

Authors:
Qifei Li、Yingming Gao、Yuhua Wen、Cong Wang、Ya Li
Paper:
https://arxiv.org/abs/2408.09438
Introduction
Emotion recognition is a crucial aspect of human-computer interaction (HCI), significantly enhancing the interaction experience by accurately interpreting human emotions. Multimodal emotion recognition (MER) leverages various data modalities, such as audio, video, and text, to improve recognition performance. However, the fusion of inter-modal information presents significant challenges, including the need for improved feature representation, effective model structures, and robust fusion methods to handle missing modal information.
To address these challenges, the paper “Enhancing Modal Fusion by Alignment and Label Matching for Multimodal Emotion Recognition” introduces a novel MER framework called Foal-Net. This framework employs a multi-task learning approach, incorporating two auxiliary tasks: audio-video emotion alignment (AVEL) and cross-modal emotion label matching (MEM). These tasks aim to enhance the effectiveness of modality fusion by aligning emotional information before fusion and ensuring consistent emotional labels across modalities.
Related Work
Recent advancements in MER have focused on extracting deep representations from pre-trained models, such as HuBERT, WavLM, BERT, and CLIP, which offer superior performance and generalization compared to conventional features. Various methods have been proposed to model modal information and achieve effective fusion, including modality-sensitive frameworks, time convolution networks, and cross-modal transformers.
Auxiliary tasks have also been employed to assist in modality fusion, particularly in image-text tasks. These tasks, such as image-text matching and contrastive learning, have proven effective in enhancing fusion performance. Inspired by these studies, the authors propose the Foal-Net framework, which integrates AVEL and MEM tasks to improve MER performance.
Research Methodology
Audio-Video Emotion Aligning (AVEL)
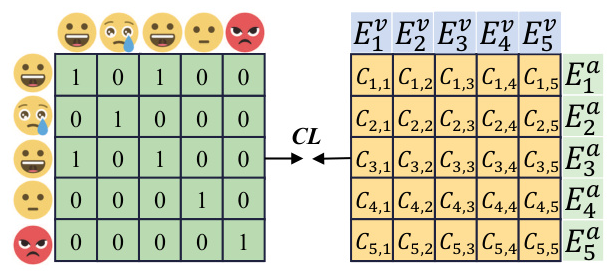
The AVEL task aims to align emotional information between audio and video modalities using contrastive learning. By enhancing the similarity between sample pairs with the same emotional category and reducing the similarity between pairs with different categories, AVEL ensures that emotional information is consistently represented across modalities.
The process involves extracting audio and video embeddings using WavLM and CLIP, respectively. These embeddings are then projected to a common feature space, enabling the calculation of inter-modal similarity matrices. The contrastive loss is computed based on these matrices, guiding the alignment of emotional information.
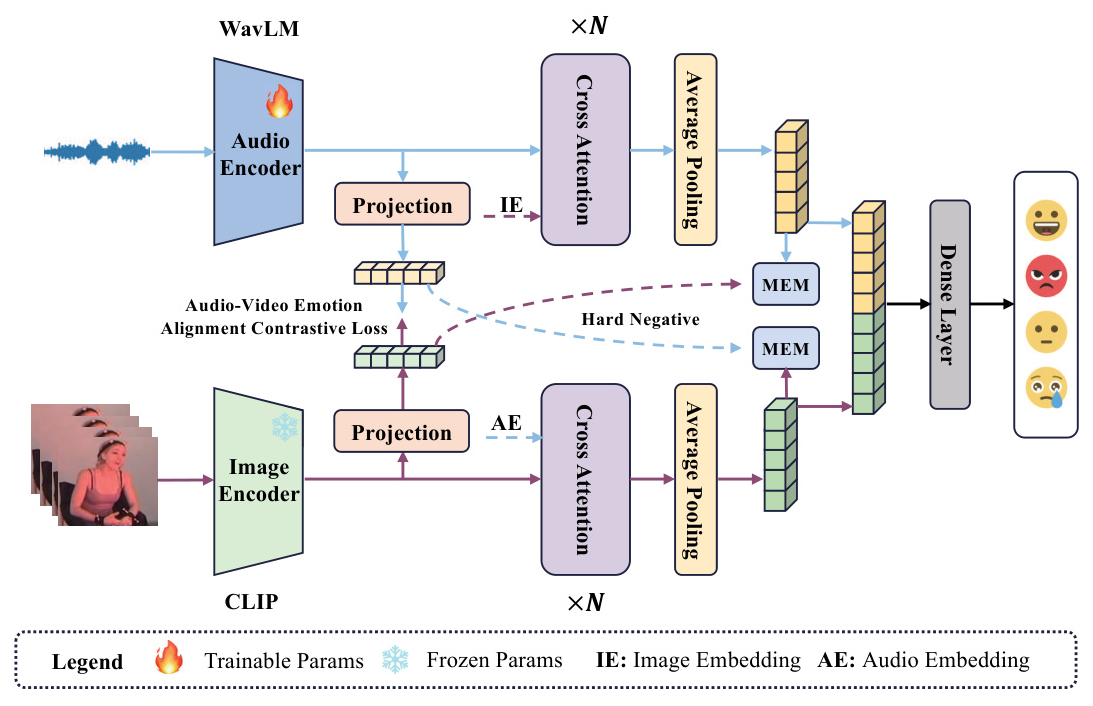
Audio-Video Emotion Matching (MEM)
The MEM task addresses the issue of insufficient fusion of modal information by ensuring that the emotional labels for the current input sample pair are consistent across modalities. This binary classification task uses hard negative samples, which are identified based on the highest similarity but inconsistent emotional information with the current modality sample.
The process involves generating negative samples, feeding them into the fusion network, and computing the cross-entropy loss. The MEM task promotes modality fusion and directs the model to focus on emotional information, enhancing the overall recognition performance.
Modal Fusion Module
The fusion module employs a multi-head cross-attention mechanism to integrate audio and video embeddings. This mechanism ensures that the fused representation captures complementary information from both modalities. The final fused representation undergoes average pooling and is concatenated for emotion recognition.
Experimental Design
Dataset
The IEMOCAP multimodal corpus, a well-known database for emotion recognition, is used for evaluation. It includes audio, video, and text data from five sessions, each with one male and one female speaker. The experiments focus on four emotion categories: happy, angry, sad, and neutral. Five-fold cross-validation is performed using a leave-one-session-out strategy, with weighted accuracy (WA) and unweighted accuracy (UA) as evaluation metrics.
Experimental Details
The feature dimensions for WavLM and CLIP encoders are 1024 and 768, respectively. The projection module has 512 neurons with a dropout rate of 0.5. The training process uses a batch size of 64, a learning rate of 1e-4, and the AdamW optimizer. The input for the audio modality consists of 6 seconds of speech at a 16 kHz sampling rate, while the video modality input consists of 180 individual images.
Results and Analysis
Performance Comparison
The experimental results demonstrate that Foal-Net outperforms state-of-the-art (SOTA) methods on the IEMOCAP corpus, achieving the highest UA (80.10%) and WA (79.45%). This highlights the effectiveness of the proposed framework in enhancing MER performance.
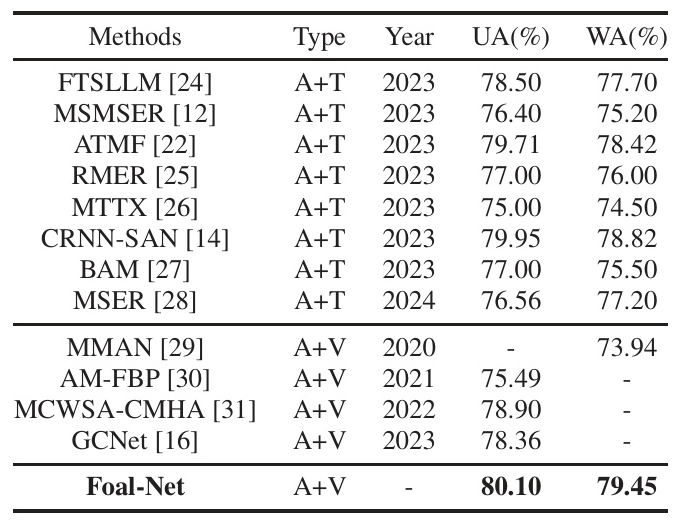
Ablation Studies
A series of ablation experiments validate the effectiveness of the proposed features, auxiliary tasks, and the final model. The results indicate that global image encoding using CLIP outperforms local facial information encoding. Additionally, the AVEL task significantly improves performance, underscoring the necessity of cross-modal emotion alignment before fusion. The MEM task further enhances performance when combined with AVEL, demonstrating the complementary nature of these auxiliary tasks.
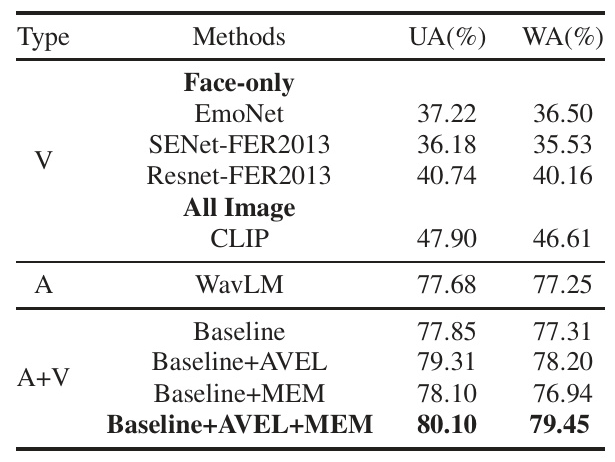
Overall Conclusion
The Foal-Net framework introduces a novel approach to MER by incorporating AVEL and MEM auxiliary tasks. The AVEL task ensures effective alignment of emotional information across modalities, while the MEM task promotes consistent emotional labels and enhances modality fusion. The experimental results on the IEMOCAP corpus demonstrate that Foal-Net achieves SOTA performance, highlighting the importance of alignment before fusion in MER. Future work will focus on optimizing the MEM task and validating the method’s universality by incorporating the text modality.
Acknowledgements
The work was supported by the National Natural Science Foundation of China, the Key Project of the National Language Commission, the Fundamental Research Funds for the Central Universities, BUPT Excellent Ph.D. Students Foundation, and the Major Program of the National Social Science Fund of China.
References
The paper includes an extensive list of references, highlighting the contributions of various studies in the field of MER and related tasks. These references provide a comprehensive background for understanding the advancements and challenges in multimodal emotion recognition.