Authors:
Yuyan Chen、Chenwei Wu、Songzhou Yan、Panjun Liu、Haoyu Zhou、Yanghua Xiao
Paper:
https://arxiv.org/abs/2408.10947
Introduction
Background
Large Language Models (LLMs) have shown remarkable performance in various natural language processing (NLP) tasks, including question answering, information retrieval, reasoning, and text generation. Their potential extends beyond general NLP applications into specialized domains such as education. In the educational field, LLMs can serve as automated teaching aids, helping to alleviate the burden on human educators by recommending courses, generating practice problems, and identifying areas where students need improvement.
Problem Statement
While LLMs have been extensively evaluated for their comprehension and problem-solving skills, their capability as educators, particularly in generating high-quality educational questions, remains underexplored. Questioning is a critical teaching skill that helps students analyze, evaluate, and synthesize core concepts. This study introduces a benchmark to evaluate the questioning capability of LLMs in education, focusing on their ability to generate educational questions based on Anderson and Krathwohl’s taxonomy.
Related Work
Question Generation
Several studies have explored the potential of LLMs in generating questions for educational purposes. Chen et al. (2019) developed a reinforcement learning approach for generating natural questions. Elkins et al. (2023) evaluated the educational utility of questions produced by LLMs, organizing them according to their levels of difficulty. Other studies have focused on various prompting techniques and the use of LLMs to foster curiosity-driven questioning among children.
Test-based Benchmark
There has been an increasing focus on evaluating the capability of LLMs in the context of standardized exams and academic benchmarks. For example, Zhang et al. (2023b) introduced the GAOKAO Benchmark for Chinese college entrance examination questions, while Huang et al. (2023) proposed the C-EVAL package for comprehensive Chinese evaluation. However, these tests treat LLMs as students, assessing their abilities by how they answer questions rather than their capability to generate educational questions.
Research Methodology
Benchmark Development
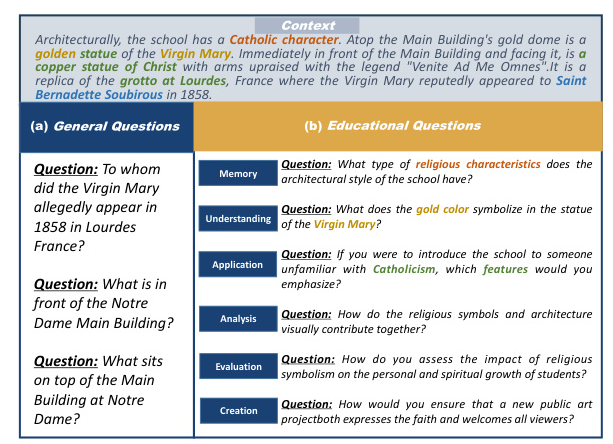
To evaluate the questioning capability of LLMs, we developed a benchmark named Dr.Academy. This benchmark is based on Anderson and Krathwohl’s educational taxonomy, which includes six cognitive levels: memory, understanding, application, analysis, evaluation, and creation. The benchmark tasks are divided into three domains: general, monodisciplinary, and interdisciplinary.
Evaluation Metrics
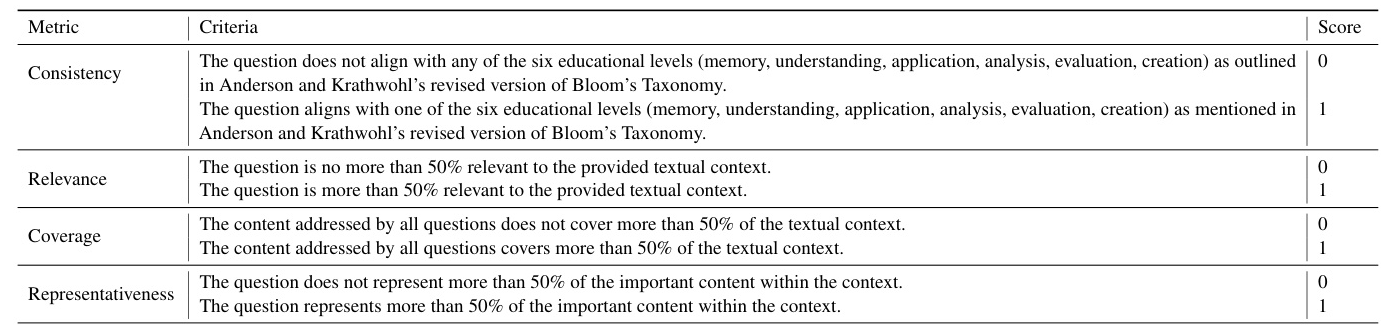
We designed four evaluation metrics to assess the quality of questions generated by LLMs:
1. Consistency: Whether the question aligns with the predefined educational level.
2. Relevance: Whether the question is related to the provided text content or theme.
3. Coverage: Whether the generated questions encompass a major portion (over 50%) of the given context.
4. Representativeness: Whether the question captures the main content or core ideas of the text.
Experimental Design
Context Construction
We collected 10,000 contexts from the general domain and produced an additional 10,000 contexts for the monodisciplinary domain. In the general domain, contexts were sourced from the SQuAD dataset, while in the monodisciplinary domain, contexts were generated for multiple-choice questions from the MMLU dataset. Manual evaluations were conducted to ensure the quality of the generated contexts.
Task Setup
Three tasks were designed for the benchmark:
1. General Domain Tasks: LLMs generate questions based on the six levels of Anderson and Krathwohl’s taxonomy using contexts from the SQuAD dataset.
2. Monodisciplinary Domain Tasks: LLMs generate questions focusing on either humanities or sciences using contexts from the MMLU dataset.
3. Interdisciplinary Domain Tasks: LLMs generate questions that cross multiple subject areas, reflecting each subject’s characteristics.

Evaluation Process
We adopted GPT-4 to score each question three times. A question that scores 1 in two out of three instances meets the metric’s requirement. The evaluation metrics were validated by consulting ten experts in education, who consistently awarded these metrics scores of 4 and above.
Results and Analysis
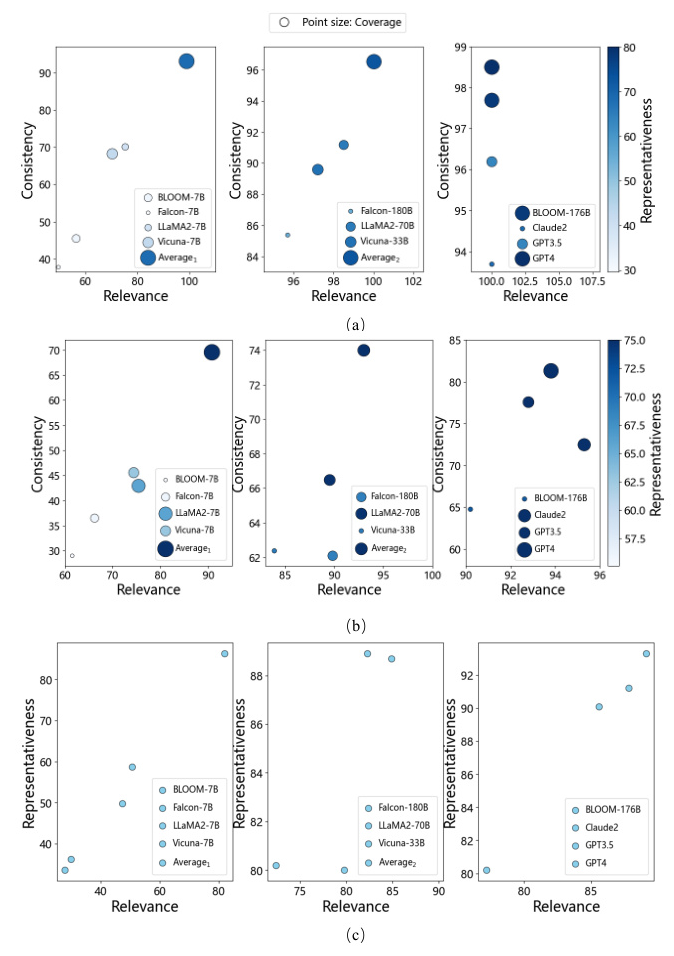
General Domain Performance
In the general domain tasks, GPT-4 achieved a perfect score in both consistency and relevance, indicating its strong capability in understanding task requirements and generating relevant questions. However, its coverage score suggested room for improvement in generating questions that encompass more content.
Monodisciplinary Domain Performance
In the monodisciplinary domain tasks, GPT-4 excelled across all metrics, particularly in the science disciplines. Claude2 also performed well, especially in the humanities, demonstrating a deep understanding and effective processing of humanities content.
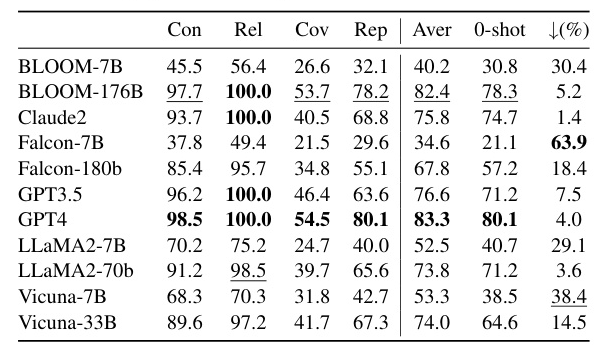
Interdisciplinary Domain Performance
In the interdisciplinary domain tasks, Claude2 outperformed other LLMs, followed closely by GPT-4. Both models showed strong performance in understanding key textual content and generating in-depth questions.
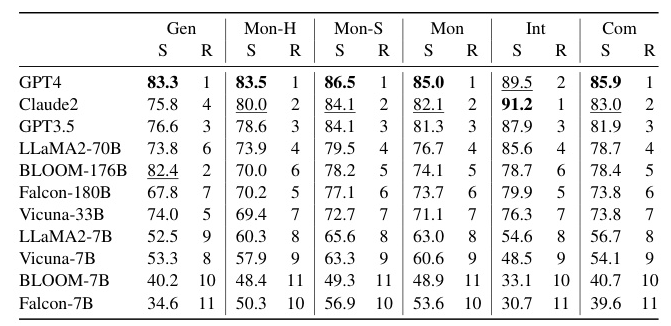
Comprehensive Performance
Overall, GPT-4 showed the best performance across most tasks, while Claude2 demonstrated strong capability in certain tasks. The metrics also tended to show positive correlations with each other, indicating their reliability in evaluating the questioning capability of LLMs.
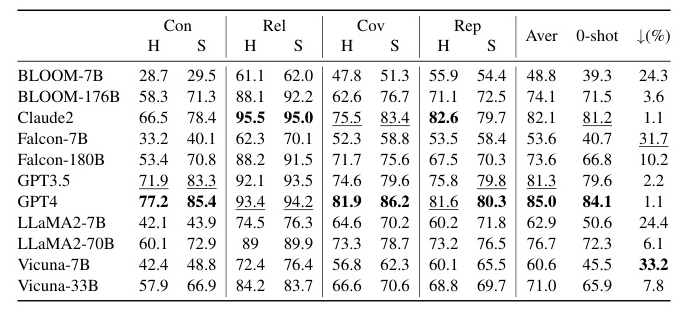
Human vs. Automatic Scoring
The Pearson correlation coefficient between automatic and human scores reached 0.947, indicating a high positive correlation. This suggests that automatic scoring has the potential to partially replace human scoring for evaluating the questioning capability of LLMs.
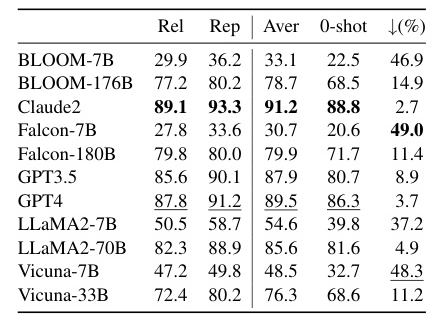
Overall Conclusion
Summary
This study presents a pioneering investigation into the questioning capability of LLMs in education. We developed a comprehensive benchmark, Dr.Academy, based on educational taxonomies to assess LLMs’ abilities to generate questions across various domains. Our findings indicate that models like GPT-4, Claude2, and GPT-3.5 demonstrate promising teaching potential.
Future Directions
Future research should focus on refining the evaluation metrics for more nuanced assessments of teaching effectiveness and expanding the range of subjects and domains covered. Additionally, exploring the capability of LLMs to provide feedback, adapt to students’ needs, and foster critical thinking will be crucial for their development as effective teaching aids.
Limitations
One limitation of this study is its focus on question generation, which is just one aspect of teaching. Actual teaching involves more complex interactions, including providing feedback and adapting to students’ needs. Our approach also relies heavily on textual content, which may not fully capture the nuances of human teaching methods.
Acknowledgements
This work is supported by the Science and Technology Commission of Shanghai Municipality, the National Natural Science Foundation of China, and other institutions.