Authors:
Karthik Shivashankar、Antonio Martini
Paper:
https://arxiv.org/abs/2408.09134
Better Python Programming for All: Enhancing Maintainability with Large Language Models
Introduction
The advent of Large Language Models (LLMs) has revolutionized automated programming, offering unprecedented assistance in generating syntactically correct and functionally robust code. However, concerns about the maintainability of the code produced by these models persist. Maintainability is crucial for the long-term success of software projects, affecting factors such as technical debt and the cost of future modifications. While existing research has extensively explored the functional accuracy and testing efficacy of LLM-generated code, maintainability has often been overlooked. This study aims to address this gap by fine-tuning LLMs to prioritize code maintainability, specifically within the context of Python programming.
Research Questions
Central to our investigation is the inquiry into the extent to which fine-tuning LLMs can enhance their capacity to assess and improve the maintainability of Python code. Our primary research question (RQ1) is: “How does fine-tuning augment LLMs’ capability to generate Python code with higher maintainability, and can the improvements be measured?”
Motivation
The motivation for exploring RQ1 stems from a recognized gap in the current literature concerning the maintainability of LLM-generated code. High-quality, maintainable code significantly facilitates updates, debugging, and scalability, thus minimizing long-term maintenance costs and fostering ongoing innovation. As Code LLMs continue to gain traction for their efficiency in streamlining coding tasks, it becomes imperative to ensure that their outputs are operationally effective and maintainable in the long run.
Contributions
Our contributions are twofold:
1. Development of a Custom Dataset: We’ve curated a dataset focusing on the maintainability of Python code, emphasizing readability, complexity, and modifiability. This dataset is engineered for developing and fine-tuning LLMs, ensuring that generated code aligns with maintainability best practices.
2. Empirical Evaluation of Fine-tuned Model: We introduce an experimental method leveraging our extended custom dataset to evaluate fine-tuned LLMs on maintainability. This method extends conventional functional testing by scrutinizing the maintainability of the code generated, thereby offering a comprehensive assessment of the model’s output.
Related Work
Maintainability
Maintainability is a crucial quality attribute determining the ease of understanding, modifying, and extending software. Adherence to maintainable coding standards promotes code readability and consistency, which are fundamental for collaborative development efforts and the long-term viability of software projects. However, there is a gap in research regarding the compliance of Code LLMs with such standards, calling into question their practicality in actual software development scenarios.
Parameter Efficient Fine Tuning (PEFT)
Parameter-efficient fine-tuning (PEFT) has become increasingly relevant in machine learning, particularly for adapting large pre-trained models to specific tasks with minimal computational overhead. PEFT methods achieve strong task performance while updating a significantly smaller number of parameters compared to full model fine-tuning. This cost-effective approach addresses the challenge of making informed design choices on the PEFT configurations, such as architecture and the number of tunable parameters.
Existing Research
Previous studies have explored various aspects of LLMs for code generation:
– Zhuo introduced a framework that assesses the quality of LLM-generated code, ensuring it aligns with human standards.
– Xiong, Guo, and Chen explored how LLMs can assist in program synthesis by generating test cases.
– Shirafuji et al. investigated the robustness of LLMs in programming problem-solving, revealing the sensitivity of these models to prompt engineering.
– Le et al. proposed “CodeRL,” integrating a pre-trained model with deep reinforcement learning for program synthesis.
Despite these advances, there appears to be a gap in research explicitly targeting the maintainability of code generated by LLMs. Our research fills this gap, offering unique insights and methodologies for enhancing code maintainability, particularly in Python, using LLMs.
Research Methodology
This research employs a systematic methodology to investigate LLMs’ generation and evaluation of maintainable Python code. The approach is structured into several vital steps, each addressing the main research question (RQ1). The methodology combines dataset preparation, model fine-tuning, and comprehensive evaluation techniques to assess the capability of LLMs in producing code that functions correctly and adheres to high maintainability standards.
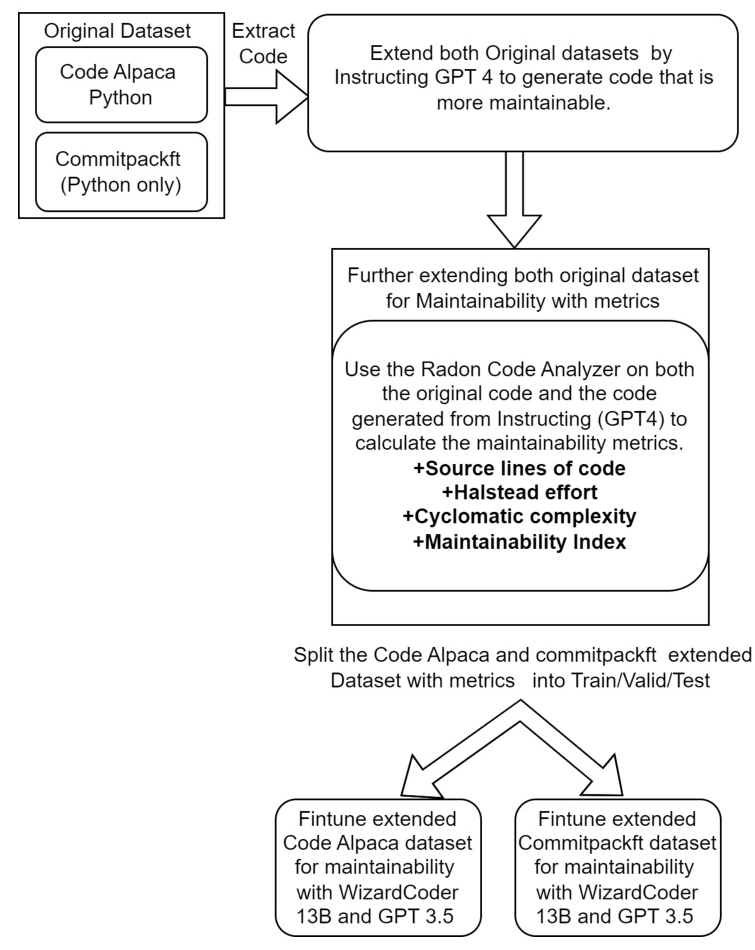
Dataset Preparation
For fine-tuning Code LLMs, the initial step involves using various original code samples as the primary input. These code samples are from the CommitPackFT dataset (Python subset) and CodeAlpaca-18k (Python) dataset. This immerses the models in various authentic coding situations, with the imperfections and inconsistencies they would encounter in the practical coding environment.
Model Fine-Tuning
We employ the GPT-4 model, distinguished for its prowess in code generation among various tasks. We instruct or prompt GPT-4 with detailed context, including original code alongside maintainability metrics, aiming to generate refactored code that preserves the original functionality while optimizing maintainability.
Evaluation Techniques
The evaluation process involves using CodeBERTScore to compare the similarity and functional correctness of the code generated by the fine-tuned models against the original code samples. Additionally, the utility of the fine-tuned models is assessed through invaluable feedback from expert Python programmers, who play a pivotal role in evaluating the generated code’s quality and adherence to best practices like code readability, modularity, and reusability.
Experimental Design
Selecting Dataset for Maintainability
The datasets used for fine-tuning include CommitPackFT (Python subset) and CodeAlpaca (Python). These datasets offer a diverse set of coding examples and instructional data essential for developing models that can follow instructions in code generation tasks.
Instructing GPT-4 to Generate Maintainable Code
To enhance the maintainability of the code samples from the chosen dataset, we employ the GPT-4 model. We instruct GPT-4 with detailed context, including original code alongside maintainability metrics, aiming to generate refactored code that preserves the original functionality while optimizing maintainability.
Evaluating Functional Similarity
We use CodeBERTScore to evaluate the functional similarity between the original and generated code. This metric leverages the contextual embeddings from a model like CodeBERT, which is trained on both programming languages and natural language, to compute soft similarities between tokens in the generated and reference code.
Enhancing the Dataset with Maintainability Metrics
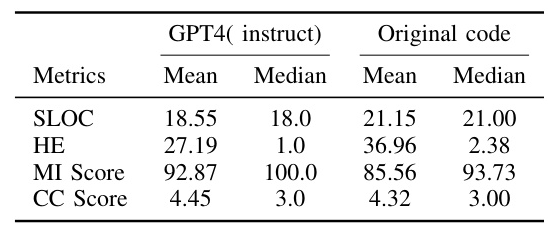
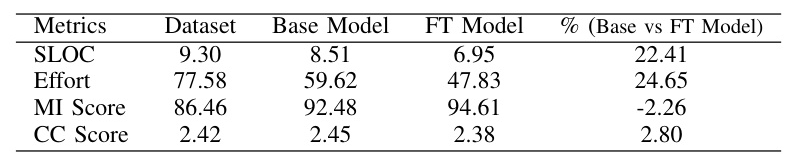
For each piece of code in the original dataset, we compute maintainability metrics—namely, Maintainability Index (MI), Cyclomatic Complexity (CC), Halstead Effort (HE), and Source Lines of Code (SLOC). These metrics are calculated for both the original code samples and those generated by instructing GPT-4, with the resultant maintainability metrics subsequently incorporated into the new fields within the dataset.
Fine-Tuning for Maintainability
We fine-tune two models: WizardCoder 13B and OpenAI’s GPT-3.5. The fine-tuning process for WizardCoder 13B incorporates the Supervised Fine-tuning Trainer (SFT) from Hugging Face, coupled with the PEFT library. In contrast, GPT-3.5 is fine-tuned using OpenAI’s API.
Results and Analysis
Fine-Tuning LLM to Generate Python Code with Higher Maintainability
The primary aim of this research question is to critically evaluate the impact of fine-tuning LLMs on their capability to produce maintainable Python code. Following the fine-tuning phase, the model enters a crucial testing stage to gauge its ability to apply the coding pattern and characteristics it has learned to new and unseen examples of Python code.
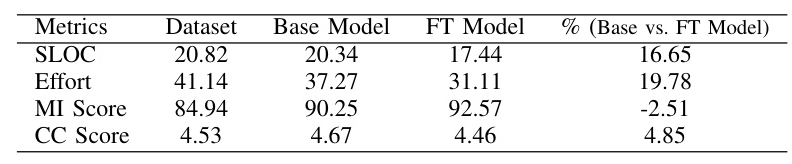
Comparison of Original and Refactored Code
A simple comparative example of original and refactored implementations of the bubble sort algorithm demonstrates the effectiveness of the fine-tuned model. The refactored code shows improvements in maintainability metrics such as SLOC, CC Score, Effort, and MI Score.
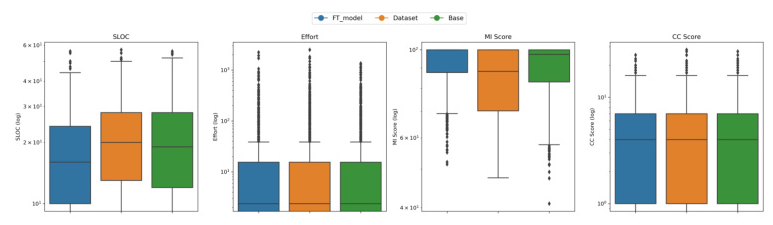
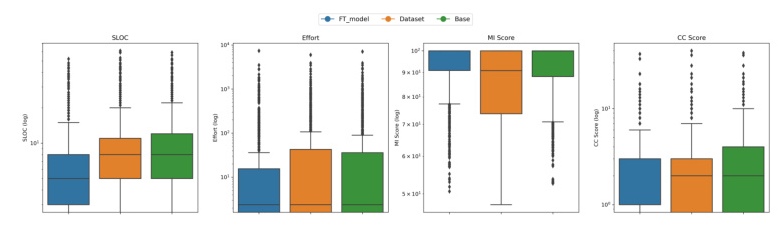
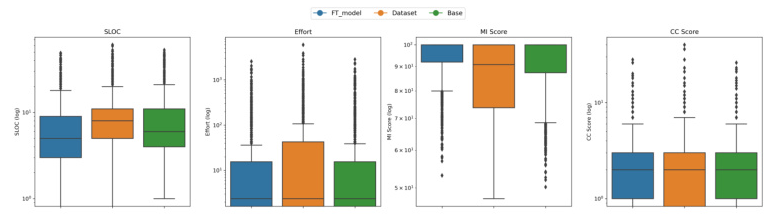
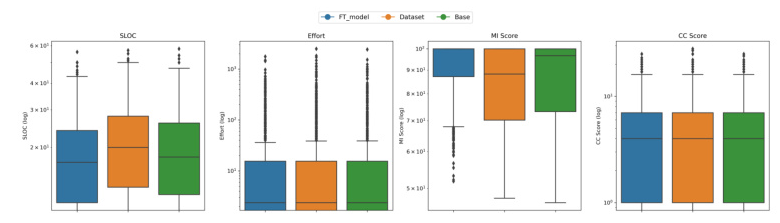
Analysis of Distribution Box Plot
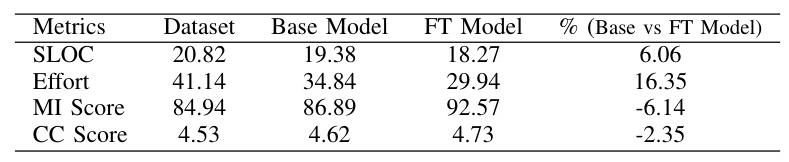
The box plot provides a comprehensive view of the performance across the Original Dataset, Base Model, and Fine-Tuned (FT) Model. It visualizes the distribution of maintainability metrics, including a comparison of median values and the extent of variability and outliers.
Evaluating Functional Similarity on the Test Split
The evaluation of fine-tuned models on the test split using CodeBERTScores shows high functional correctness and similarity between the original reference code from the dataset and the generated code from the FT models on both CommitPack and CodeAlpaca datasets.
Assessing Usefulness and Utility
Our evaluation method for assessing a fine-tuned AI model as a programming assistant involved a structured session where participants with varying Python expertise interacted with the FT model to complete coding tasks reflective of real-world scenarios. Feedback was gathered through a questionnaire focusing on the model’s usefulness and effectiveness as an AI companion.
Overall Conclusion
This study explores the effectiveness of fine-tuning Large Language Models (LLMs) for generating maintainable Python code. Utilizing our custom extended datasets and leveraging models such as WizardCoder 13B and GPT-3.5, we have achieved notable improvements in code maintainability metrics, such as Source Lines of Code, Maintainability Index, Halstead Effort, and Cyclomatic Complexity. These enhancements highlight LLMs’ potential as powerful tools in automating code refactoring processes, with the promise of advancing software development practices. By examining the strengths and weaknesses of LLMs in producing maintainable Python code, this research contributes significantly to the fields of automated code generation and software maintainability.