Authors:
Kai Qiu、Xiang Li、Hao Chen、Jie Sun、Jinglu Wang、Zhe Lin、Marios Savvides、Bhiksha Raj
Paper:
https://arxiv.org/abs/2408.09027
Introduction
Background
Autoregressive (AR) modeling has been a cornerstone in the field of generative modeling, particularly in text and image generation. However, its application in audio generation has been limited due to the inherent challenges posed by the long sequence lengths and continuity of audio data. Traditional AR models predict tokens sequentially, which can be computationally expensive and time-consuming, especially for audio data with high sampling rates.
Problem Statement
The primary challenge in AR-based audio generation is the efficiency of token prediction. Given the significant sequence length of audio, traditional next-token prediction methods are not feasible for real-time applications. This study aims to address this issue by proposing a novel Scale-level Audio Tokenizer (SAT) and a scale-level Acoustic AutoRegressive (AAR) modeling framework. These innovations aim to reduce the token length and the number of autoregressive steps, thereby improving the efficiency and quality of audio generation.
Related Work
Raw Audio Discretization
Before the advent of Variational Autoencoders (VAEs), converting continuous audio signals into discrete representations was a significant challenge. VAEs facilitated this process by using encoder-decoder networks to quantize inputs into structured priors. Recent advancements like VQGAN and RQGAN have further improved model generalization and inspired numerous works in audio discretization. Notable contributions include Encodec, which uses an encoder-decoder model with residual quantization, and HIFI-codec, which employs group residual quantization.
Diffusion-Based Audio Generation
Diffusion models have shown promise in generating high-quality audio by progressively transforming noise into coherent signals. These models have been widely adopted in various audio applications, including speech synthesis and music generation. However, the iterative nature of the diffusion process presents challenges such as high computational costs and significant inference times.
Autoregressive Modeling
Autoregressive models have excelled in text generation and machine translation by leveraging efficient Large Language Models (LLMs). These models generate the next tokens sequentially to construct the output. However, their application in raw audio generation remains challenging due to the large number of tokens required to represent audio data. This study aims to mitigate these limitations by employing a Scale-level Audio Tokenizer to encode raw audio at different scales and generate it using Acoustic AutoRegressive modeling via next-scale prediction.
Research Methodology
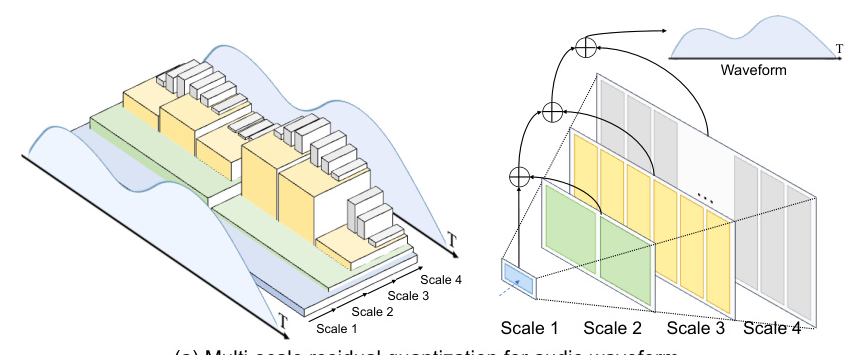
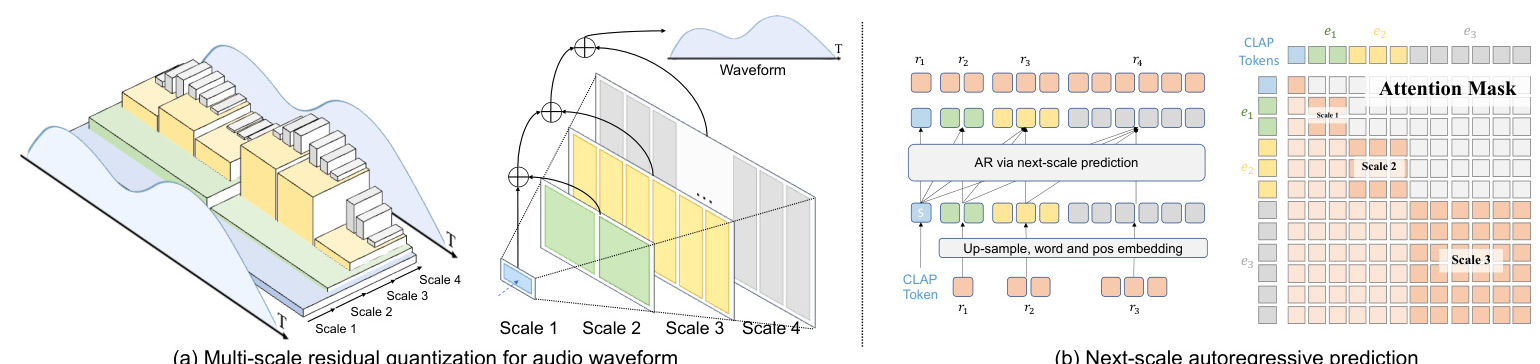
Scale-level Audio Tokenizer (SAT)
The proposed SAT aims to shorten the audio token length by improving traditional residual quantization with a multi-scale design. This approach compresses the token length according to the scale index, thereby reducing the number of tokens required to represent the audio.
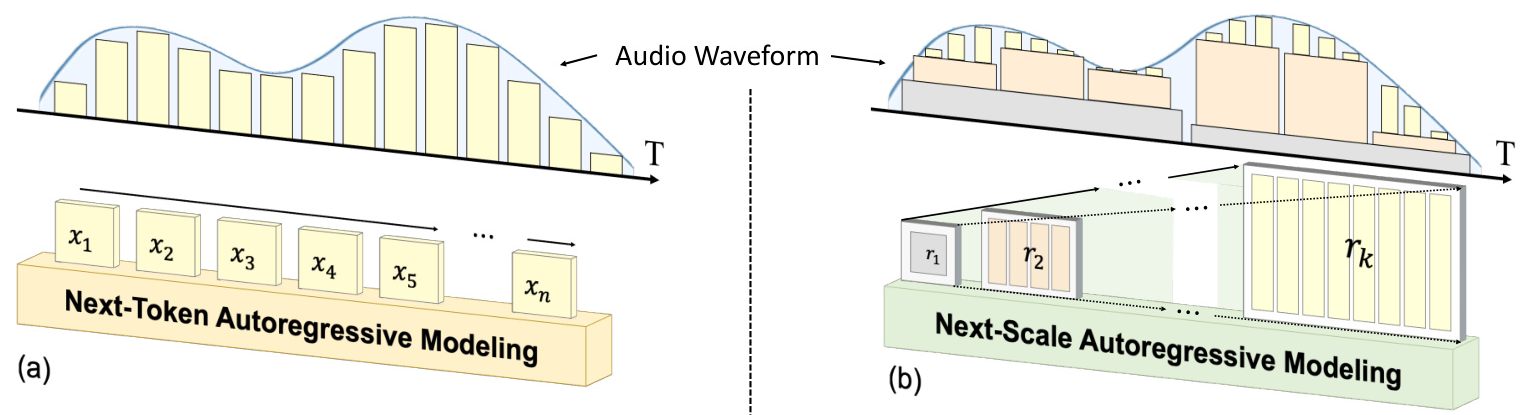
Acoustic AutoRegressive (AAR) Modeling
Based on the multi-scale audio tokenizer, the AAR framework shifts the next-token AR prediction to next-scale AR prediction. This approach models the audio tokens with a next-scale paradigm, significantly reducing the number of autoregressive steps during inference. By reducing both the token length and the autoregressive step number, the proposed method achieves superior audio quality and faster inference speed.
Experimental Design
Evaluation Metrics
The performance of the proposed approach is evaluated using several metrics, including Fréchet Audio Distance (FAD), MEL distance, and STFT distance for reconstruction, and FAD, Inception Score (ISc), and KL divergence for generation. These metrics provide a comprehensive assessment of the quality and efficiency of the generated audio.
Dataset
All experiments are conducted on the AudioSet dataset. The evaluation set is divided into segments matching the window size of the model for reconstruction. For autoregressive generation, a random segment from the evaluation set is used as the ground truth.
Implementation Details
Tokenizer
In the first stage, the multi-scale residual quantization (MSRQ) is employed with a codebook size of 1024. The model is trained for 100 epochs using the Adam optimizer with specific learning rate settings and loss weights.
Transformer
In the second stage, a GPT-2-style transformer with adaptive normalization is used for scale-level acoustic autoregressive modeling. CLAP audio embeddings are used as start tokens to capture richer context. The model is trained using the AdamW optimizer with specific learning rate settings and weight decay.
Results and Analysis
Main Results
The proposed SAT tokenizer outperforms the baseline Encodec by 0.3 FAD, despite using fewer tokens. This demonstrates that increasing quantization while reducing the number of tokens can efficiently improve reconstruction quality. The AAR framework shows superior performance in terms of both latency and audio quality, achieving a 35x speed improvement and better FAD scores compared to the next-token prediction method.
Ablation Studies
Effect of Scale Setting
Different scale settings were tested to find the optimal combination for SAT configuration. Quadratic scheduling proved to be more efficient, requiring fewer tokens and achieving comparable reconstruction performance.
Effect of Discriminator
Multiple discriminator configurations were explored to optimize the performance of SAT. The results indicate that using only a multi-scale STFT discriminator is sufficient for effective reconstruction.
Effect of Temporal Windows
The performance of SAT was validated across different temporal windows. The results suggest that SAT performs well across diverse time windows, maintaining consistent quality and demonstrating robustness in handling varying temporal scales.
Effect of Upsampling Function
The effectiveness of the 1D convolutional layer after upsampling was evaluated through different configurations. The partially shared architecture significantly improved generation quality.
Effect of AAR and Sampling Technique
The AAR framework, combined with attention normalization, classifier-free guidance, and advanced sampling techniques, showed improved generation abilities and significantly reduced inference time.
Classifier-Free Guidance
The relationship between Inception Score (ISc) and Fréchet Audio Distance (FAD) across different Classifier-Free Guidance (CFG) scales was evaluated. The results indicate that as the CFG scale increases, the ISc improves, while both FAD and KL metrics converge and stabilize at a specific CFG scale.
Overall Conclusion
This study introduces a novel approach for efficient autoregressive audio modeling via next-scale prediction. The proposed Scale-level Audio Tokenizer (SAT) and Acoustic AutoRegressive (AAR) modeling framework significantly reduce the token length and the number of autoregressive steps, thereby improving the efficiency and quality of audio generation. Comprehensive experiments demonstrate the superior performance of the proposed method compared to traditional autoregressive methods. This approach provides an efficient solution for audio generation, leveraging multi-scale residual quantization to enhance efficiency and reduce computational demands.