

Authors:
Usman Syed、Ethan Light、Xingang Guo、Huan Zhang、Lianhui Qin、Yanfeng Ouyang、Bin Hu
Paper:
https://arxiv.org/abs/2408.08302
Introduction
The rapid advancements in artificial intelligence (AI) have significantly transformed various domains, including transportation system engineering. Among these advancements, large language models (LLMs) such as GPT-4, Claude 3.5 Sonnet, and Llama 3.1 have shown remarkable capabilities in understanding and generating human-like text. This paper explores the potential of these LLMs in solving undergraduate-level transportation engineering problems, focusing on their accuracy, consistency, and reasoning behaviors.
Transportation systems engineering is a critical interdisciplinary subfield of civil engineering that involves the planning, design, operations, and management of transportation systems. The complexity and interdisciplinary nature of this field make it an ideal benchmark for assessing the reasoning capabilities of LLMs. This study introduces TransportBench, a benchmark dataset designed to evaluate the performance of various LLMs in solving transportation engineering problems.
The TransportBench Dataset
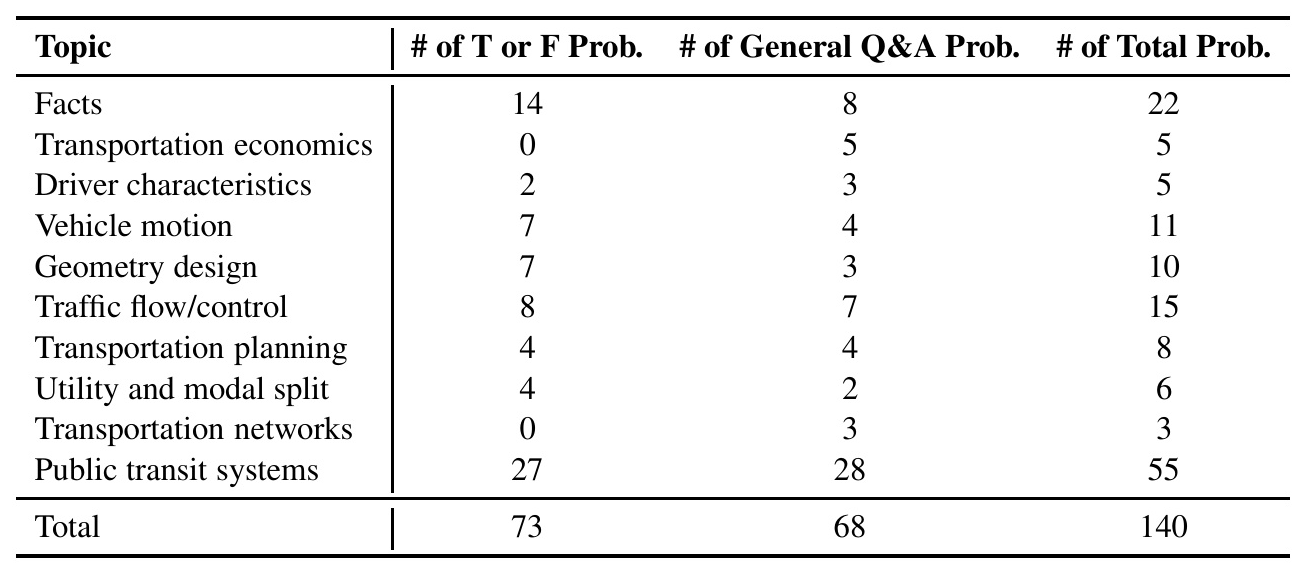
TransportBench is a collection of 140 undergraduate problems covering a broad spectrum of topics in transportation engineering, including transportation economics, driver characteristics, vehicle motion, road geometry design, traffic flow/control, transportation planning, utility/modal split, transportation networks, and public transit systems. The dataset consists of both true or false problems and general Q&A problems.
The problems in TransportBench were selected by an expert based on two courses at the University of Illinois: CEE 310 – Transportation Engineering and CEE 418 – Public Transportation Systems. The dataset captures key areas of transportation systems engineering and provides a rigorous testing ground for evaluating the problem-solving abilities of LLMs.
Evaluating Accuracy of Leading LLMs on TransportBench
The accuracy of leading LLMs such as GPT-4, GPT-4o, Claude 3 Opus, Claude 3.5 Sonnet, Gemini 1.5 Pro, Llama 3, and Llama 3.1 was evaluated using a zero-shot prompting strategy. This approach involves directly inputting the question into the LLMs and analyzing their responses through human expert annotation.
Example Problems
- General Q&A Problem:
- Input: Suppose you have one widget plant at the center of a sufficiently large country of size ( S \, \text{mi}^2 ), where the population is uniformly distributed with a density of ( \delta \, \text{people/mi}^2 ). The production cost is ( \$C ) per unit, and the selling price is ( \$P ) per unit. Determine the shape, size, and total demand of your market.
- LLM Responses: GPT-4, Claude 3.5 Sonnet, and Gemini 1.5 Pro provided correct and detailed solutions.

- True or False Problem:
- Input: In horizontal curve design, for a given design speed, the larger the road radius, the larger the rate of super-elevation. True or False?
- LLM Responses: All LLMs correctly identified the relationship between road radius, super-elevation, and design speed, concluding that the statement is false.
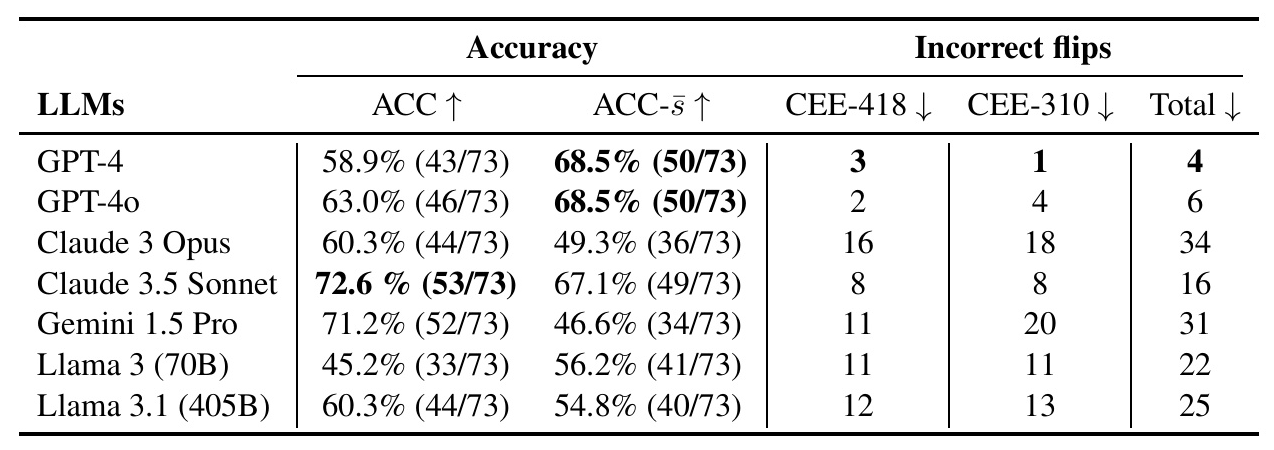
Accuracy Results
The accuracy (ACC) of the LLMs on TransportBench is summarized in the following table:
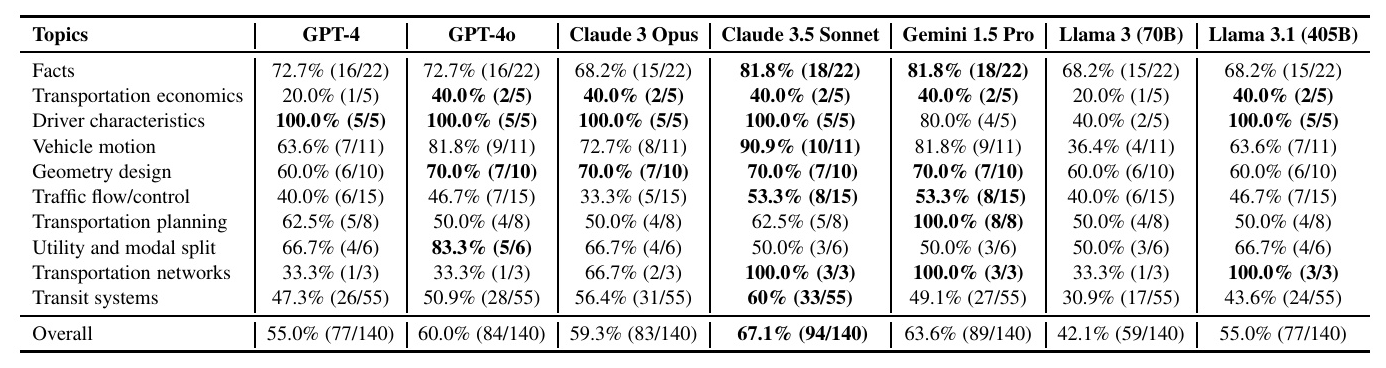
Key observations include:
– Claude 3.5 Sonnet achieved the highest accuracy, demonstrating superior capabilities in handling complex transportation-related queries.
– Gemini 1.5 Pro, GPT-4o, and Claude 3 Opus also showed competitive performance.
– The open-source model Llama 3.1 reached the accuracy level of GPT-4, providing valuable insights for further research and development.
Performance on Different Problem Types
The performance of LLMs was also analyzed based on problem difficulty levels (CEE 310 vs. CEE 418) and problem types (True or False vs. General Q&A).
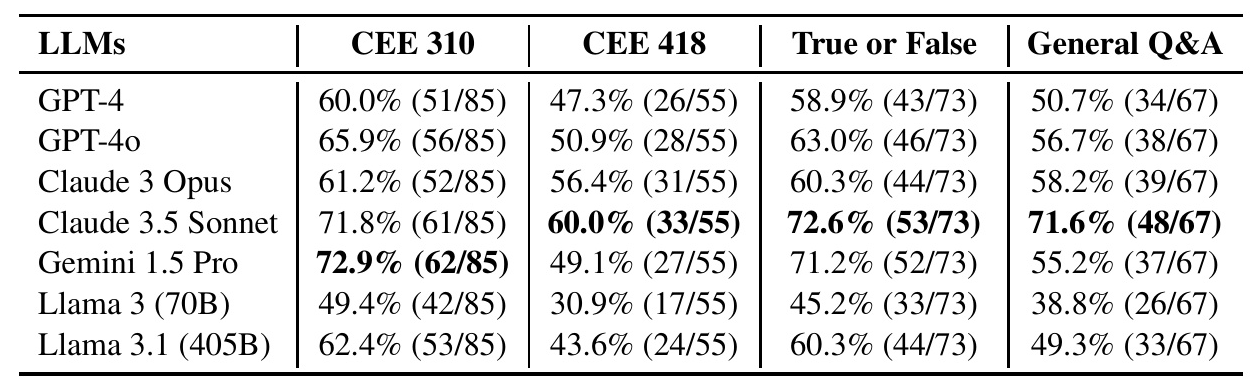
- LLMs generally performed better on CEE 310 problems compared to CEE 418 problems.
- True or False problems were easier for LLMs compared to general Q&A problems.
Evaluating Consistency of LLMs on True or False Problems
Consistency is another important aspect of LLM performance. This study evaluated the consistency of LLMs in two settings: zero-shot consistency and consistency under self-checking prompts.
Zero-Shot Consistency
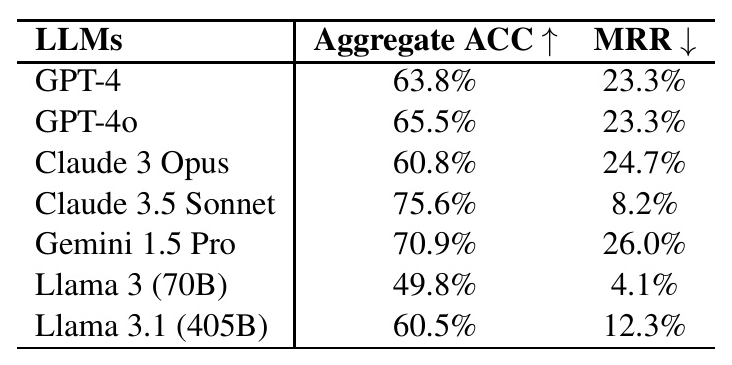
Zero-shot consistency was measured by testing multiple trials of each problem and examining whether LLMs generated the same answer. The results are summarized in the following table:

Key observations include:
– Llama 3 achieved the lowest mixed response rate (MRR) but also had the lowest aggregate accuracy.
– Claude 3.5 Sonnet achieved the highest aggregate accuracy while maintaining a low MRR.
– Most LLMs, including GPT-4, GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro, showed inconsistency in the zero-shot setting.
Consistency Under Self-Checking Prompts
Self-checking accuracy (ACC-¯s) was measured by prompting LLMs to double-check their original answers. The results are summarized in the following table:
Key observations include:
– GPT-4 and GPT-4o showed improved accuracy with self-checking prompts.
– Claude 3.5 Sonnet was more consistent than Claude 3 Opus, Gemini 1.5 Pro, Llama 3, and Llama 3.1 but less consistent than GPT-4 and GPT-4o.
Reasoning Behaviors of LLMs on TransportBench
LLMs have shown promise in reasoning for transportation engineering problems. However, they can also make subtle reasoning errors. This section examines the reasoning behaviors of LLMs through various examples.
Claude 3.5 Sonnet vs. Claude 3 Opus: Reasoning Before Conclusion Matters
The order of reasoning and conclusion generation can impact the accuracy of LLM responses. For example, when prompted to provide detailed reasoning before giving the conclusion, Claude 3 Opus was able to answer correctly.
Correct Final Answers May Come from Flawed Reasoning Approaches
LLMs can sometimes generate correct final conclusions through flawed reasoning. For example, Claude 3.5 Sonnet provided the correct fleet size for a bus line problem but used a simplistic reasoning path.

Simple Domain-Specific Prompts Can Improve Reasoning
Simple domain-specific prompts can help LLMs improve their reasoning. For example, prompting Claude 3.5 Sonnet to think about rolling resistance at different speed values led to a correct answer.

Conclusion and Future Work
This study introduces TransportBench, a benchmark dataset for evaluating the capabilities of LLMs in solving undergraduate-level transportation engineering problems. The findings highlight the potential of LLMs to revolutionize problem-solving in transportation engineering. However, there are limitations, particularly in reasoning and explanatory capabilities.
Future research should focus on:
1. Enhanced pre-training, fine-tuning, and evaluations with expanded datasets.
2. Systematic study of domain-specific prompting and in-context learning.
3. Developing reliable LLM agents with strong tool-use abilities.
4. Improving LLM reasoning through advanced search algorithms.
5. Exploring interdisciplinary applications of LLMs in related domains.
By advancing research in these directions, AI can help transform the future of transportation engineering, leading to smarter, safer, and more sustainable transportation systems.