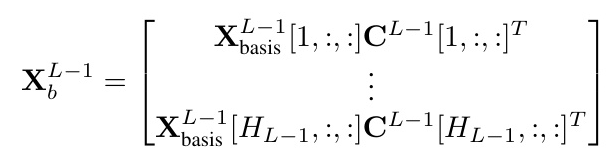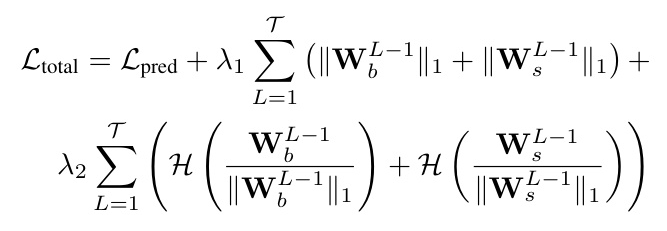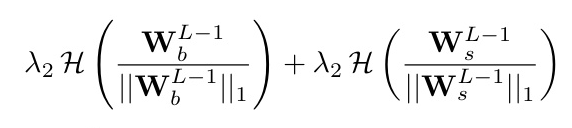Authors:
Yunxiao Shi、Wujiang Wu、Mingyu Jin、Haimin Zhang、Qiang Wu、Yongfeng Zhang、Min Xu
Paper:
https://arxiv.org/abs/2408.08713
Introduction
In the dynamic field of digital advertising and recommendation systems, Click-Through Rate (CTR) prediction is crucial for optimizing user engagement and revenue. Traditional methods for CTR prediction often struggle with modeling high-order feature interactions due to computational costs and the need for predefined interaction orders. To address these challenges, the paper introduces the Kolmogorov-Arnold Represented Sparse Efficient Interaction Network (KarSein), which aims to enhance predictive accuracy and computational efficiency.
Preliminaries
Problem Formulation for CTR
CTR prediction involves estimating the probability that a user will click on an item. Given a user-item pair ((u, i)), the feature vector (x_{u,i}) captures relevant attributes. The goal is to estimate (P(y = 1 | x_{u,i})), where (y) indicates whether the user clicked on the item. The predictive model (f(x_{u,i}; \Theta)) is optimized to minimize the prediction error using log loss.
Feature Interactions Modeling
Feature interactions in recommendation systems can be categorized into implicit and explicit interactions. Implicit interactions are captured automatically by models, while explicit interactions involve predefined multiplications at the vector level among feature embeddings.
Kolmogorov-Arnold Network (KAN)
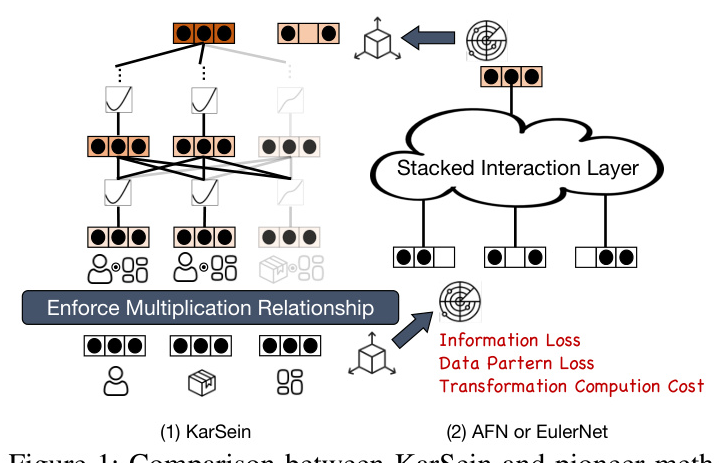
The Kolmogorov-Arnold Theorem states that a multivariate function can be expressed using univariate functions and summation. KAN employs learnable B-Spline curves for activation, extending the theorem to neural networks. However, applying vanilla KAN to CTR prediction faces challenges such as sensitivity to regularization settings, lack of support for 2D embedding vectors, and high computational complexity.
KARSEIN
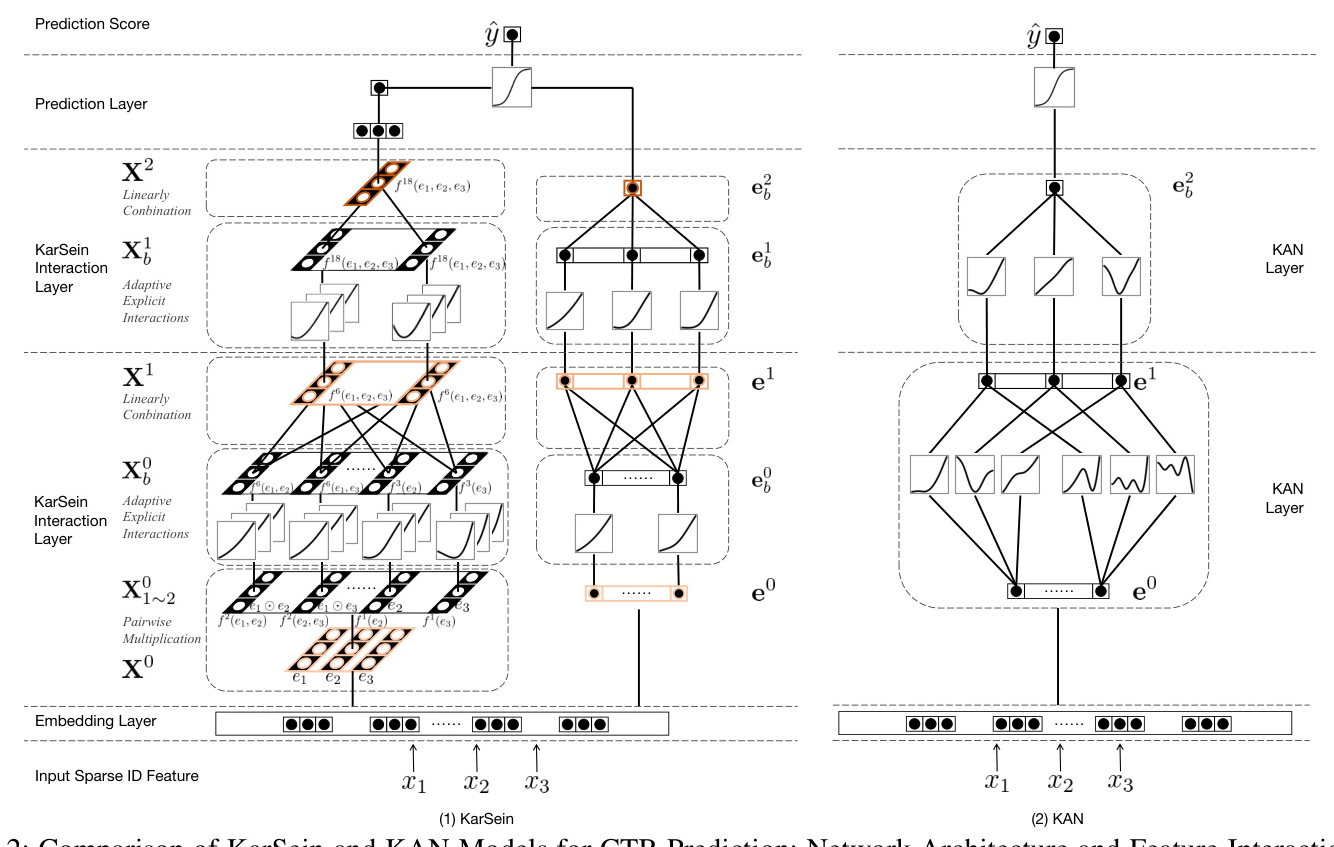
KarSein Interaction Layer
KarSein consists of multiple stacked interaction layers, each performing three steps: optional pairwise multiplication, learnable activation transformation, and linear combination. This architecture allows KarSein to model high-order feature interactions efficiently.
Pairwise Multiplication
Pairwise multiplication is conducted between input features to guide the model in learning multiplicative relationships. This step is typically applied only in the first two interaction layers.
Activation Transformation
Activation transformation uses B-Spline curves to activate embedding vectors, enhancing the model’s ability to capture high-order interactions.
Linearly Combination
The activated embedding vectors are linearly combined, with an additional residual connection to improve expressiveness.
Integrating Implicit Interactions
KarSein integrates implicit interactions by employing a parallel network architecture that models vector-wise and bit-wise interactions separately. The final outputs from both architectures are combined for binary classification in CTR prediction.
Training with Sparsity
KarSein incorporates L1 and entropy regularization in the linear combination step to eliminate redundant hidden neurons, enhancing efficiency and maintaining global interpretability.
Analysis
KarSein’s computational complexity is compared with other state-of-the-art CTR methods. The proposed model achieves computational efficiency comparable to DNN while retaining KAN’s advantage of smaller hidden neurons and shallower layers. KarSein-explicit performs feature interactions directly within the original space, benefiting from KAN’s structural sparsity pruning capability.
Experiments
Experiment Setups
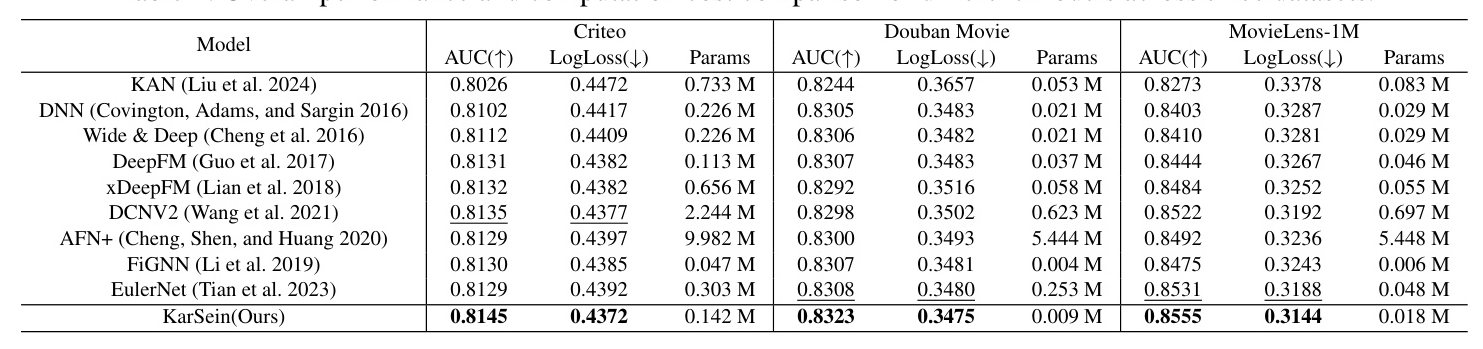
Experiments were conducted on three datasets: MovieLens 1M, Douban Movie, and Criteo. The performance of KarSein was compared with various baseline methods, including DNN, KAN, Wide & Deep, DCNV2, DeepFM, xDeepFM, AFN+, EulerNet, and FiGNN.
Overall Performance (RQ1)
KarSein consistently outperforms all baseline methods across the three datasets, demonstrating the efficacy of its learnable activation functions in capturing high-order feature interactions. The model also exhibits lower computational costs compared to several state-of-the-art methods.
Ablation Study (RQ2)
The contributions of explicit and implicit feature interactions in KarSein were evaluated independently. The results show that while combining both interaction types yields superior AUC performance, explicit interactions offer advantages in efficiency and parameter size.
Robustness Study (RQ3)
The impact of pairwise multiplication across different layers on KarSein-explicit’s performance was investigated. Applying pairwise multiplication in the first two layers achieves the highest AUC scores, confirming the difficulty of KAN in learning multiplicative relationships on its own.
Explanation Study (RQ4)
Learnable activation functions in KarSein were visualized, showing that they effectively transform low-order input features into high-order interactions. Some activation functions displayed oscillatory patterns, highlighting the flexibility of B-Spline activation functions.
Pruning Redundant Features (RQ5)
The optimized KarSein model was assessed for sparsity and feature redundancy reduction. Redundant features were identified and masked, demonstrating the model’s ability to remove unnecessary features without significantly compromising performance.
Related Works
Adaptive Order Feature Interaction Learning
Recent advancements in CTR prediction, such as AFN and EulerNet, aim to adaptively learn high-order feature interactions. However, these methods face challenges related to numerical stability and computational overhead. KarSein addresses these issues by directly activating features within the original space.
Feature Importance Learning
Methods like AFM, AutoInt, FiGNN, and FiBiNET provide contextual explanations for the prediction process. However, their explainability is inherently local. KarSein’s global interpretability allows for the pruning of unnecessary network structures, resulting in a sparser architecture.
Conclusion and Future Work
KarSein enhances predictive accuracy and reduces computational costs through a novel architecture that uses learnable activation functions for modeling high-order features. The model maintains global interpretability and a sparse network structure, positioning it as a highly efficient method for CTR prediction.