

Authors:
Vibhor Agarwal、Yulong Pei、Salwa Alamir、Xiaomo Liu
Paper:
https://arxiv.org/abs/2408.08333
Introduction
Large Language Models (LLMs) have demonstrated significant capabilities in natural language generation and program generation. However, these models are prone to generating hallucinations—text that sounds plausible but is incorrect. This phenomenon is not limited to natural language but extends to code generation as well. The generated code can contain syntactical or logical errors, security vulnerabilities, memory leaks, and other issues. Given the increasing adoption of LLMs in code generation, it is crucial to investigate these hallucinations. This paper introduces the concept of code hallucinations, provides a comprehensive taxonomy of hallucination types, and proposes the first benchmark dataset, CodeMirage, for studying hallucinations in code generated by LLMs.
Related Work
Language Models for Code Generation
The success of language models in natural language processing has spurred interest in their application to code generation. Pre-trained transformer-based models like CodeBERT and OpenAI’s GPT series have shown strong performance in generating code. These models are trained on large datasets of programming code and can generate code snippets in various languages. However, they are not immune to generating hallucinations, which can manifest as syntactical errors, logical errors, and other issues.
Hallucinations in LLMs
Hallucinations in LLMs have been a significant challenge in natural language generation. These hallucinations can be intrinsic, where the generated output contradicts the source content, or extrinsic, where the output cannot be verified from the source content. Similar issues arise in code generation, where the generated code can have various defects. Previous works have studied buggy-code completion, functional correctness, and non-determinism in LLM-generated code, but none have specifically focused on hallucinations in code.
Hallucinations in Code Generation
Problem Definition
Code hallucinations are defined as generated code that contains one or more defects such as dead or unreachable code, syntactic or logical errors, robustness issues, security vulnerabilities, or memory leaks. These defects can make the code incorrect or unreliable.
Taxonomy
The taxonomy of code hallucinations includes five categories:
- Dead or Unreachable Code: Code that is redundant or cannot be executed.
- Syntactic Incorrectness: Code with syntax errors that fail to compile.
- Logical Error: Code that does not solve the given problem correctly.
- Robustness Issue: Code that fails on edge cases or raises exceptions without proper handling.
- Security Vulnerabilities: Code with security flaws or memory leaks.
CodeMirage Dataset
Dataset Generation
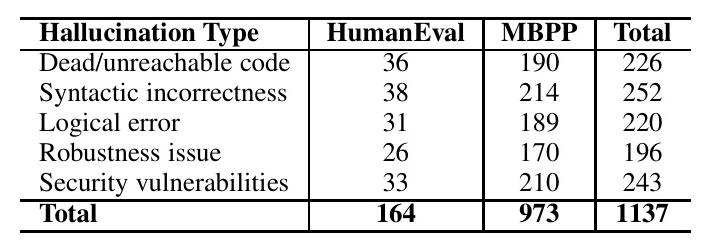
The CodeMirage dataset is generated using two base datasets: HumanEval and MBPP. HumanEval contains 164 Python programming problems, while MBPP consists of 973 crowd-sourced Python problems. GPT-3.5 is used to generate hallucinated code snippets for these problems. Specific prompts are designed for each hallucination type, and the generated code is labeled accordingly.
Human Annotations
To validate the dataset, human annotators reviewed a sample of the generated code snippets. The annotations confirmed the reliability of the automatically assigned labels, with a high accuracy of 0.81 and a Cohen’s kappa score of 0.76, indicating strong agreement among annotators.
Dataset Statistics
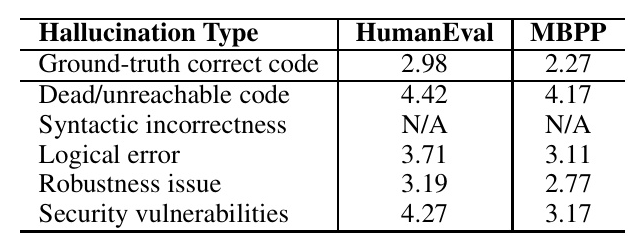
The CodeMirage dataset contains 1,137 hallucinated Python code snippets, with a balanced distribution across the five hallucination types. The dataset also includes ground-truth code snippets and test cases for evaluation. The cyclomatic complexity of the generated code snippets is higher than that of the ground-truth code, indicating the presence of more complex code defects.
Code Hallucination Detection
Methodology
The task of detecting code hallucinations is modeled as a multi-class classification problem. Various LLMs, including CodeLLaMA, GPT-3.5, and GPT-4, are prompted to detect hallucinations in code snippets. The models are evaluated using one-shot prompts that include definitions and examples of each hallucination type.
Experimental Setup and Evaluation Metrics
The models are evaluated using accuracy, macro-precision, macro-recall, and macro-F1 scores. The experiments involve using one-shot prompts with problem descriptions and code snippets as input to the LLMs.
Results
The results show that GPT-4 performs the best on the HumanEval dataset, achieving a macro-F1 score of 0.5512, while it performs comparably on the MBPP dataset with a macro-F1 score of 0.5195. CodeBERT, fine-tuned on the CodeMirage dataset, also shows strong performance, particularly on the MBPP dataset. CodeLLaMA, however, does not perform well in detecting code hallucinations.

Conclusions and Future Work
This study introduces the concept of code hallucinations and provides a comprehensive taxonomy and benchmark dataset, CodeMirage, for studying hallucinations in code generated by LLMs. The experiments demonstrate that while LLMs like GPT-4 show promise in detecting code hallucinations, there is still significant room for improvement. Future work can explore fine-tuning LLMs with specific hallucination detection instructions, using software engineering methods for defect detection, and developing strategies to mitigate code hallucinations. Solving these challenges is crucial for the safe adoption of LLMs in code generation.
Appendices
Prompts for Code Hallucination Generation
Detailed prompts for generating each type of code hallucination are provided, including examples and specific instructions for GPT-3.5.
Prompt for Code Hallucination Detection
The one-shot prompt used for detecting code hallucinations includes definitions and examples of each hallucination type, along with the programming question and code snippet.
This blog post provides a detailed overview of the paper “CodeMirage: Hallucinations in Code Generated by Large Language Models,” highlighting the key contributions, methodology, and findings. The study opens new avenues for research in detecting and mitigating code hallucinations, which is essential for the reliable use of LLMs in code generation.