Authors:
Yin-Jyun Luo、Kin Wai Cheuk、Woosung Choi、Toshimitsu Uesaka、Keisuke Toyama、Koichi Saito、Chieh-Hsin Lai、Yuhta Takida、Wei-Hsiang Liao、Simon Dixon、Yuki Mitsufuji
Paper:
https://arxiv.org/abs/2408.10807
Introduction
Disentangled representation learning (DRL) has been a significant area of research in machine learning, focusing on capturing semantically meaningful latent features of observed data in a low-dimensional latent space. This approach has been applied to various domains, including music audio, to extract representations of timbre and pitch. However, existing work has primarily focused on single-instrument audio, leaving a gap in handling multi-instrument mixtures. To address this, the authors propose DisMix, a generative framework designed to disentangle pitch and timbre representations from mixtures of musical instruments, enabling source-level pitch and timbre manipulation.
Related Work
Pitch and Timbre Disentanglement
Previous strategies for pitch-timbre disentanglement include supervised learning, metric learning based on domain knowledge, and general inductive biases. These methods have been successful for single-instrument audio but fall short when dealing with mixtures of instruments. Some studies have attempted to extract pitch and timbre information from mixtures, but they often focus on symbolic music rearrangement and transcription rather than generating novel mixtures.
Object-Centric Representation Learning
Object-centric representation learning involves encoding object entities in a visual scene by unique representations. This concept has been extended to audio, where separate representations for different sources from mixtures are learned. DisMix builds on this idea by further disentangling pitch and timbre of individual sources and tackling more complex datasets with a conditional latent diffusion model (LDM).
Research Methodology
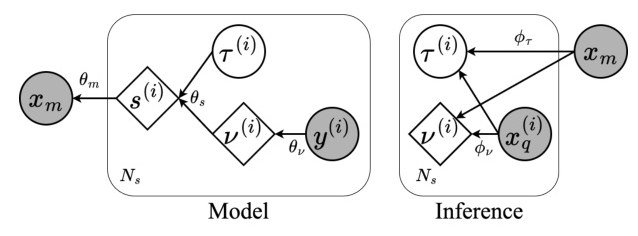
DisMix Framework
DisMix aims to extract latent representations of pitch and timbre for each instrument in a mixture and sample novel mixtures conditioned on manipulated pitch and timbre latents. The generative process involves sampling a mixture through a neural network conditioned on a set of source-level representations, which are deterministic functions of timbre and pitch. The pitch latent is computed via a neural network using ground-truth pitch annotations, while the timbre latent is parameterized as a Gaussian distribution.
Mixture and Query Encoders
Given a mixture of instruments, additional information is necessary to specify which instrument’s latents are to be extracted. This is achieved using a query so that the extracted latents of the source and the query share the same timbre characteristics while carrying arbitrary pitch information. During training, each mixture is paired with a set of queries corresponding to the constituent instruments of the mixture.
Pitch and Timbre Encoders
The pitch and timbre encoders admit a common factorized form, where the pitch and timbre latents of each source are encoded independently of each other and other sources. A binarization layer is applied to constrain the capacity of the pitch latent, which is crucial for disentanglement. The timbre latent is constrained by imposing a standard Gaussian prior.
Training Objectives
The training objectives include maximizing an evidence lower bound (ELBO) to the marginal log-likelihood, minimizing a binary cross-entropy loss for pitch supervision, and minimizing a simplified Barlow Twins loss to enhance the correlation between the query and the timbre latent. The final objective combines these terms to achieve effective disentanglement.
Experimental Design
Simple Case Study
A simple case study is conducted using a synthetic dataset of isolated chords rendered by sound fonts of piano, violin, and flute. The dataset consists of 28,179 samples of mixtures split into training, validation, and test sets. The architecture employs simple layers, including MLP and RNN, to evaluate the effectiveness of DisMix in a simplified setup.
Latent Diffusion Framework
For a more complex setup, DisMix is implemented using a latent diffusion model (LDM) framework. The dataset used is the CocoChorale dataset, which provides realistic generative music in the style of Bach Chorales, featuring 13 orchestral instruments. The architecture leverages a pre-trained VAE encoder and decoder from AudioLDM2 and employs a diffusion transformer (DiT) to reconstruct mixtures given a set of source-level latents.
Results and Analysis
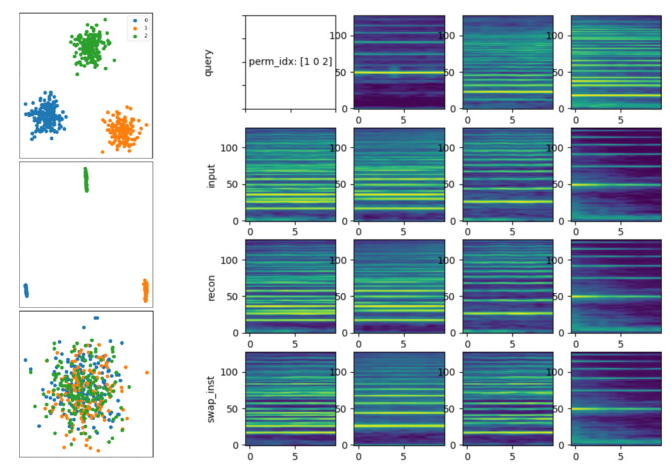
Simple Case Study Results
The evaluation involves extracting pitch and timbre latents from a mixture and conducting a random permutation to swap pitch latents while keeping timbre unchanged. The results show successful disentanglement, with high classification accuracy for both pitch and instrument. An ablation study identifies key loss terms for effective disentanglement, highlighting the importance of the binarization layer and the Kullback–Leibler divergence term.
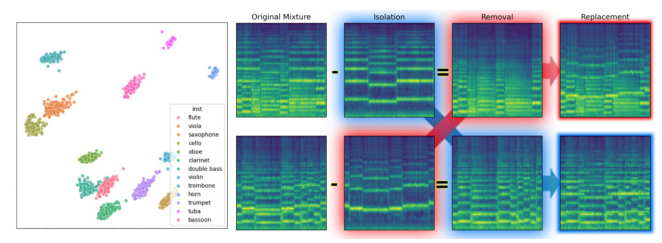
Latent Diffusion Framework Results
The evaluation for the LDM framework involves replacing timbre latents of a reference mixture with those from a target mixture and assessing the classification accuracy of the resulting sources. The results demonstrate high instrument and pitch classification accuracy, validating the effectiveness of the set-conditioned reconstruction approach. The Fréchet Audio Distance (FAD) metric further confirms the quality of the generated audio.
Overall Conclusion
DisMix presents a novel approach to disentangling pitch and timbre representations from multi-instrument mixtures, enabling source-level manipulation and the generation of novel mixtures. The framework demonstrates superior performance in both simple and complex setups, highlighting its potential for various applications in music audio processing. Future work will focus on relaxing the model’s requirements and exploring new applications such as attribute inpainting.