Authors:
Xiaoyu Kong、Jiancan Wu、An Zhang、Leheng Sheng、Hui Lin、Xiang Wang、Xiangnan He
Paper:
https://arxiv.org/abs/2408.10159
Introduction
Sequential recommendation systems aim to predict a user’s next item of interest by analyzing their past interactions, tailoring recommendations to individual preferences. Leveraging the strengths of Large Language Models (LLMs) in knowledge comprehension and reasoning, recent approaches have applied LLMs to sequential recommendation through language generation paradigms. These methods convert user behavior sequences into prompts for LLM fine-tuning, utilizing Low-Rank Adaptation (LoRA) modules to refine recommendations. However, the uniform application of LoRA across diverse user behaviors sometimes fails to capture individual variability, leading to suboptimal performance and negative transfer between disparate sequences.
To address these challenges, the paper proposes Instance-wise LoRA (iLoRA), integrating LoRA with the Mixture of Experts (MoE) framework. iLoRA creates a diverse array of experts, each capturing specific aspects of user preferences, and introduces a sequence representation guided gate function. This gate function processes historical interaction sequences to generate enriched representations, guiding the gating network to output customized expert participation weights. This tailored approach mitigates negative transfer and dynamically adjusts to diverse behavior patterns.
Related Work
LLM-based Sequential Recommendation
Sequential recommendation systems predict the next item that aligns with user preferences by analyzing historical interaction sequences. Recent efforts have applied LLMs to sequential recommendation tasks by converting user behavior sequences into input prompts, achieving remarkable success. These methods typically involve three components:
1. Converting a sequence of historical behaviors into a prompt.
2. Pairing these prompts with subsequent items of interest to create instruction-tuning datasets.
3. Incorporating a trainable LoRA module into LLMs and fine-tuning it on such prompts.
Fine-tuning with Low-rank Adaptation (LoRA)
LoRA is an efficient alternative to fully fine-tuning LLMs, injecting trainable low-rank matrices into transformer layers to approximate the updates of pre-trained weights. This methodology introduces a flexible and efficient means to customize models to new tasks, circumventing the need for extensive retraining of all model parameters.
Fine-tuning with Hybrid Prompting
A critical challenge in LLM-based sequential recommendation is the divergence between the natural language space and the “user behavior” space. Hybrid prompting incorporates behavioral insights captured by recommendation models into the prompts, combining textual token representation with behavior token representation learned from the recommender model.
Research Methodology
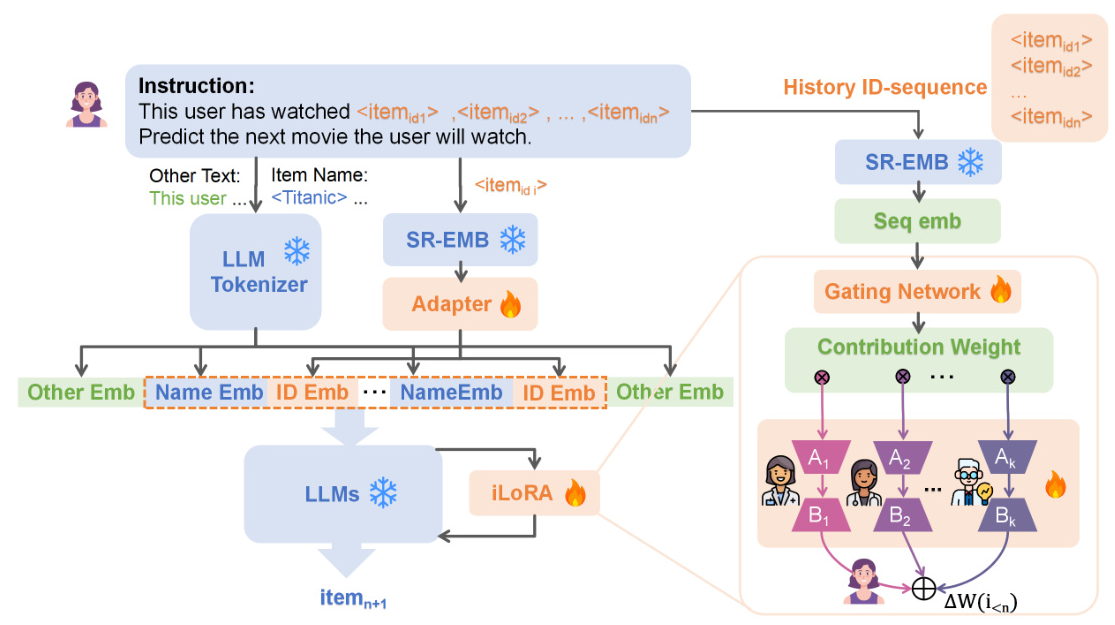
Instance-wise LoRA (iLoRA)
To address the issue of negative transfer associated with conventional LoRA fine-tuning, the paper introduces the Instance-wise LoRA (iLoRA) fine-tuning framework. This innovative approach adapts the Mixture of Experts (MoE) concept to tailor LLMs to individual characteristics in sequential recommendation. The key components of iLoRA include:
- Splitting Low-Rank Matrices into Experts: Dividing each projection matrix into an array of experts, each capturing a distinct aspect of user behavior.
- Generating Instance-wise Attentions over Experts: Using a gating network to obtain attention scores across the arrays of up- and down-projection experts for a given sequence instance.
- Aggregating Mixture of Experts as Instance-wise LoRA: Aggregating the up- and down-projection submatrices from different experts to establish the instance-wise LoRA parameters.
Experimental Design
Datasets and Baselines
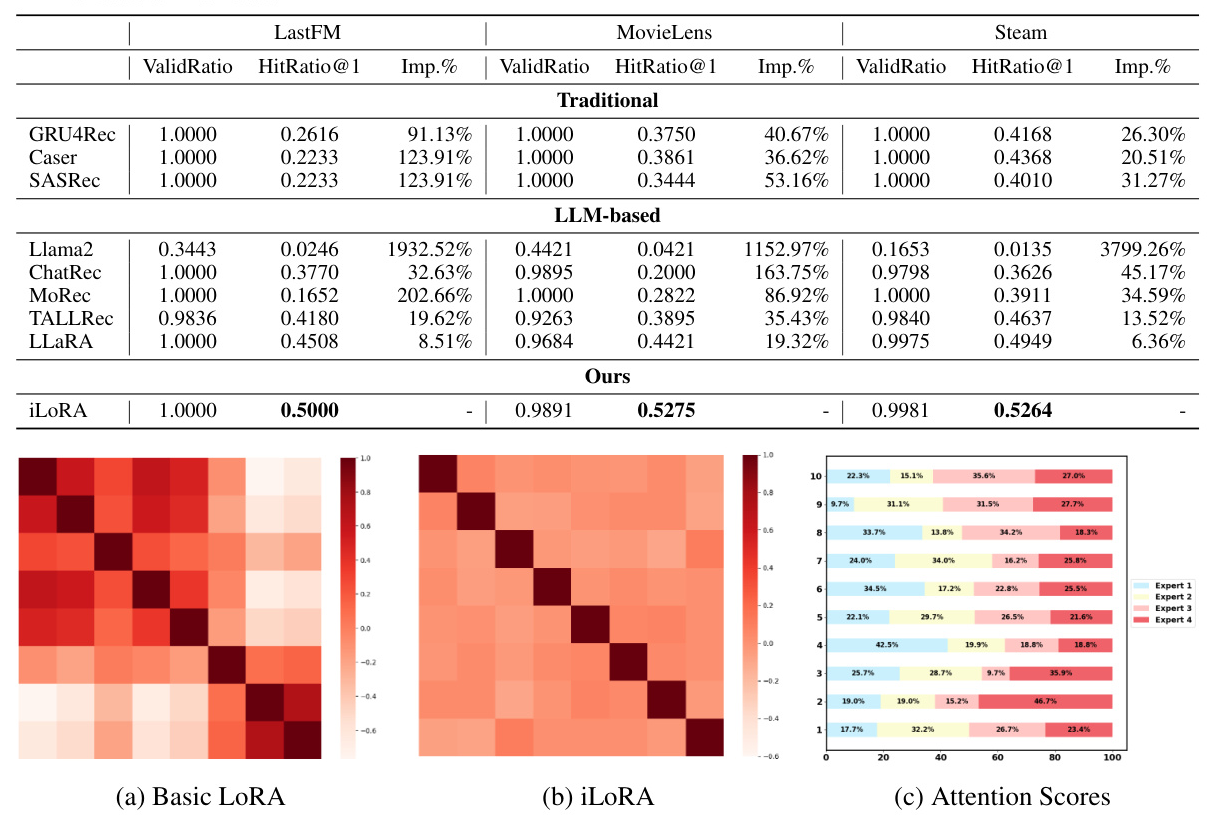
The effectiveness of iLoRA is assessed through extensive experiments on three benchmark sequential-recommendation datasets: LastFM, MovieLens, and Steam. The analysis includes detailed comparisons of iLoRA against established baseline models, encompassing both traditional sequential recommender models and LLM-based recommender models.
Evaluation Metrics
ValidRatio and HitRatio@1 are used as evaluation metrics to quantify the ratios of valid responses over all sequences and relevant items over all candidate items, reflecting the model’s capability of instruction following and recommendation accuracy.
Ablation Study
A thorough ablation study is performed to identify the key components that enhance iLoRA’s performance, focusing particularly on the role of the gating network and expert settings.
Results and Analysis
Negative Transfer in Uniform LoRA & Instance-wise LoRA
Gradient similarity reflects the proximity of recommendation sequences. The study explores whether using LLaRA to perform recommendations conditioned on different sequences exhibits similar loss geometries. The results indicate strong clustering along the diagonal of the gradient similarity matrix for closely related sequences, while distant sequences exhibit lower gradient similarity, leading to negative transfer. In contrast, iLoRA’s gradient similarity among identical clusters tends to achieve zero scores, indicating its capability to mitigate negative transfer.
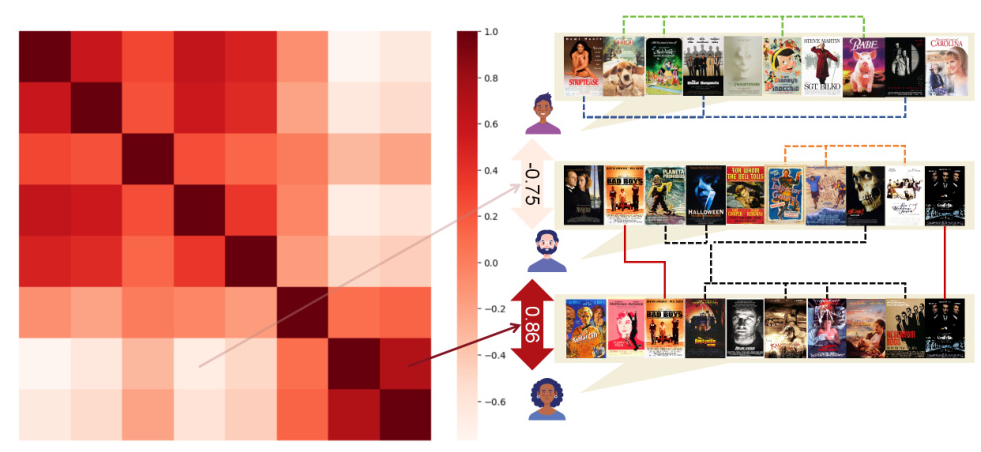
Expert Showcase in Instance-wise LoRA
The attention scores of iLoRA’s four experts for ten distinct sequences demonstrate significant variability in expert activation across different sequences. Certain experts have notably high contributions for specific sequences, while some sequences exhibit a more balanced distribution of activation weights among multiple experts, suggesting collaborative contributions.
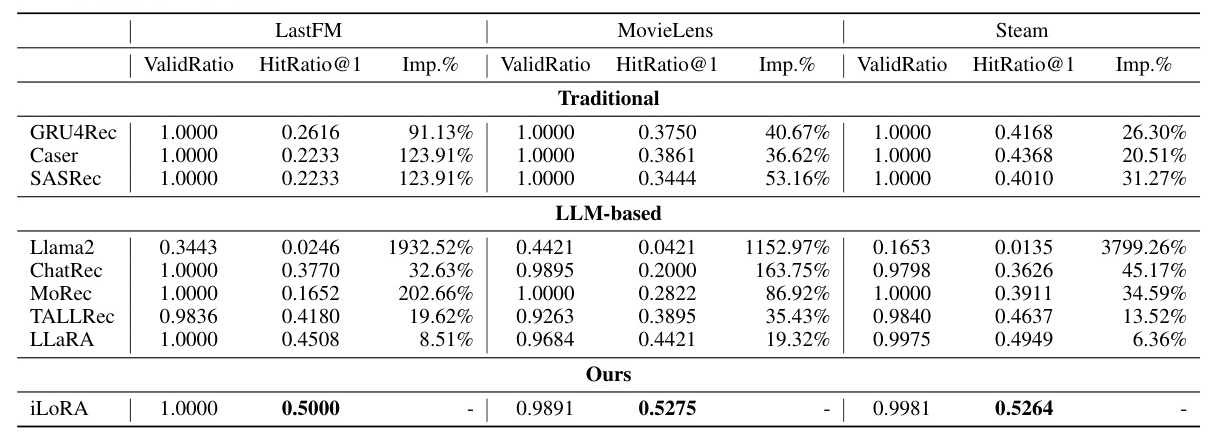
Performance Comparison
iLoRA consistently outperforms baseline models across the three datasets, achieving the highest HitRatio@1 metrics. These results demonstrate the efficacy of leveraging sequence representations as guidance signals to fine-tune LoRA parameters, enabling personalized recommendations at the parameter level.
Ablation Study
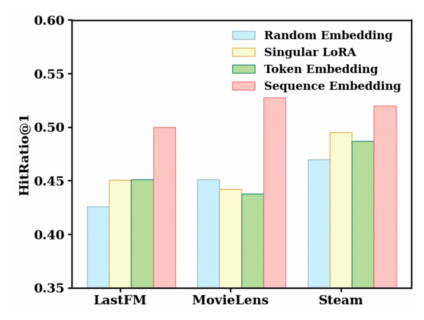
Effects of Gating Network
Using sequence representation as the guidance consistently outperforms other variants, illustrating the rationale of the gating network and the benefits for the MoE combination.
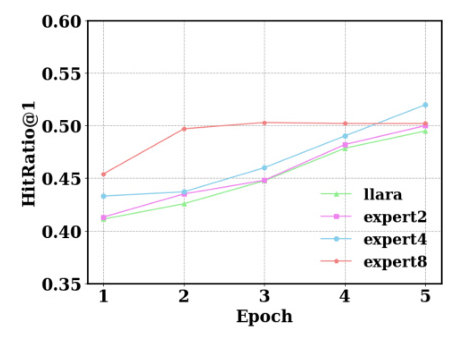
Effect of Expert Numbers
The model achieves optimal performance when the number of experts is set to 4. Increasing the number of task experts does not necessarily correlate with enhanced performance, and the benefits of increased capacity gradually converge as more experts are utilized.
Overall Conclusion
The paper introduces instance-wise LoRA (iLoRA), a novel fine-tuning framework designed to address the challenges posed by substantial individual variability in user behaviors within sequential recommendation systems. By integrating the mixture of experts (MoE) concept into the basic LoRA module, iLoRA dynamically adjusts to diverse user behaviors, thereby mitigating negative transfer issues observed with standard single-module LoRA approaches. iLoRA represents a significant advancement in the application of large language models to sequential recommendation tasks, providing a more nuanced and effective means of tailoring recommendations to individual user preferences.
Limitations and Broader Impact
Limitations
Several limitations are noted, including constraints on computational resources, limited exploration of a larger number of expert combinations, and the focus on sequential recommendation tasks. Further research is needed to fully understand the scalability and effectiveness of iLoRA with more complex expert configurations.
Broader Impact
iLoRA advances sequential recommendation systems by providing sequence-tailored recommendations, streamlining the user experience, reducing decision fatigue, and promoting inclusivity in online spaces. However, potential drawbacks include algorithmic biases, filter bubbles, and privacy concerns, necessitating careful consideration of ethical implications in its deployment.