Authors:
Nursena Koprucu、Meher Shashwat Nigam、Shicheng Xu、Biruk Abere、Gabriele Dominici、Andrew Rodriguez、Sharvaree Vadgam、Berfin Inal、Alberto Tono
Paper:
https://arxiv.org/abs/2408.06693
Introduction
Recent advancements in deep generative models have significantly improved performance in both classification and out-of-distribution (OOD) classification for images. Inspired by Geoffrey Hinton’s emphasis on generative modeling, this paper explores the use of 3D diffusion models for object classification. The proposed approach, “Diffusion Classifier for 3D Objects” (DC3DO), leverages the density estimates from these models to enable zero-shot classification of 3D shapes without additional training. This method demonstrates a 12.5% improvement on average compared to its multi-view counterparts, showcasing superior multimodal reasoning.
Methodology
Multi-View Diffusion Classifier (MVDC)
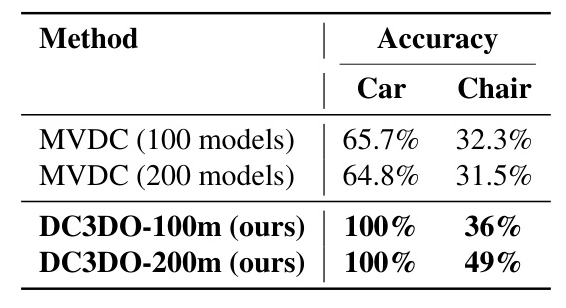
The Multi-View Diffusion Classifier (MVDC) represents 3D objects as a series of images, providing a straightforward baseline for extending previous work to the 3D domain. By aggregating multiple views of the same object, existing diffusion-based classification techniques can be adapted for 3D shapes. The ShapeNet dataset was utilized for experiments, focusing on a subset of 200 models per class due to computational constraints.
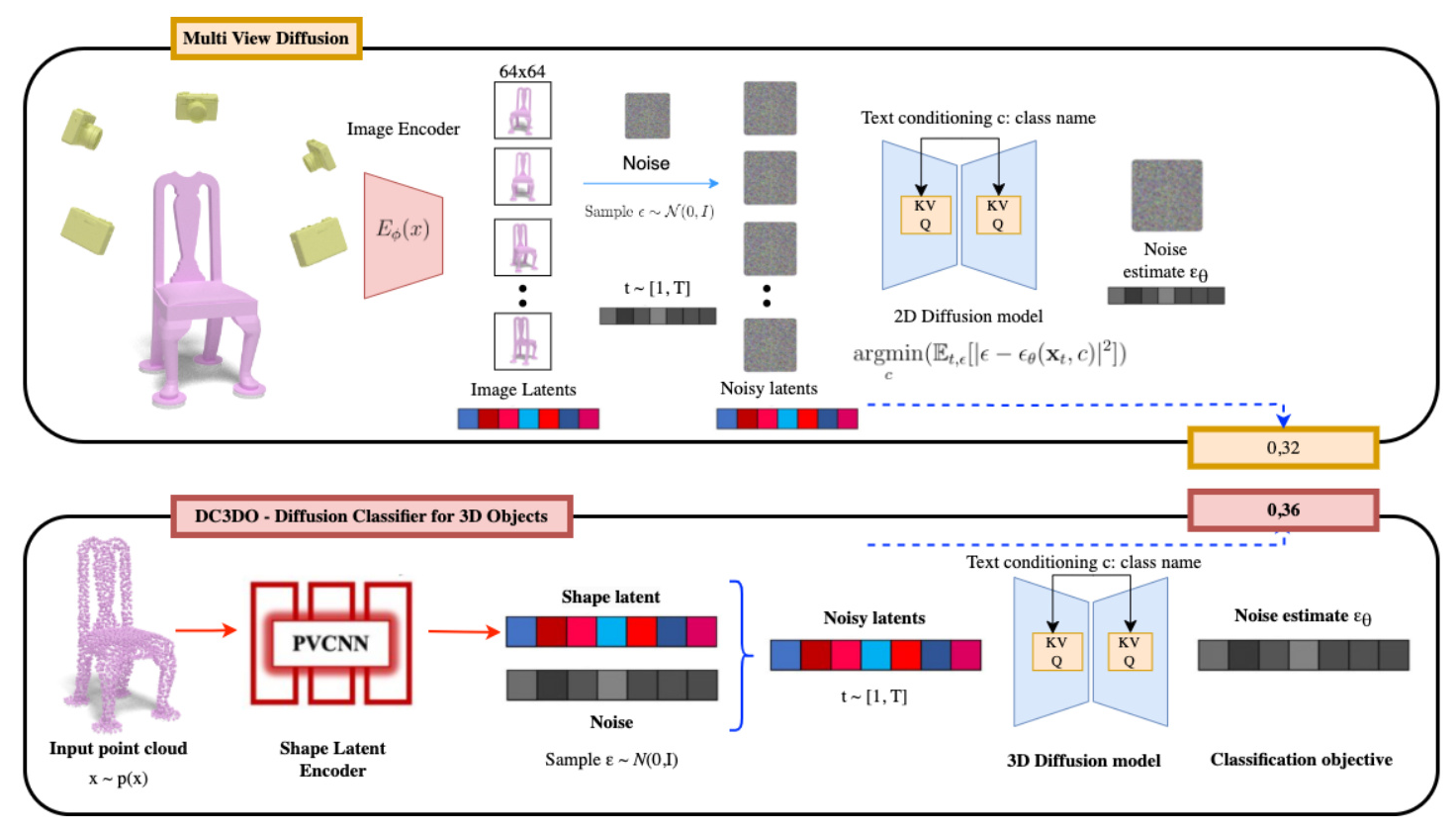
Diffusion Classifier for 3D Objects (DC3DO)
DC3DO combines LION’s generative capabilities with diffusion-based classification, targeting zero-shot classification of complex 3D shapes like cars and chairs. The integration of LION with diffusion models involves encoding 3D point cloud data into a hierarchical latent space, followed by a diffusion process that adds Gaussian noise to the latent representations. The denoising process retrieves the latent representations that best match the original data distribution, and classification is performed by evaluating the likelihood of the denoised data belonging to specific classes.
Experimental Results
MVDC – 2D Results
In the baseline evaluation, a multi-view diffusion classifier was utilized on the ShapeNet dataset, focusing on cars, chairs, and airplanes. This approach enhanced classification accuracy by taking advantage of the rich spatial information in the dataset. The process involved encoding 3D shapes into latent representations, adding Gaussian noise, and employing a UNet model for denoising and classification.

DC3DO Inference
DC3DO utilized pretrained models from LION, focusing on the “chairs” and “cars” categories. Due to computational constraints, the number of diffusion steps was set to 200. The experiments employed a batch size of 1 for the “cars” and “chairs” categories, with each object classification taking approximately 20 seconds.
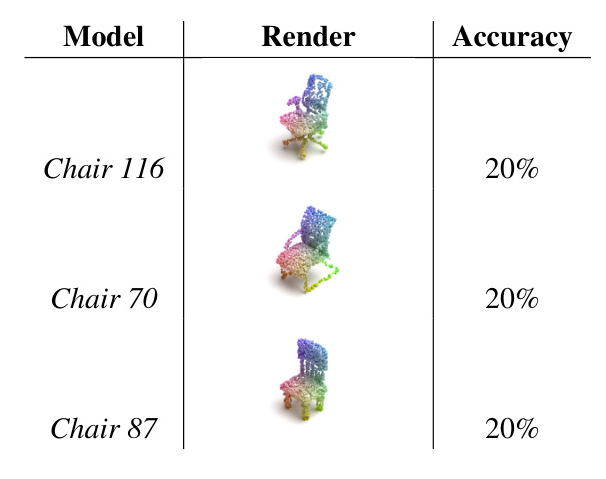
Ablation Studies
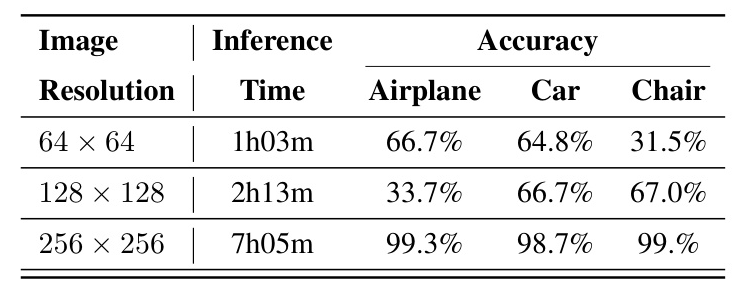
Ablation studies were conducted to gain deeper insights into the contributions of different components in the model. For the MVDC model, the diffusion process time increased non-linearly with both image size and the number of views. Larger image sizes and an increased number of views resulted in significantly slower processing. The classifier’s performance degraded severely with reduced image resolutions, indicating a loss of ability to differentiate between classes.
Limitations
One of the primary limitations of the approach is the computational cost. The 3D diffusion process requires approximately 20 minutes per object on a T4 GPU, making it time-intensive. The multi-view approach is also relatively slow due to the independent processing of each view. Additionally, the views are processed individually and then aggregated through a majority vote, which may not fully capture the holistic structure of 3D shapes.
Discussion and Future Work
The high classification accuracy on ID data indicates that the model effectively captures the distinguishing features of various 3D objects. The hierarchical latent space of LION played a crucial role in accurately representing both global and local features of 3D shapes. The diffusion process further enhanced the model’s ability to denoise and classify complex 3D structures, providing a reliable mechanism for zero-shot classification.
Future work could explore 3D diffusion capabilities in state-of-the-art multimodal methods, potentially enhancing the performance of these architectures and making them capable of 3D understanding.
Conclusion
This paper proposes a model that integrates LION with a diffusion classifier to achieve accurate classification of 3D cars and chairs. The model’s success is driven by the hierarchical latent space and diffusion process, enabling precise representation and classification of complex 3D shapes from the ShapeNet dataset. The approach, named DC3DO, demonstrates a 12.5% improvement on average compared to multi-view methods, highlighting the potential of generative models in 3D object classification.
Acknowledgments
The authors express gratitude to Alexander C. Li and Le Xue for their insightful initial discussions, and to the mentors and volunteers of the Summer Geometric Initiative (SGI) at MIT for their invaluable guidance. Special thanks to Professor Justin Solomon for coordination and funding support, Google Cloud for providing credits and sponsorship, and Paul Guerrero for sharing the render file used in the previous SGI.