Authors:
Xiongtao Sun、Gan Liu、Zhipeng He、Hui Li、Xiaoguang Li
Paper:
https://arxiv.org/abs/2408.08930
Introduction
The advent of Large Language Models (LLMs) such as GPT-4 has revolutionized the field of Natural Language Processing (NLP), enabling applications ranging from intelligent assistants to customized content generation. A critical component in interacting with these models is the use of prompts, which guide the models to perform specific tasks and generate desired outputs. However, the use of precise prompts can inadvertently lead to the leakage of Personally Identifiable Information (PII), posing significant privacy risks.
To address this issue, the paper proposes DePrompt, a framework designed to desensitize and evaluate the effectiveness of prompts in protecting PII. By leveraging fine-tuning techniques and contextual attributes, DePrompt aims to achieve high-precision PII entity identification and develop adversarial generative desensitization methods that maintain semantic content while disrupting the link between identifiers and privacy attributes.
Related Work
Privacy-Preserving Data Publishing (PPDP)
PPDP techniques such as K-anonymity and differential privacy have been widely used to protect sensitive information in datasets. Previous research has explored the application of differential privacy in prompt fine-tuning, achieving privacy-preserving prompts through mechanisms like exponential differential privacy. However, these methods often introduce noise, leading to grammatical errors and semantic biases, thereby reducing the usability of prompts.
Natural Language Processing (NLP)
NLP methods have been employed for text privacy recognition, utilizing models like LSTM, BiLSTM-CRF, and GPT-4 for entity recognition. While these methods have achieved high accuracy, they often rely on traditional desensitization techniques such as deletion and masking, resulting in significant losses in prompt usability.
Evaluation Metrics
Existing evaluation metrics for privacy protection and data utility often focus on overall datasets and do not account for individual prompt scenarios. Therefore, there is a need for a comprehensive evaluation framework that considers both privacy and usability in the context of prompts.
Research Methodology
System Model
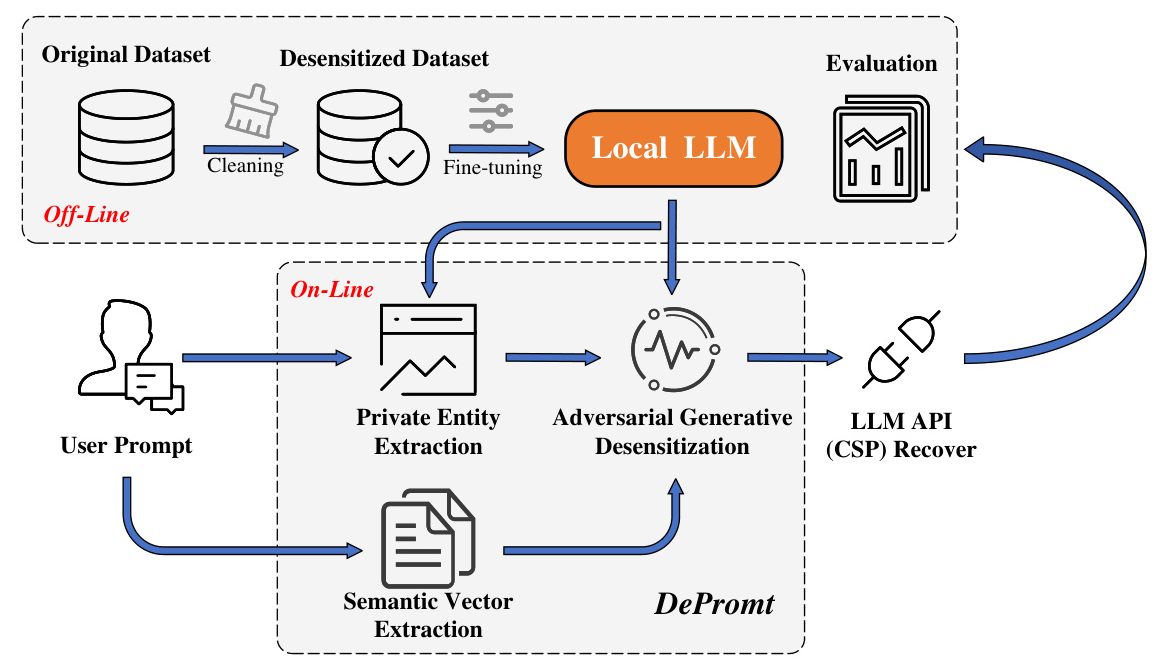
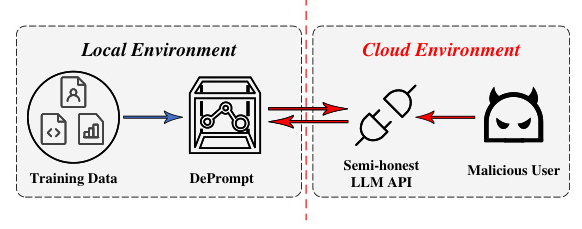
The DePrompt framework consists of three main entities: the LLM user, the local protection mechanism (DePrompt), and the LLM cloud service provider (CSP). The user provides prompts, which are then processed by DePrompt to identify and anonymize PII before being uploaded to the CSP for model inference.
Threat Model
The threat model assumes that the CSP is honest-but-curious, meaning it does not maliciously modify prompts or inference results but may attempt to extract sensitive information. Adversaries are assumed to have access to the prompts and the LLM frameworks used, posing risks of privacy breaches.
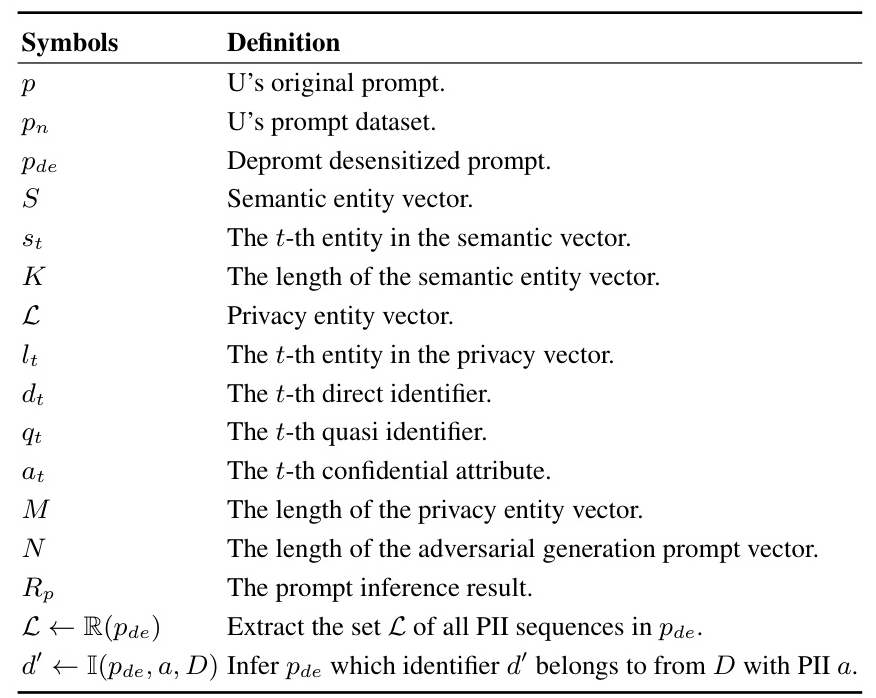
Key Concepts
DePrompt focuses on three key attributes for prompt-based data anonymization: semantic relevance, subject linkage, and entropy uncertainty. These attributes guide the design of the adversarial generative desensitization method, ensuring a balance between privacy and usability.
Experimental Design
Large Language Model Fine-Tuning
The fine-tuning process involves collecting prompt datasets with distinct scene characteristics, designing specific prompts for fine-tuning, and using LORA (Low-Rank Adaptation) for model training. This enables the model to comprehend complex scenarios and generate adversarial text that maintains contextual consistency.
Entity Extraction
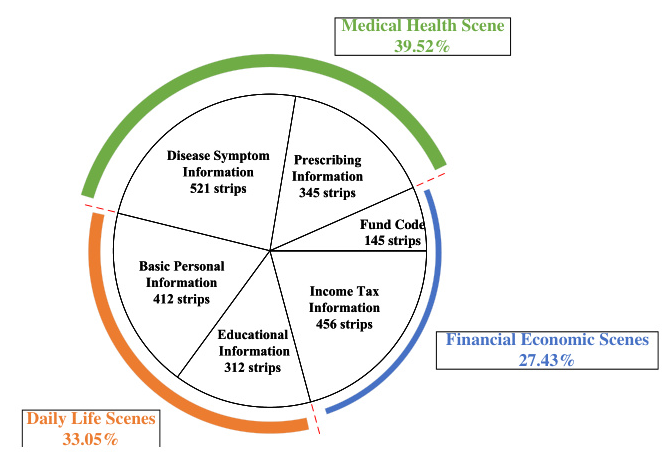
Entity extraction involves two main steps: semantic entity extraction using the TextRank algorithm and privacy entity extraction based on predefined privacy definitions for various scenarios (e.g., medical, daily, financial). This results in privacy entity vectors that guide the desensitization process.
Adversarial Generative Desensitization
The desensitization process involves three main steps:
- Semanticity: Traditional scrub techniques are applied to semantically unrelated entities.
- Linkability: Generative replacement is used for semantically linked identifiers, disrupting the linkage between users and their private attributes.
- Uncertainty: Adversarial techniques are employed to perturb private attributes, making it difficult for traditional Named Entity Recognition (NER) techniques to extract private information.
Results and Analysis
Named Entity Recognition
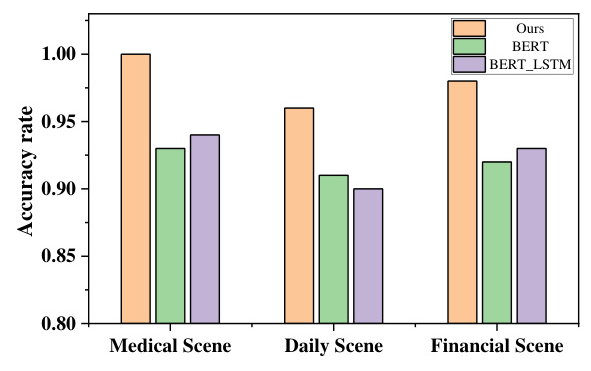
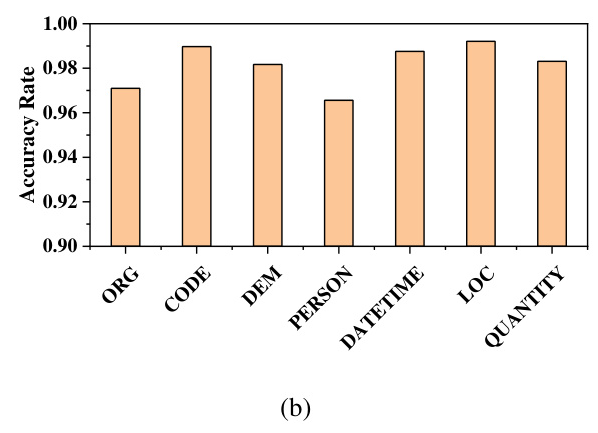
The DePrompt framework demonstrates superior accuracy in scene recognition tasks compared to BERT and BERT_LSTM models, achieving an overall accuracy of 98%. The highest predictive accuracy is observed in the medical domain, attributed to the prevalence of specialized medical terminologies.
Private Entity Extraction
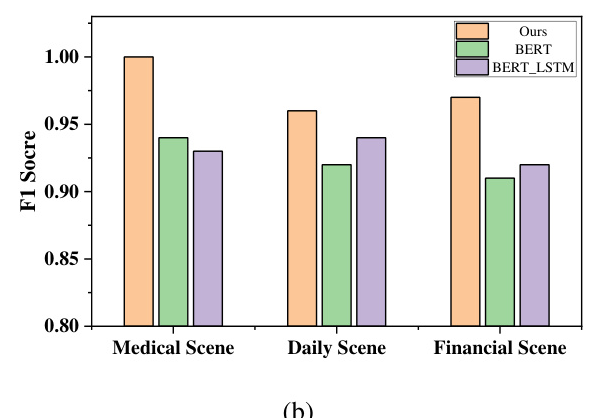
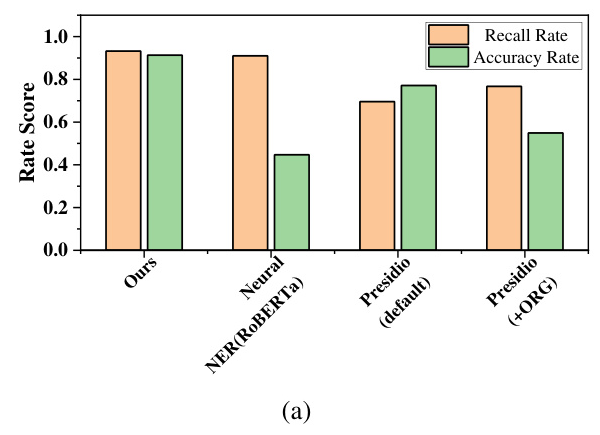
DePrompt outperforms BERT_CRF and BERT_LSTM_CRF models in privacy entity recognition tasks, achieving an overall accuracy of 96%. The framework also demonstrates effectiveness on benchmark datasets, showing advantages in both accuracy and recall.
Privacy and Utility Evaluation
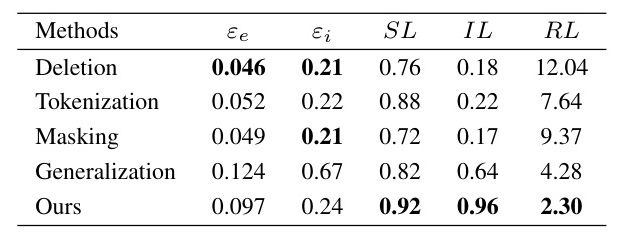
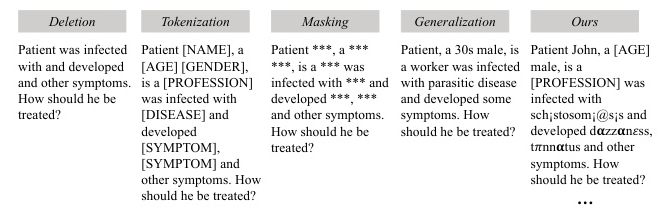
DePrompt achieves a favorable balance between privacy and usability compared to traditional anonymization methods such as deletion, tokenization, masking, and generalization. While traditional methods often result in significant losses in prompt usability, DePrompt’s adversarial generative approach effectively disrupts the linkage between identifiers and attributes, reducing privacy risks while maintaining prompt usability.
Overall Conclusion
The DePrompt framework addresses the critical issue of PII leakage in LLM prompts by leveraging fine-tuning techniques and adversarial generative desensitization methods. The framework achieves high-precision PII entity identification and maintains a balance between privacy and usability. Experimental results demonstrate the superiority of DePrompt in terms of entity recognition performance and its ability to protect privacy while preserving prompt usability. Future work could explore expanding the framework to a wider range of contexts where semantic understanding is crucial.