

Authors:
Zhijun Jia、Huaying Xue、Xiulian Peng、Yan Lu
Paper:
https://arxiv.org/abs/2408.10096
Introduction
Accent conversion (AC) is a challenging task in speech processing that aims to transform the pronunciation and prosody of a speaker’s voice to match a target accent while preserving the linguistic content and speaker identity. This technology is crucial for improving communication between speakers of different accents, as it can help break down barriers of understanding. However, the lack of parallel data, where the same speaker utters the same content in different accents, poses a significant challenge for AC systems.
In this study, the authors propose a novel two-stage generative framework called “convert-and-speak” to address the AC problem with minimal supervision. The framework operates on the semantic token level for conversion and uses a speech generative model to synthesize speech in the target accent. This decoupling design allows the use of a large amount of target accent speech data without text transcriptions, significantly reducing the need for parallel data.
Related Work
Accent Conversion
Previous approaches to AC can be broadly categorized into two types:
-
End-to-End Mapping-Based Methods: These methods use voice conversion (VC) technology to synthesize parallel data by converting the speaker identity of the target accent speech to that of the source speaker. However, these methods require large amounts of strictly parallel data and often introduce distortions during the VC stage.
-
Disentanglement-Based Methods: These methods separate accent from content, speaker identity, and prosody, and then resynthesize the target waveform using a text-to-speech (TTS) model. While these methods reduce the dependence on parallel data, they still require large amounts of text-accent speech pairs and dedicated auxiliary tasks.
Speech Generative Models
Recent advancements in speech generative models have shown great potential in generating natural and diverse audio based on neural codecs. Models like AudioLM and VALL-E use autoregressive Transformer structures to build conditional correlations of acoustic features and semantic tokens. However, these models typically require multiple stages for generating codes, which increases complexity and latency.
Research Methodology
Overview
The proposed framework consists of two main stages: conversion and speaking. In the conversion stage, the source accent semantic tokens are converted to target accent semantic tokens using an autoregressive (AR) Transformer model. In the speaking stage, a generative-based synthesis model conditioned on the converted semantic tokens generates speech with prosody in the target accent.
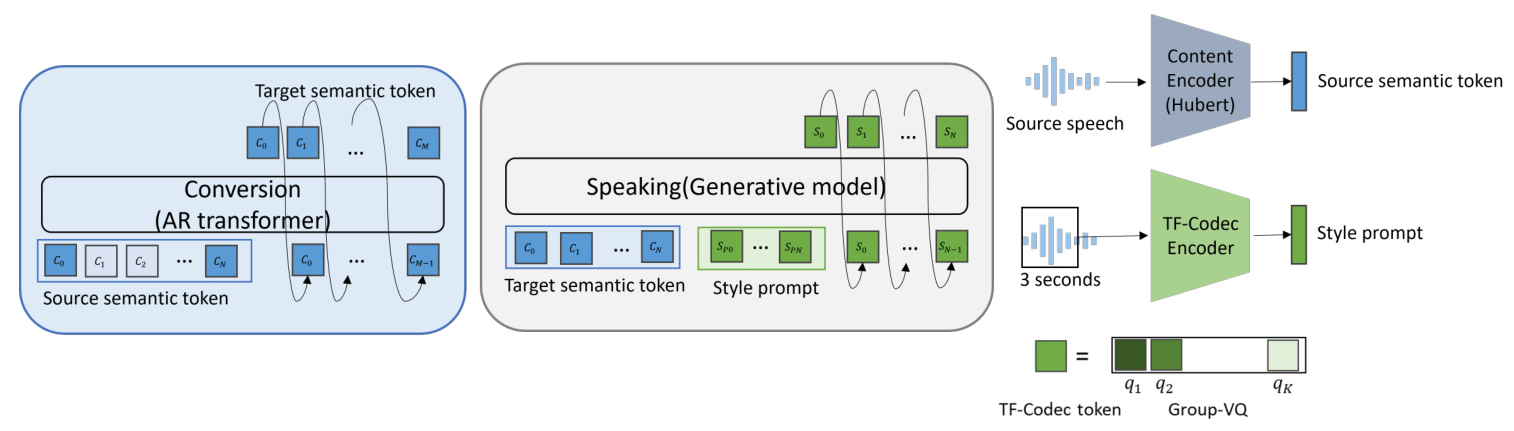
Semantic Token Conversion
The conversion module is designed as a sequence-to-sequence (seq2seq) task in the discrete semantic token space. To handle the shortage of parallel data, the authors use a pretext task inspired by BART and T5 pre-training techniques. The model is pre-trained on large amounts of target accent data to learn the probability space of discrete semantic tokens in the target accent domain. Fine-tuning is then performed on a small amount of weakly parallel data to learn the mapping between source and target accent phonemes.
Target Accent Speech Generation
The target accent speech generation is achieved using a single-stage autoregressive generative model based on TF-Codec. This model generates acoustic tokens iteratively through a single-stage causal speech generation, conditioned on the converted semantic tokens and a style prompt extracted from the source speech.
Experimental Design
Experimental Setup
The experiments focus on converting Indian-English accent to general American-English accent. The LibriTTS dataset is used for training the speech generative model and pre-training the conversion model, while the L1-L2 ARCTIC dataset is used for fine-tuning. The evaluation includes both objective and subjective metrics to assess accent similarity, speech quality, and speaker similarity.
Baseline Models
Three baseline models are used for comparison:
- An existing machine-learning-based AC method.
- A generative-only model based on EnCodec.
- A generative-only model based on TF-Codec.
Evaluation Methods
The performance of accent conversion is evaluated using the Longest Common Subsequence Ratio (LCSR) and an accent classification model (CommonAccent). Subjective A/B testing is also conducted to assess the perceived accent similarity. Speaker similarity is evaluated using cosine similarity of speaker vectors, and speech quality is assessed using NISQA-TTS and MOS testing.
Results and Analysis
Accent Similarity
The proposed framework achieves the highest MOS-Accent metric on both datasets, indicating superior accent conversion performance. The LCSR metric also shows that the proposed framework closely approaches the ground truth after conversion.


Speech Quality and Speaker Similarity
The proposed framework ranks at the top level in terms of NISQA-TTS and MOS-Naturalness metrics. It also achieves better speaker similarity compared to the baseline models, although the SPK value drops slightly due to the improved accent conversion.
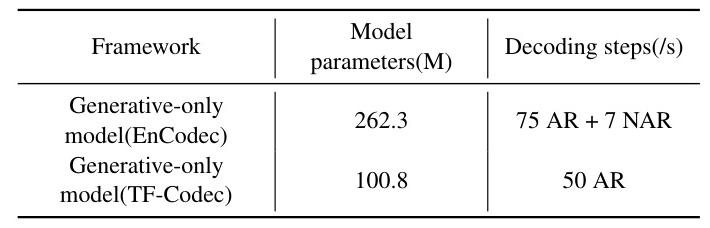
Efficiency of Single-Stage Causal Speech Generation
The TF-Codec-based generative model demonstrates lower complexity and latency compared to the EnCodec-based multi-stage generative model, making it more efficient for speech generation tasks.
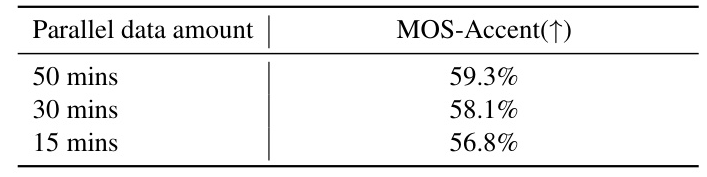
Training with Minimum Supervision
The proposed framework maintains good performance even with reduced amounts of parallel data, showing its potential for extension to other low-resource accents.
Supportive Analysis
The analysis shows that HuBERT tokens are affected by the source accent, highlighting the necessity of the semantic conversion module. The accent effect on the style prompt is minimal, allowing the use of a short prompt to capture the source speaker’s identity without bringing the source accent back to the converted speech.


Overall Conclusion
The proposed two-stage generative framework for accent conversion demonstrates state-of-the-art performance in terms of accent similarity, speech quality, and speaker maintenance with minimal parallel data. The use of language pre-training technology and a single-stage AR generative model significantly reduces the complexity and latency of the speech generation process. This framework shows great potential for extending to other low-resource accents, making it a valuable contribution to the field of speech processing.
