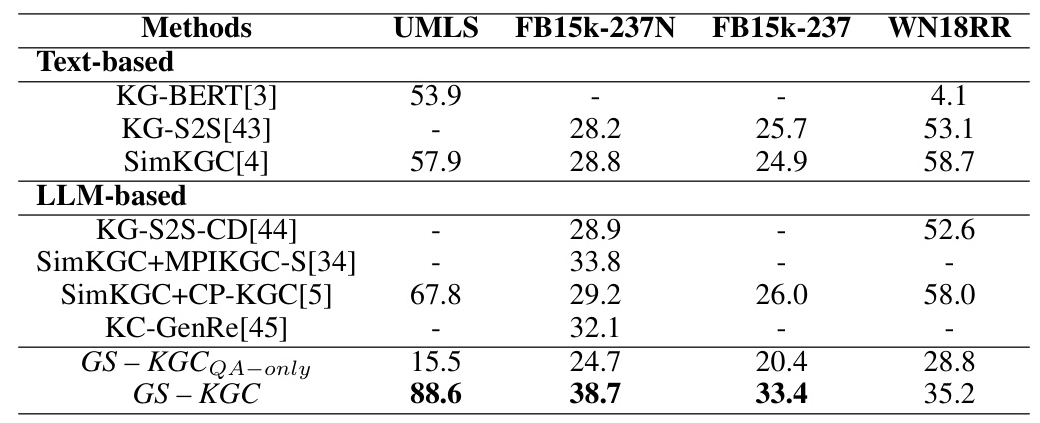
Baselines and Experiment Setup
The performance of GS-KGC was compared with various baseline models, including text-based KGC models (KG-BERT, KG-S2S, SimKGC) and LLM-based models (KG-S2S-CD, SimKGC+MPIKGC-S, SimKGC+CP-KGC). The foundational LLM models used were llama3-8b-instruct for SKGC and glm4-9b-chat for TKGC.
Main Results
The experimental results demonstrated that GS-KGC achieved state-of-the-art performance on multiple SKG and TKG datasets, highlighting its versatility and effectiveness. The reasoning capabilities of LLMs were significantly enhanced when supported by external effective knowledge, as evidenced by the improvements in Hits@1 metrics.
Results and Analysis
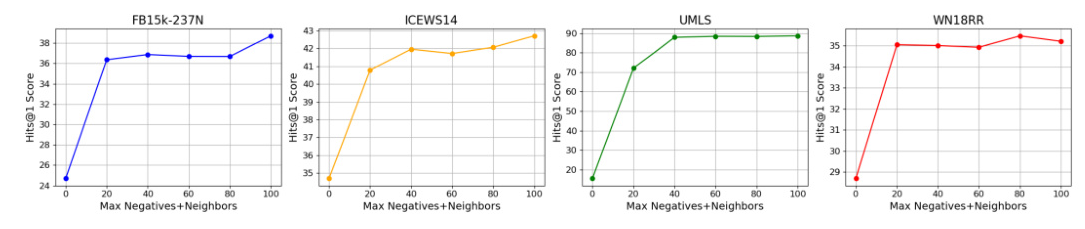
Hyperparameter Analysis
The impact of different values of ( M ) (the total number of negative samples and neighbor information) on model performance was analyzed. The results showed that recalling effective negative samples and neighborhood information significantly enhanced GS-KGC performance, achieving improvements in both SKG and TKG tasks.
Ablation Studies
A detailed ablation study was conducted to understand the specific contributions of negative samples and neighborhood information. The results indicated that combining both types of information resulted in a synergistic effect, significantly enhancing model performance.

Model Size Impact
The impact of model size on KGC performance was explored by comparing two model scales, Qwen2-1.5B-Instruct and LLaMA3-8b-Instruct/GLM4-9B-Chat. The results indicated that increasing the model size effectively enhanced performance, highlighting the potential for further improvements with advancements in LLM technology.
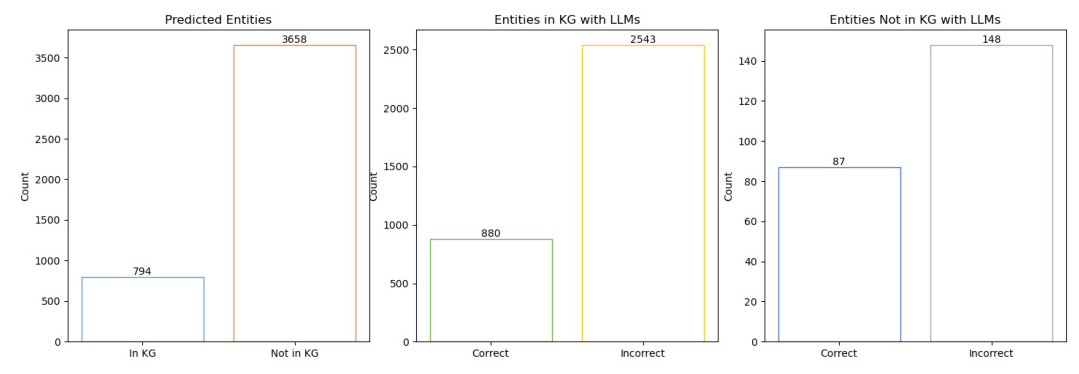
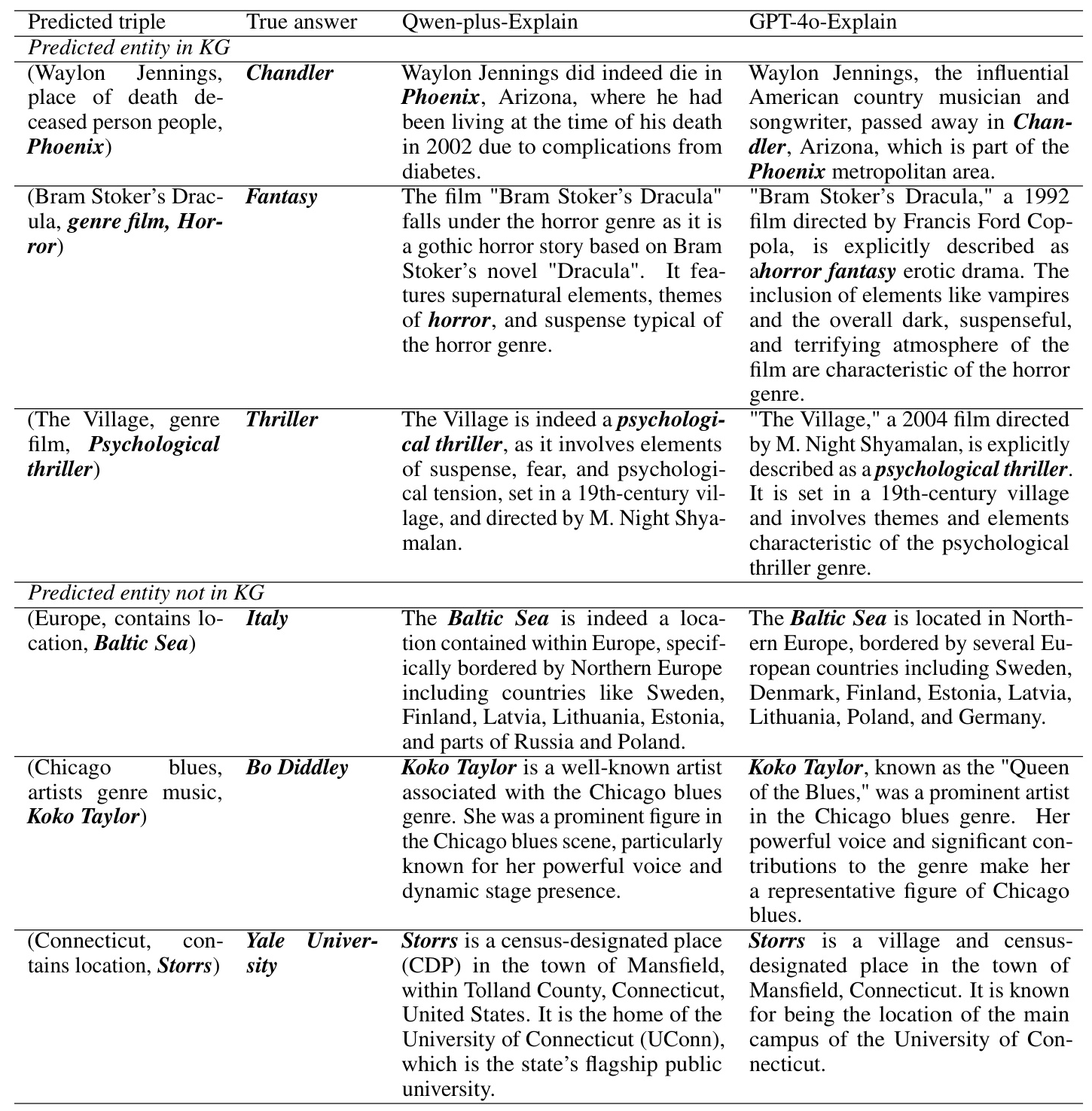
Advantages of GS-KGC
Generative KGC can identify new triple relationships in the KG and introduce entities outside the KG, aligning more closely with the original goal of KGC. This capability enhances the dynamic updating of the KG, expanding its practicality and impact in various real-world applications.
Overall Conclusion
The GS-KGC framework leverages LLMs to perform KGC by generating subgraph-based questions and deriving answers from them. The framework effectively balances the structural and semantic aspects of KGs, achieving state-of-the-art performance on multiple SKG and TKG datasets. GS-KGC demonstrates the potential to bridge the gap between closed-world and open-world KGC, enhancing the practical applications of KGs. Future research will explore higher-quality information recall strategies to enable broader application of GS-KGC in vertical domains.