Authors:
Zhirong Huang、Shichao Zhang、Debo Cheng、Jiuyong Li、Lin Liu、Guangquan Lu
Paper:
https://arxiv.org/abs/2408.09651
Introduction
Background
With the rapid expansion of the internet, the volume of available information has grown exponentially, making it increasingly challenging for users to find content that aligns with their preferences. Recommender systems have emerged as a crucial solution to this problem by analyzing user behavior data to deliver personalized recommendations, thereby enhancing user engagement and satisfaction. These systems are integral to many digital platforms, including e-commerce, streaming media, and social networks, significantly improving information retrieval efficiency and user experience.
Problem Statement
Despite their success, recommender systems often suffer from biases introduced by latent variables, which can distort user-item interaction data and lead to inaccurate recommendations. Traditional methods like Matrix Factorization (MF) and Neural Network-based Collaborative Filtering (NCF) assume that user behavior data is unbiased, which is rarely the case in real-world scenarios. This bias can compromise both recommendation accuracy and user satisfaction.
Proposed Solution
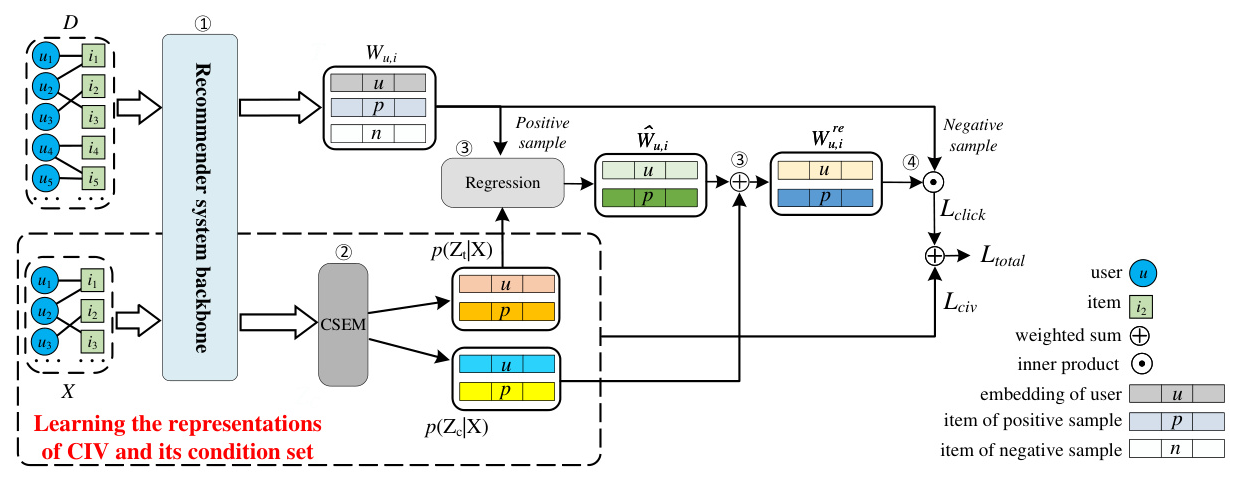
To address this issue, the paper proposes a novel data-driven conditional instrumental variable (CIV) debiasing method for recommender systems, called CIV4Rec. This method automatically generates valid CIVs and their corresponding conditioning sets directly from interaction data, significantly reducing the complexity of IV selection while effectively mitigating the confounding bias caused by latent variables.
Related Work
Traditional Recommender Methods
Traditional recommender methods, primarily based on Collaborative Filtering (CF), typically assume that user behavior data is unbiased. These methods include:
- Matrix Factorization (MF): Decomposes the user-item rating matrix to predict preferences.
- Bayesian Personalized Ranking (BPR): Assumes users prefer selected items over unselected ones, enhancing preference inference in MF.
- Neural Collaborative Filtering (NCF): Uses multi-layer perceptrons (MLPs) to model non-linear user preferences.
- Neural Graph Collaborative Filtering (NGCF): Leverages Graph Convolutional Networks (GCNs) to enhance recommendations by embedding user-item interactions.
- LightGCN: A simplified model that improves efficiency and performance.
Despite their success, these methods often overlook biases like popularity bias, which can be amplified during training, leading models to overemphasize popular items.
Causal Recommender Methods
To mitigate biases, researchers have increasingly adopted causal inference techniques:
- Inverse Propensity Score (IPS): Reduces bias by assigning an inverse propensity score to user-item interactions during training.
- Causal Graph-based Methods: Model the generation mechanisms of user behavior to address biases like popularity and conformity bias.
- Instrumental Variables (IVs): Used to eliminate bias caused by latent variables. Recent methods leverage user search data as IVs, such as the IV4Rec framework.
However, identifying valid IVs remains challenging, and existing methods often come with strong assumptions that may not hold in real-world scenarios.
Research Methodology
Problem Definition
In a recommender system, user behavior data consists of a user set ( U ) and an item set ( I ). The data contains positive sample pairs (user ( u ) and selected items ( p )) and negative sample pairs (user ( u ) and pre-selected items ( n )). The user interaction data ( X ) implicitly contains information, including user interactions stemming from search behaviors.
The goal is to learn the representations of the CIV ( Z_t ) and its conditional set ( Z_c ) from the user interaction data ( X ) to address the confounding biases introduced by latent variables ( U_c ).
Proposed Causal DAG
The proposed causal DAG represents the causal relationships between measured and latent variables. The DAG ensures that ( Z_t ) captures the CIV information, while ( Z_c ) captures the confounding information given ( X ) in the interactive data.
Concepts of Treatment Variable, CIV, and Its Conditional Set
- Treatment Variable ( W_{u,i} ): Defined using user-item pairs.
- CIV Representations ( Z_t ): Learned from the user interaction data ( X ).
- Conditional Set Representations ( Z_c ): Also learned from ( X ).
Learning the Representations
The CIV4Rec method employs a Variational Autoencoder (VAE) structure to generate the representations of the CIV ( Z_t ) and its conditional set ( Z_c ) from the user interaction data ( X ). The inference and generation networks of VAE approximate the posterior distributions for the two representations.
Decomposition of Treatment Variable
After obtaining the representations of CIV ( Z_t ) and its conditional set ( Z_c ), the CIV ( Z_t ) is used to reconstruct the treatment variable ( W ) and decompose ( W ) to derive the causal relationship, specifically user preference.
Click Prediction
Click prediction is the core task of a recommender system. The BPR loss is used to optimize the reconstructed treatment variables to enhance click prediction. The final loss function of CIV4Rec combines the evidence lower bound (ELBO) and BPR.
Experimental Design
Datasets
The experiments were conducted on two publicly available real-world datasets: Movielens-10M and Douban-Movie. Both datasets include user IDs, movie IDs, and user ratings (1-5) for movies. The datasets were binarized based on movie ratings, and ten-core filtering was applied.
Baselines
The mainstream recommendation models, MF and LightGCN, were used as the backbone. The following five debiased recommendation methods based on causality were compared:
- IPS: Assigns weights that are the inverse of an item’s popularity.
- IPS-C: Caps the maximum value of IPS weights to reduce variance.
- CausE: Generates two sets of embeddings from the data, aligned using regularization techniques.
- DICE: Uses Structural Causal Modeling (SCM) to define user-item interactions.
- DCCL: Uses contrastive learning to address data sparsity.
Metrics
Top-K recommendation performance on implicit feedback was evaluated using three metrics: Recall, Hit Rate (HR), and NDCG.
Results and Analysis
Comparison of Experimental Results
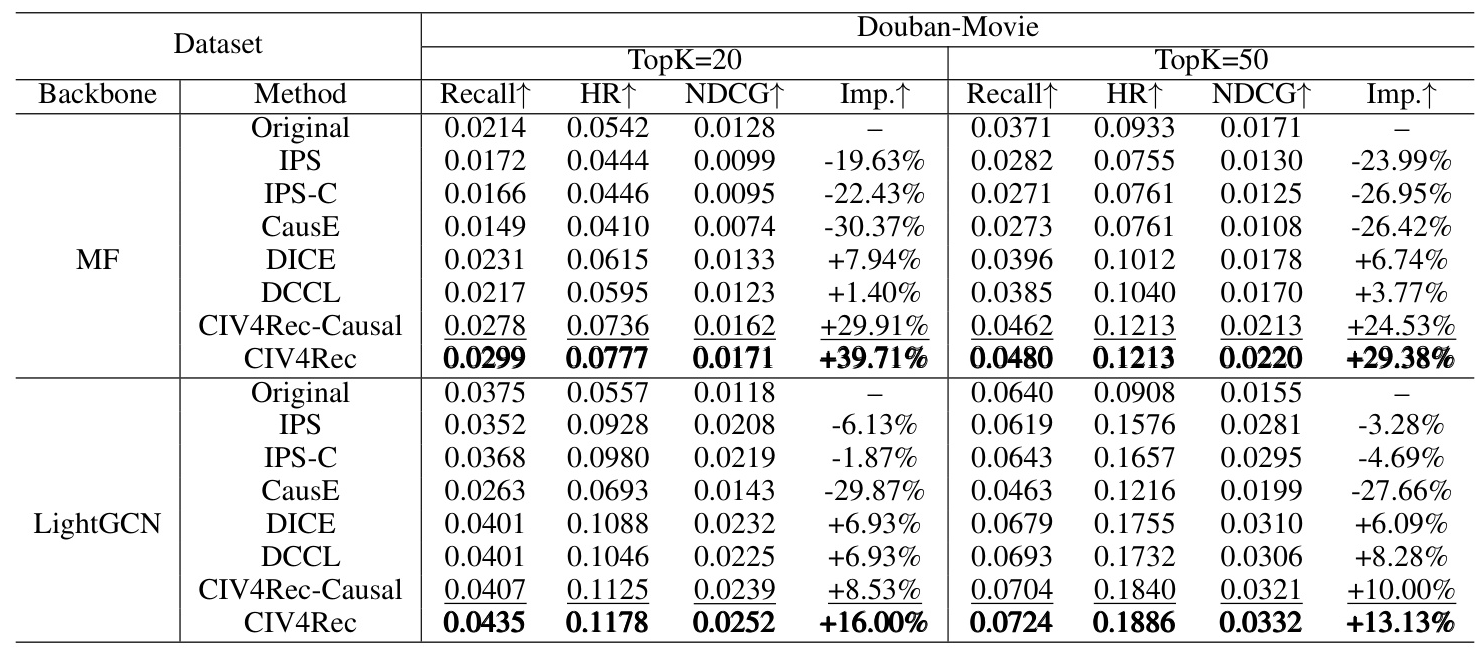
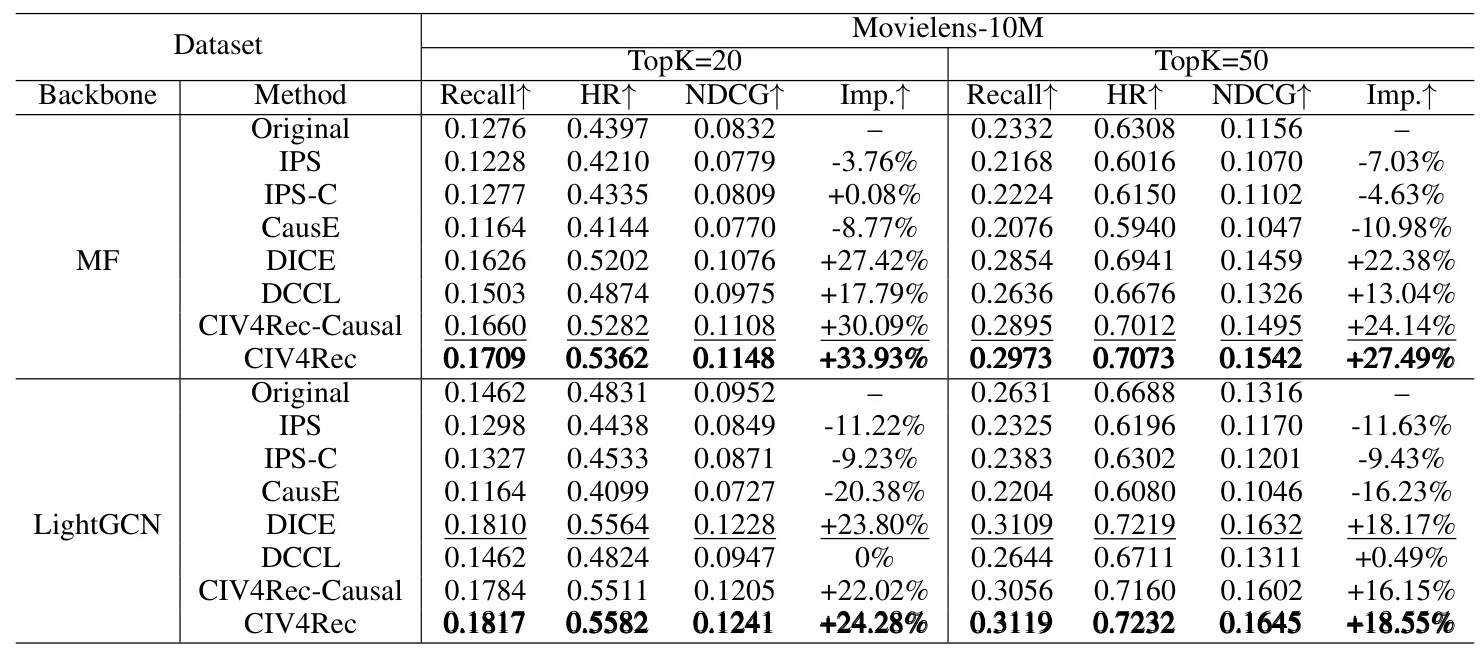
Tables 2 and 3 present the results of CIV4Rec and all baseline approaches on two real-world datasets. CIV4Rec and its variant CIV4Rec-Causal significantly improve performance metrics compared to the original backbone, demonstrating statistical significance and the superiority of the approach.
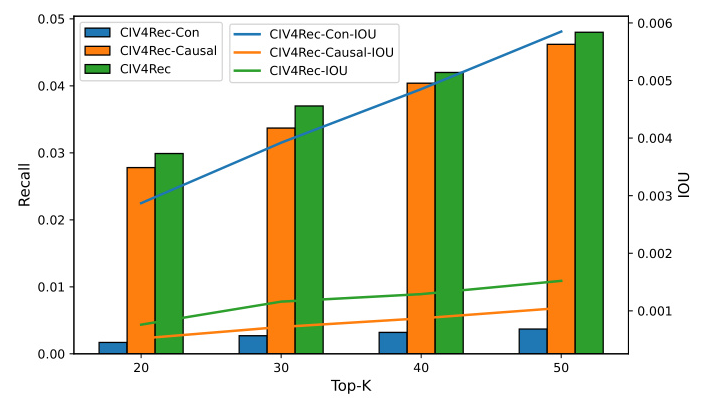
Evaluation on Debiasing Ability
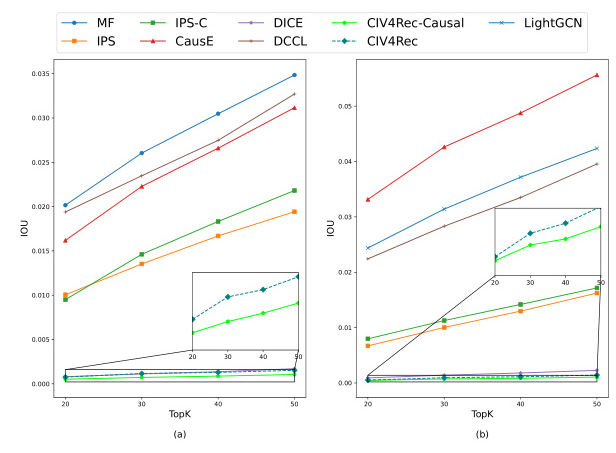
The Intersection Over Union (IOU) metric was used to evaluate the debiasing ability of all methods. CIV4Rec and CIV4Rec-Causal exhibit the lowest IOU, indicating superior debiasing ability. The debiasing ability of CIV4Rec remains relatively stable, demonstrating greater robustness.
Ablation Studies
Ablation studies were performed to evaluate the effectiveness of each component in CIV4Rec. The results show that integrating both user preference and confounding factor information achieves higher Recall and IOU, demonstrating the combined effectiveness of ( Z_t ) and ( Z_c ).
Overall Conclusion
The paper proposes a novel data-driven CIV debiasing method called CIV4Rec. By learning the representations of CIV and its conditional set from user interaction data, CIV4Rec effectively mitigates bias and improves recommendation accuracy. Extensive experiments on two real-world datasets validate the effectiveness and superiority of CIV4Rec in both recommendation and debiasing performance.