

Authors:
Lulu Yu、Keping Bi、Shiyu Ni、Jiafeng Guo
Paper:
https://arxiv.org/abs/2408.09817
Introduction
Background
Learning to Rank (LTR) is a critical component in many real-world systems, such as search engines and recommendation systems. Traditionally, LTR relies on human annotations to train models, where experts label the relevance of documents. However, obtaining these annotations is costly and may not always align with user preferences. Consequently, researchers have turned to implicit user feedback, such as clicks, to optimize ranking models.
Problem Statement
While implicit feedback is valuable, it is inherently biased due to factors like position bias, trust bias, and contextual bias. Unbiased Learning to Rank (ULTR) methods aim to mitigate these biases to develop more accurate ranking models. Despite the effectiveness of existing ULTR methods on synthetic datasets, their performance on real-world click data remains uncertain. This study addresses this gap by evaluating ULTR methods on a real-world dataset and proposing a novel approach to tackle both position and contextual biases.
Related Work
Unbiased Learning to Rank (ULTR)
ULTR methods leverage biased user feedback to optimize LTR systems. There are two primary streams in ULTR research:
- Click Models: These models assume user browsing behavior to estimate examination probability. Reliable relevance estimation requires the same query-document pair to appear multiple times, which is challenging for long-tail queries and sparse systems.
- Counterfactual Learning: This approach addresses bias using inverse propensity scores. The Dual Learning Algorithm (DLA) is a notable method in this stream, jointly learning an unbiased ranking model and an unbiased propensity model.
ULTR on the Baidu-ULTR Dataset
Recent research on the Baidu-ULTR dataset has focused on public competitions like the WSDM Cup 2023 and the ULTRE-2 task at NTCIR-17. These studies have improved performance by combining BERT model outputs with traditional LTR features or pseudo relevance feedback. However, the effectiveness of ULTR methods on real-world click data has not been extensively explored.
Research Methodology
Problem Formulation
For a user query ( q ), ( \pi_q ) is the ranked list of documents. Let ( d_i \in \pi_q ) be a document at position ( i ) and ( x_i ) be the feature vector of the ( q – d_i ) pair. Binary variables ( r_i ), ( e_i ), and ( c_i ) denote whether ( d_i ) is relevant, examined, and clicked, respectively. The goal is to find a function ( f ) mapping ( x_i ) to ( r_i ).
Dual Learning Algorithm (DLA)
DLA addresses the examination hypothesis by jointly learning an unbiased ranking model ( f ) and an unbiased propensity model ( g ). The local loss functions for DLA are:
[
\mathcal{L}{IPW}(f, q | \pi_q) = -\sum{d_i \in \pi_q, c_i = 1} \frac{g(1)}{g(i)} \log \frac{e^{f(x_i)}}{\sum_{z_j \in \pi_q} e^{f(x_j)}}
]
[
\mathcal{L}{IRW}(g, q | \pi_q) = -\sum{d_i \in \pi_q, c_i = 1} \frac{f(x_1)}{f(x_i)} \log \frac{e^{g(i)}}{\sum_{z_j \in \pi_q} e^{g(j)}}
]
Experimental Design
Overview of CDLA-LD
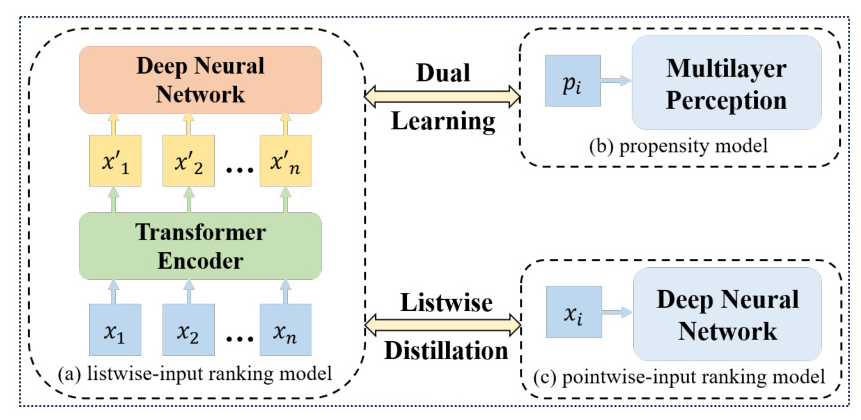
The proposed Contextual Dual Learning Algorithm with Listwise Distillation (CDLA-LD) consists of two main components:
- Contextual Dual Learning Algorithm (CDLA): Utilizes a Transformer Encoder to integrate contextual information and jointly trains an unbiased listwise-input ranking model and a propensity model.
- Listwise Distillation (LD): Trains a pointwise-input ranking model to distill the relevance judgment capabilities of the listwise-input ranking model.
Datasets
Experiments are conducted on a subset of the Baidu-ULTR dataset, which includes over a million search sessions with click information and expert-annotated queries. The dataset is split into training, validation, and test sets.
Baselines
The performance of CDLA-LD is compared with several baselines, including:
- Naive: Directly trains the model with clicks without debiasing.
- IPW: Inverse Propensity Weighting.
- DLA: Dual Learning Algorithm.
- XPA: Cross-Positional Attention.
- UPE: Unconfounded Propensity Estimation.
- IBOM-DLA: Interactional Observation-Based Model integrated with DLA.
Evaluation Metrics
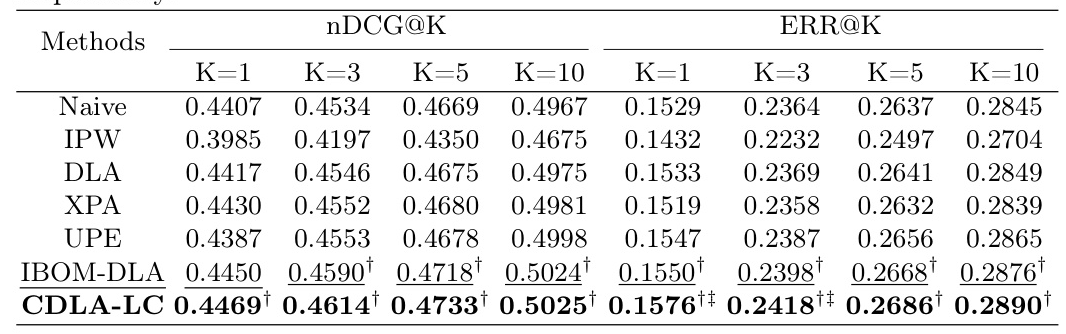
Performance is assessed using normalized Discount Cumulative Gain (nDCG) and Expected Reciprocal Rank (ERR) at various ranks (K=1, 3, 5, 10).
Results and Analysis
Performance Comparison (RQ1)
CDLA-LD outperforms all baselines across all metrics, demonstrating its effectiveness in mitigating both position and contextual biases.
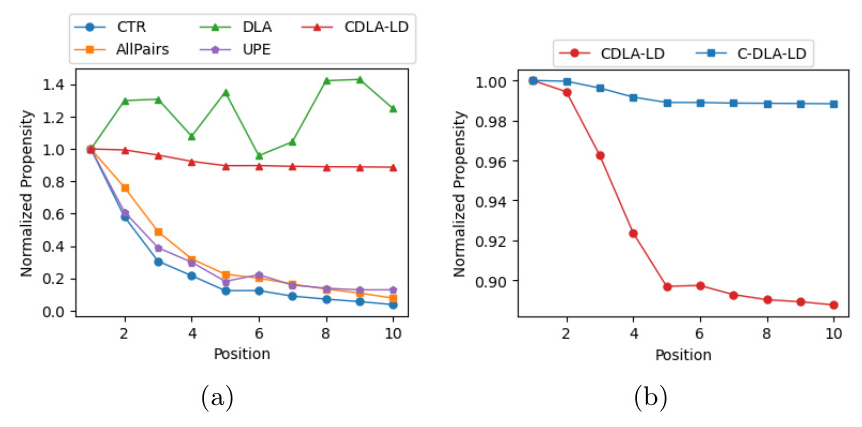
Propensity Analysis (RQ2)
CDLA-LD estimates propensity more accurately than other methods, closely aligning with real-world click-through rates (CTR).
Effectiveness of Debiasing (RQ3)
Training an unbiased listwise-input ranking model and distilling it into a pointwise-input ranking model yields better performance than other debiasing strategies.

Ablation Study (RQ4)
The listwise-input ranking model alone performs significantly worse than CDLA-LD, highlighting the importance of listwise distillation.

Overall Conclusion
The proposed CDLA-LD effectively addresses both position and contextual biases in ULTR. By jointly training an unbiased listwise-input ranking model and a propensity model, and distilling the relevance judgment capabilities into a pointwise-input ranking model, CDLA-LD achieves superior performance on real-world click data. Future work may explore incorporating interaction information from document positions and clicks to further enhance the propensity model.