

Authors:
Yuqicheng Zhu、Nico Potyka、Jiarong Pan、Bo Xiong、Yunjie He、Evgeny Kharlamov、Steffen Staab
Paper:
https://arxiv.org/abs/2408.08248
Introduction
Knowledge Graph Embeddings (KGE) are a powerful tool for mapping entities and predicates into numerical vectors, enabling non-classical reasoning capabilities by leveraging similarities and analogies between entities and relations. Typically, KGE models are evaluated through link prediction tasks, where the goal is to rank all potential answers to a query based on their plausibility scores. However, these rankings often lack a meaningful probabilistic interpretation, making it challenging to distinguish plausible from implausible answers, especially in high-stakes domains like medicine.
To address this issue, the authors propose using the theory of conformal prediction to generate answer sets with probabilistic guarantees. This approach ensures that the correct answer is included in the answer set with a specified confidence level. The paper demonstrates how conformal prediction can be applied to link prediction tasks and validates the approach through empirical evaluation on benchmark datasets using various KGE methods.
Related Work
Uncertainty quantification in KGE methods is a relatively unexplored area. Existing approaches often incorporate uncertainty by modeling entities and relations using probability distributions. However, these methods primarily focus on enhancing the performance of KGE models without systematically analyzing or rigorously evaluating the quality of uncertainty in embeddings or predictions.
Previous works have applied off-the-shelf calibration techniques, such as Platt scaling and Isotonic regression, to KGE methods. These techniques aim to convert uncalibrated plausibility scores into probabilities but lack formal probabilistic guarantees and are sensitive to the calibration set.
Conformal prediction, rooted in online learning literature, produces predictive sets with coverage guarantees. It has been successfully applied across various domains but has not yet been applied to KGE.
Preliminaries
Knowledge Graph Embedding
A knowledge graph (KG) is defined over a set of entities (E) and a set of relation names (R). The elements in a KG are called triples and are denoted as ⟨h, r, t⟩. A KGE model assigns a plausibility score to each triple, indicating the likelihood that the triple holds. The parameters of the model are learned to assign higher scores to true triples and lower scores to false ones. Different KGE methods interpret plausibility scores differently, such as distance-based models (e.g., TransE, RotatE) and semantic matching models (e.g., RESCAL, DistMult).
Conformal Prediction
Conformal prediction is a framework for producing answer sets that cover the ground truth with probabilistic guarantees. Given a training set and a new query, a conformal predictor produces an answer set that contains the correct answer with a specified confidence level. The construction of the answer set is based on a nonconformity measure, which evaluates how unusual a potential answer is compared to the training set.
KGE-based Answer Set Prediction
Problem Definition and Desiderata
The link prediction task is reformulated as an answer set prediction task. Given a set of training triples, a test query, and a user-specified error rate, the goal is to predict a set of entities that covers the true answer with high probability. The key desiderata for effective set predictors are coverage (ensuring the true answer is included), size (producing smaller sets), and adaptiveness (reflecting query difficulty).
Basic Set Predictors
- Naive Predictor: Constructs the answer set by including entities from highest to lowest probability until their sum exceeds the threshold 1 – ϵ. However, plausibility scores are not calibrated.
- Platt Predictor: Uses multiclass Platt scaling to calibrate plausibility scores and then constructs sets based on these calibrated probabilities.
- TopK Predictor: Constructs the set with the top-K entities from the ranking, ensuring the top-K entities cover the correct answers for 1 – ϵ of the validation queries.
Conformal Prediction for KGE-based Answer Set Prediction
Nonconformity Measures
The effectiveness of conformal predictors depends on the nonconformity measure used. Several nonconformity measures for KGE models are proposed:
- NegScore: Uses the negative value of the plausibility score, indicating higher nonconformity for lower plausibility scores.
- Minmax: Normalizes scores using min-max scaling to reflect the relative position of the triple within the score distribution.
- Softmax: Converts plausibility scores into an uncalibrated probability distribution using the softmax function, highlighting the most likely triples.
Answer Set Construction
To construct answer sets efficiently, split/inductive conformal prediction is adopted. The training set is divided into a proper training set and a calibration set. The KGE model is trained on the proper training set, and nonconformity scores are calculated on the calibration set. This strategy increases efficiency while preserving probabilistic guarantees.
Experiments
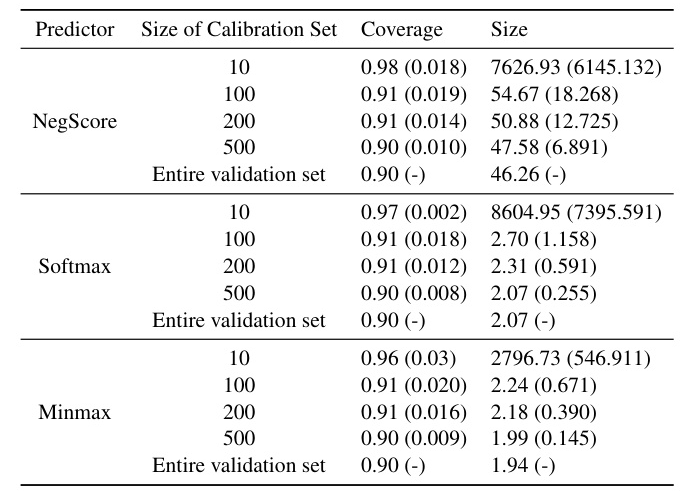
Experiment 1: Coverage and Set Size on WN18 and FB15k
This experiment evaluates the coverage and size of answer sets generated by different predictors. Conformal predictors consistently meet the coverage desideratum and produce smaller answer sets compared to baseline predictors. The results demonstrate that conformal predictors outperform baseline predictors in terms of producing smaller answer sets while maintaining coverage guarantees.
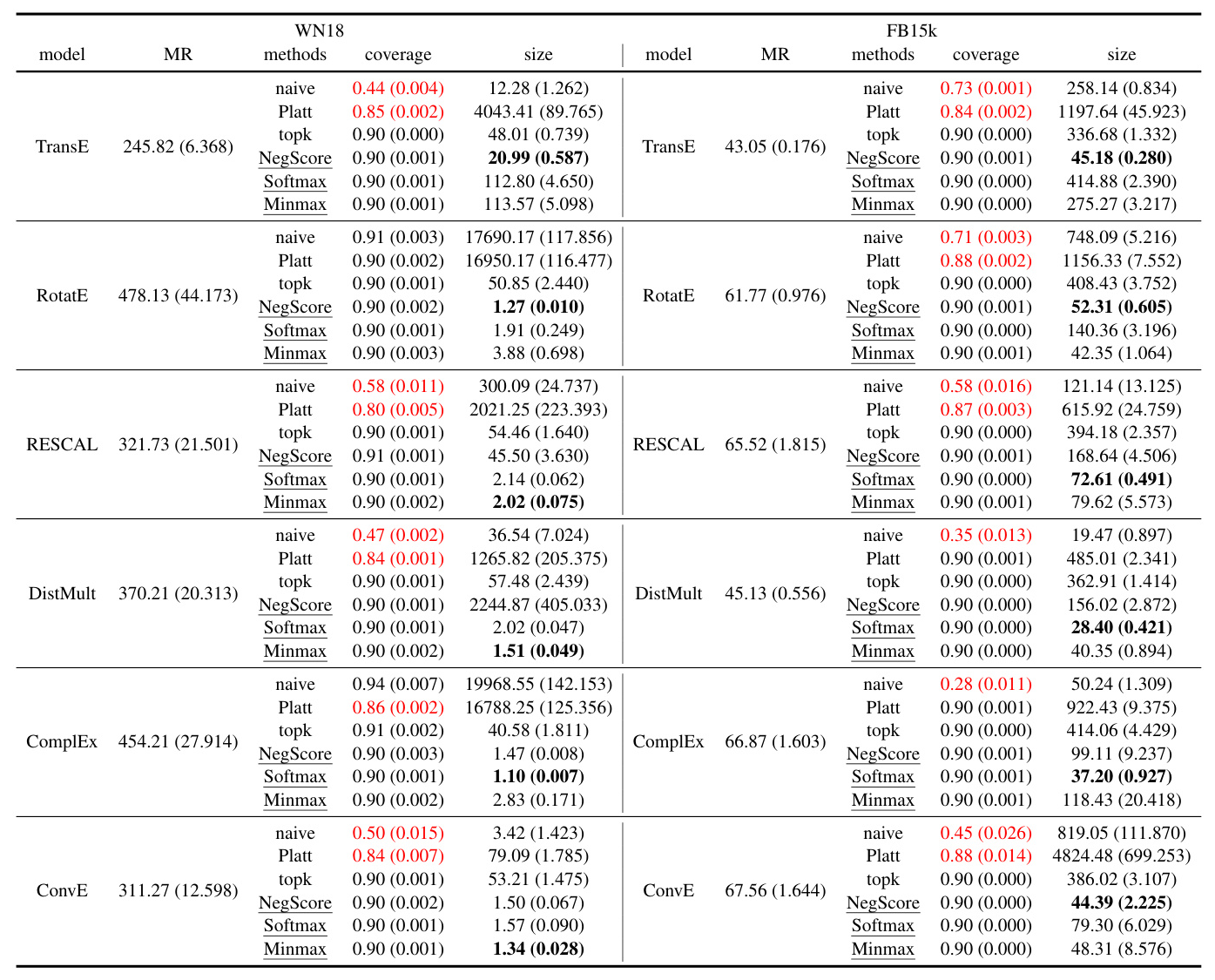
Experiment 2: Adaptiveness of Answer Sets
This experiment evaluates whether the size of answer sets adapts to query difficulty. The rank of the true answer is used to categorize queries by difficulty levels. The results show that the size of answer sets generated by conformal predictors aligns with query difficulty, fulfilling the adaptiveness desideratum.
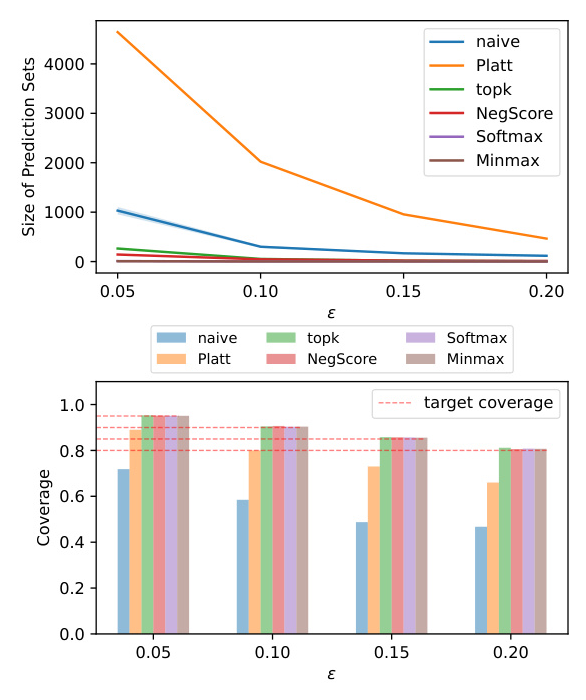
Experiment 3: Impact of Calibration Set Size on Answer Set Quality
This experiment investigates the impact of the calibration set size on the quality of answer sets. The results show that even a small calibration set can produce high-quality answer sets, closely approximating the results obtained using the entire validation set.
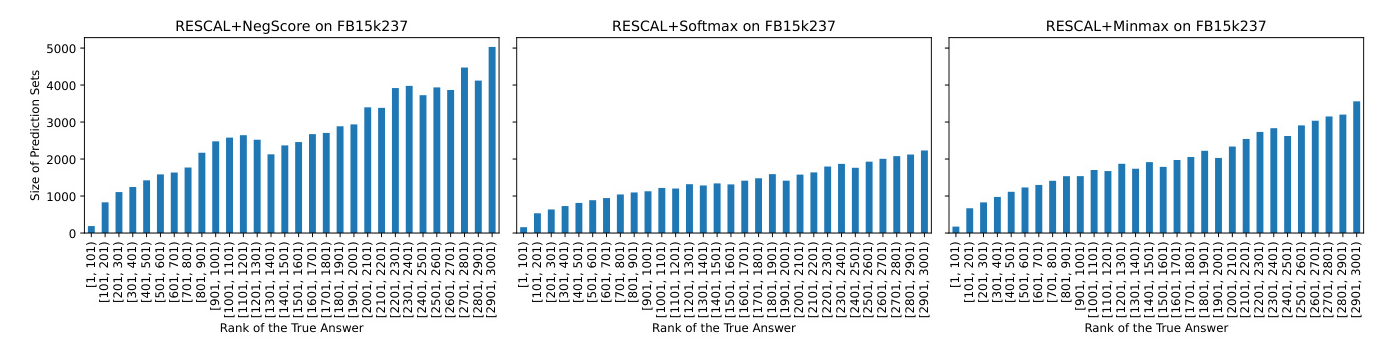
Experiment 4: Impact of Error Rate on Answer Set Quality
This experiment examines the effect of the user-specified error rate on the quality of answer sets. The results show that the size of answer sets decreases as the error rate increases, and conformal predictors consistently meet the probabilistic guarantee across different error rates.
Discussion
The proposed method predicts answer sets with a guaranteed coverage of the true answer at a specified confidence level while maintaining a small average size. This approach is particularly well-suited for decision-making in high-stakes domains, such as medical diagnosis and fraud detection. The method is easy to implement and compatible with various KGE models and embedding methods capable of answering complex queries.
Limitations
A limitation of the method is the requirement to divide the training set into two parts for training the model and calculating nonconformity scores. This division reduces the number of triples available for model training. However, this issue is mitigated by using the validation set as the calibration set. Another limitation is the reliance on the i.i.d. assumption, which may not hold under distribution shifts. Future work aims to extend conformal predictors to handle covariant shift scenarios.
In conclusion, the paper presents a novel approach to generating answer sets for KGE-based link prediction tasks with formal probabilistic guarantees, demonstrating its effectiveness through extensive experiments.