Authors:
Zhirong Huang、Shichao Zhang、Debo Cheng、Jiuyong Li、Lin Liu、Guixian Zhang
Paper:
https://arxiv.org/abs/2408.09646
Introduction
Recommender systems have become an integral part of many online services, from e-commerce platforms like Amazon to streaming services like Netflix. These systems aim to predict user preferences and recommend items that align with those preferences. However, traditional recommender systems often suffer from biases, particularly popularity bias and conformity bias. Popularity bias leads to the over-representation of popular items, while conformity bias causes users to align their choices with the group, even if it conflicts with their personal preferences. This paper introduces a novel framework, Debiased Contrastive Learning for Mitigating Dual Biases (DCLMDB), to address these issues.
Related Work
Traditional Recommendation Methods
Traditional collaborative filtering methods, such as Matrix Factorisation (MF) and Neural network-based Collaborative Filtering (NCF), focus on learning user and item embeddings to make predictions. These methods often overlook biases, inadvertently amplifying them during training.
Causal Recommendation Methods
Causal inference-based solutions have emerged to address biases in recommender systems. Methods like Inverse Propensity Scoring (IPS) and Disentangling Interest and Conformity with Causal Embedding (DICE) have been developed to tackle popularity and conformity biases, respectively. However, these methods do not address both biases simultaneously.
Research Methodology
Problem Setting and Causal Analysis
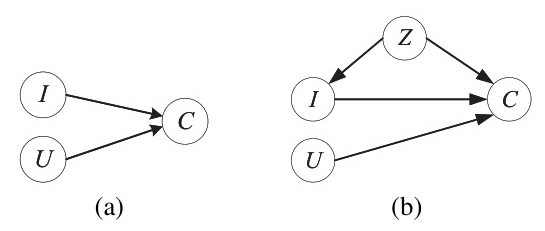
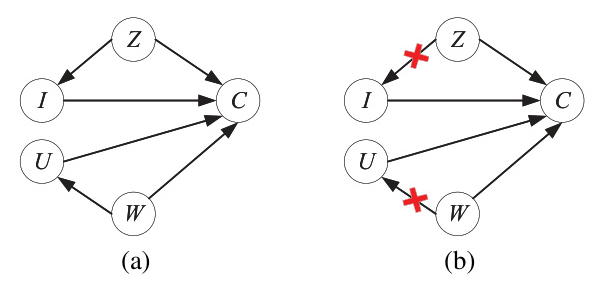
In a recommender system, user behavior data often does not reflect real user preferences due to biases. The paper proposes a new causal graph to analyze the dual biases. The graph includes nodes for user preference (U), exposed item (I), item popularity (Z), and conformity influence (W). The relationships between these nodes are represented by edges, which are manipulated to remove biases.
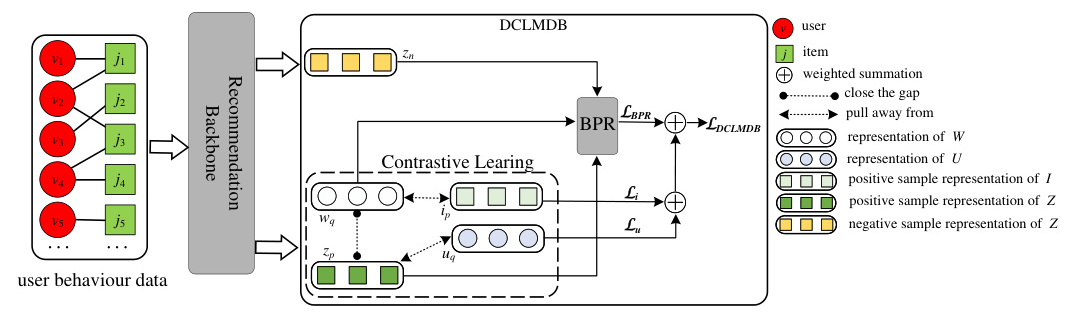
Mitigating Dual Biases with Causal Inference
To mitigate both popularity and conformity biases, the paper proposes performing a “do” operation on I and U, effectively removing the influence of Z and W. This is achieved through contrastive representation learning, which distances the embeddings of Z and W from I and U, respectively.
Experimental Design
Datasets
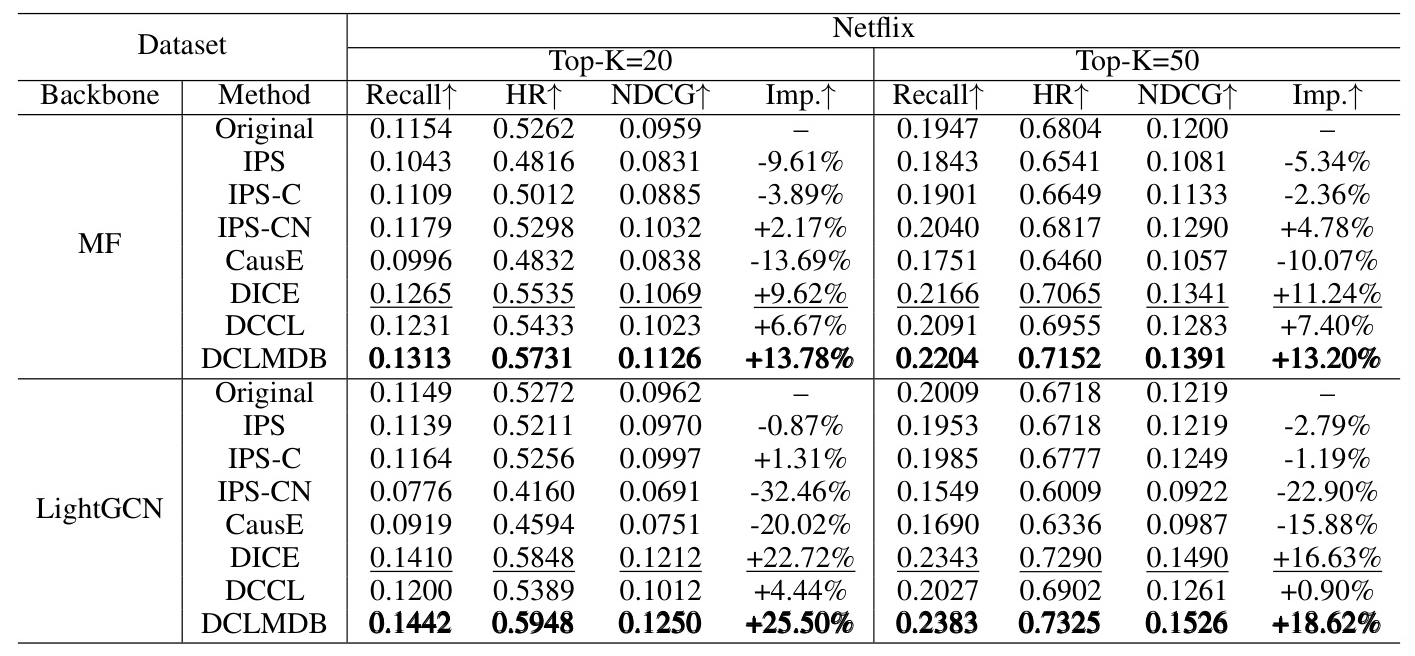
The experiments were conducted on two real-world datasets: Movielens-10M and Netflix. Both datasets were preprocessed to ensure that test data are not influenced by item popularity, providing a realistic evaluation environment.
Baseline Methods
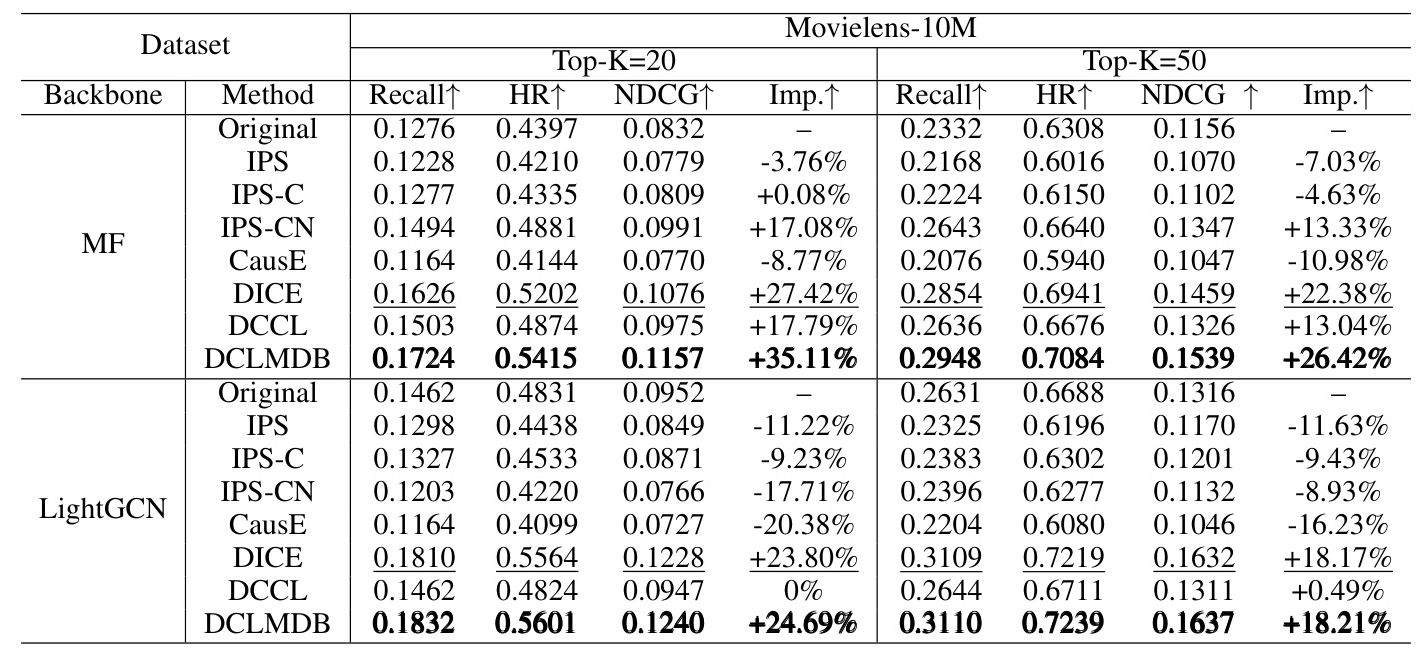
The performance of DCLMDB was compared against several causal debiasing methods, including IPS, IPS-C, IPS-CN, CauseE, DICE, and DCCL. These methods were evaluated using two backbone recommendation models: MF and LightGCN.
Evaluation Metrics
The performance was evaluated using three metrics: Recall, Hit Rate (HR), and NDCG. Additionally, the degree of improvement of Recall for each method compared to the backbone was measured.
Results and Analysis
Comparison of Experimental Results
The results showed that DCLMDB outperformed all baseline methods across all metrics on both datasets. For example, on the Movielens-10M dataset, DCLMDB showed an increase of over 35% in the Recall@20 metric and more than 26% improvement in Recall@50 when using MF as the backbone.
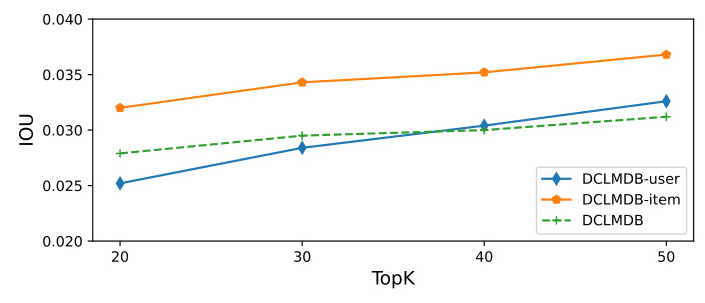
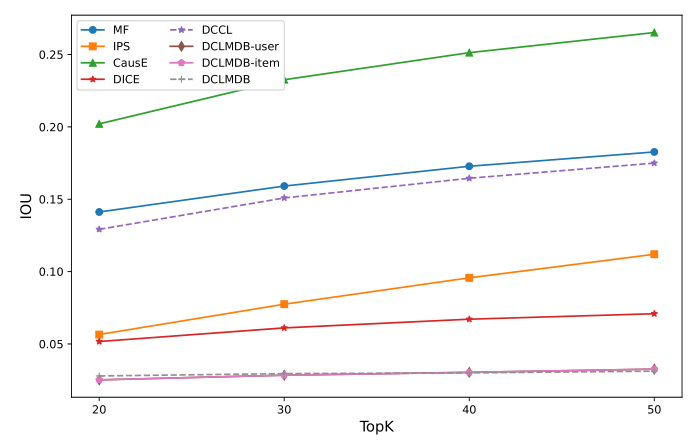
Ablation Experiments
Ablation experiments were conducted to validate the debiasing effect of each component of DCLMDB. The results indicated that both DCLMDB-user and DCLMDB-item variants exhibited lower overlap ratios between their recommended items and popular items compared to other baselines, highlighting their effectiveness in removing biases.
Overall Conclusion
This paper presents a novel framework, DCLMDB, to simultaneously mitigate popularity and conformity biases in recommender systems. The framework employs contrastive learning to distance the embeddings of item popularity and conformity influence from user preferences and exposed items. Extensive experiments on real-world datasets demonstrate that DCLMDB significantly improves recommendation accuracy and diversity, outperforming existing methods. This work provides a robust and effective solution for enhancing the fairness and effectiveness of recommender systems.