

Authors:
Mark Towers、Yali Du、Christopher Freeman、Timothy J. Norman
Paper:
https://arxiv.org/abs/2408.08230
Introduction
Reinforcement learning (RL) agents have achieved remarkable success in complex environments, often surpassing human performance. However, a significant challenge remains: explaining the decisions made by these agents. Central to RL agents is the future reward estimator, which predicts the sum of future rewards for a given state. Traditional estimators provide scalar outputs, which obscure the timing and nature of individual future rewards. This paper introduces Temporal Reward Decomposition (TRD), a novel approach that predicts the next N expected rewards, offering deeper insights into agent behavior.
Related Work
Previous research in Explainable Reinforcement Learning (XRL) has explored various methods to decompose Q-values and understand agent decision-making. Some approaches decompose future rewards into components or by future states, while others modify the environment’s reward function. However, these methods often lack scalability or require significant modifications to the environment. TRD differs by decomposing rewards over time, providing a more intuitive understanding of an agent’s future expectations without altering the environment.
Preliminaries
Markov Decision Processes
A reinforcement learning environment is modeled using a Markov Decision Process (MDP), described by the tuple ⟨S, A, R, P, T⟩. These variables represent the set of possible states (S), actions (A), the reward function (R), the transition probability (P), and the termination condition (T). The goal is to learn a policy π that maximizes cumulative rewards over an episode, applying an exponential discount factor (γ) to incentivize immediate rewards.
Deep Q-learning
Deep Q-learning (DQN) extends Q-learning by using neural networks to approximate Q-values, achieving state-of-the-art performance in image-based environments. DQN incorporates several enhancements, including experience replay buffers and target networks for stability.
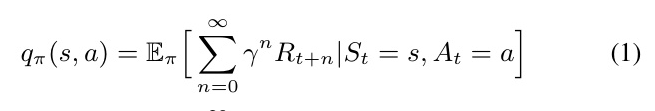
QDagger and GradCAM
QDagger is a training workflow that allows new agents to reuse knowledge from pretrained agents, significantly reducing training time. GradCAM is a saliency map algorithm that highlights input features influencing a neural network’s decisions, useful for visualizing an agent’s focus within an observation.
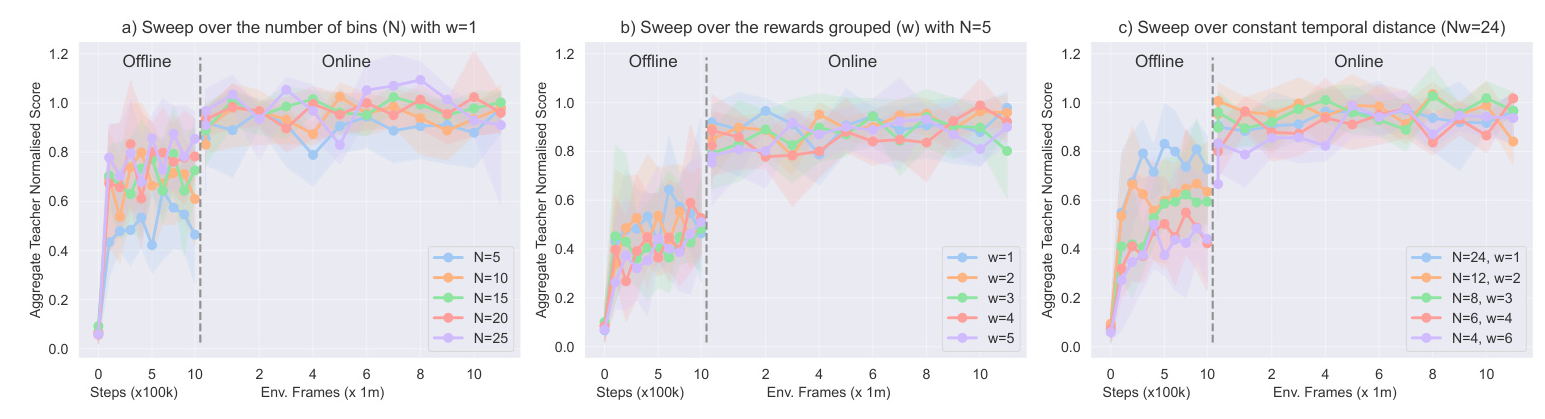
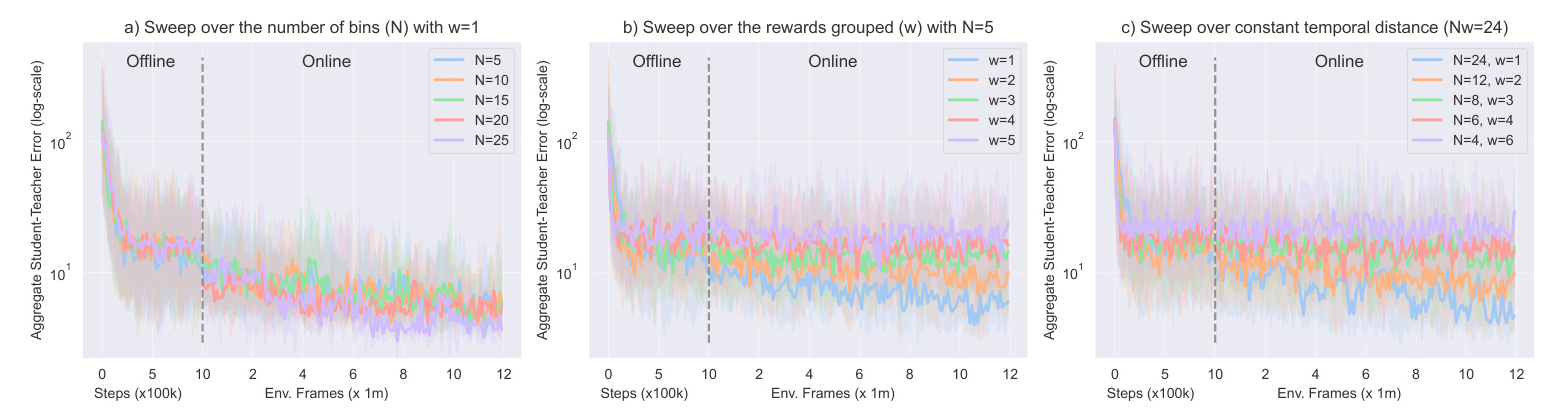
Temporal Reward Decomposition
TRD modifies the future reward estimator to predict the next N expected rewards, providing a vector output instead of a scalar. This approach is mathematically equivalent to traditional Q-value functions but offers more detailed insights into the timing and nature of future rewards.
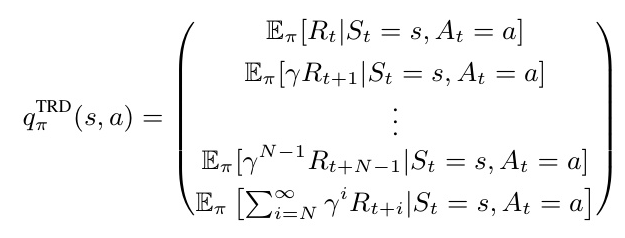
Implementing TRD
Implementing TRD requires increasing the neural network output by N+1 and using a novel element-wise loss function. This allows the network to learn the expected rewards for future timesteps. For long-horizon environments, rewards can be grouped to maintain a manageable output size.
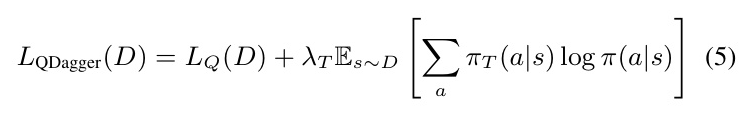
Loss Function
The TRD loss function is designed to converge to a policy similar to the pretrained agent’s scalar Q-value. It computes the element-wise mean squared error between the predicted and target reward vectors, ensuring accurate learning of future rewards.
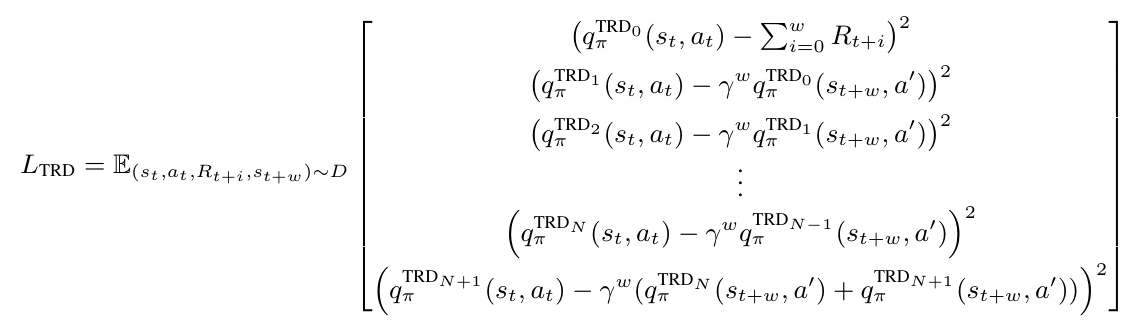
Retraining Pretrained Agents for TRD
To evaluate TRD’s effectiveness, DQN agents were retrained on various Atari environments. Hyperparameter sweeps were conducted to assess the impact of reward vector size (N) and reward grouping (w) on training performance. Results showed that TRD agents achieved performance comparable to their base RL agents, with minimal computational overhead.
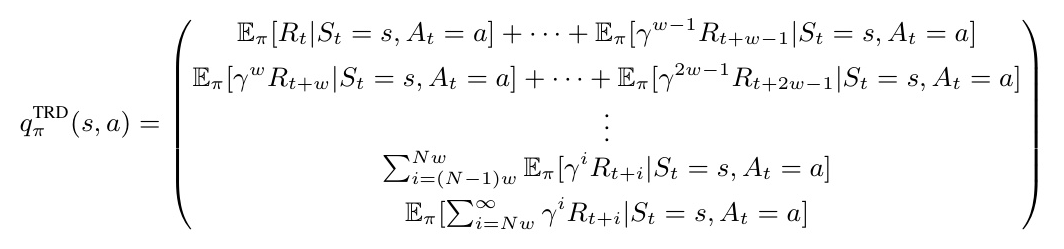
Explaining an Agent’s Future Beliefs and Decision-Making
TRD enables three novel explanation mechanisms:
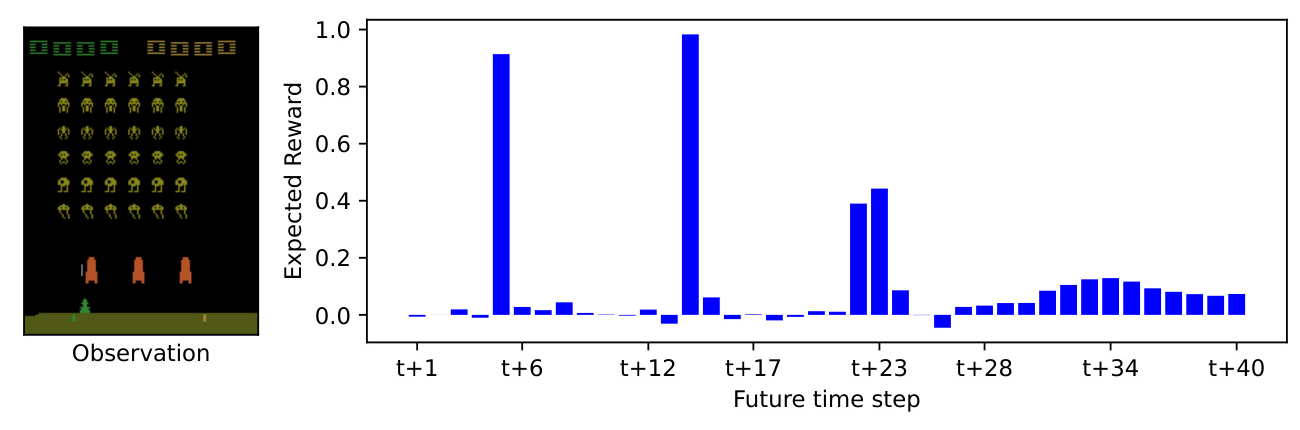
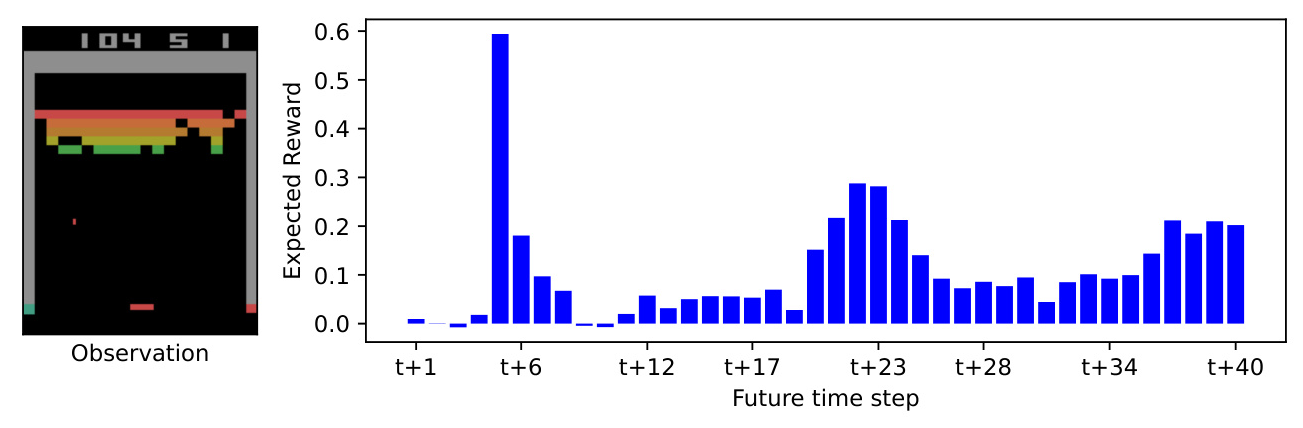
What Rewards to Expect and When?
TRD provides detailed predictions of future rewards, allowing users to understand the agent’s expectations and confidence in receiving rewards. This is particularly useful in environments with complex reward functions.
What Observation Features are Important?
Using GradCAM, TRD can generate saliency maps for individual expected rewards, revealing how an agent’s focus changes over time. This helps visualize the importance of different observation features for near and far future rewards.
What is the Impact of an Action Choice?
TRD facilitates contrastive explanations by comparing the expected rewards for different actions. This highlights the consequences of different action choices on an agent’s future rewards, providing deeper insights into decision-making processes.
Conclusion
Temporal Reward Decomposition (TRD) offers a novel approach to understanding RL agents by decomposing future rewards over time. TRD can be efficiently integrated into existing agents, providing detailed explanations of agent behavior. Future research could explore combining TRD with other decomposition methods and modeling rewards as probability distributions for even richer explanations.
Code:
https://github.com/pseudo-rnd-thoughts/temporal-reward-decomposition