

Authors:
Delma Nieves-Rivera、Christopher Archibald
Paper:
https://arxiv.org/abs/2408.10512
Introduction
In many real-world continuous action domains, human agents must decide which actions to attempt and then execute those actions to the best of their ability. However, humans cannot execute actions without error. Human performance in these domains can potentially be improved by the use of AI to aid in decision-making. One requirement for an AI to correctly reason about what actions a human agent should attempt is a correct model of that human’s execution error, or skill. Recent work has demonstrated successful techniques for estimating this execution error with various types of agents across different domains. However, this previous work made several assumptions that limit the application of these ideas to real-world settings.
To overcome these shortcomings, the authors propose a novel particle-filter-based estimator for this problem. This new estimator provides the ability to estimate execution skill in higher dimensions and offers a framework for estimating time-varying execution skill. The outcome is an estimator capable of generating more realistic, time-varying execution skill estimates of agents, which can then be used to assist agents in making better decisions and improve their overall performance.
Related Work
Previous Skill Estimation Methods
Several estimation methods have been proposed in the literature and shown to be effective at producing execution skill estimates. These methods differ in the type of information they utilize:
- Observed Reward (OR) Method: Focuses on estimating an agent’s execution skill by analyzing the rewards it receives during interactions with the environment. This method assumes that agents are perfectly rational, which limits its applicability.
- The Bayesian Approach (TBA): Models the skill estimation problem as a Bayesian network. This method led to improved performance with a wider variety of agents but required the definition of a set of focal points for a domain.
- Joint Estimation of Execution and Decision-making Skill (JEEDS): Estimates both an agent’s execution and decision-making skill levels simultaneously. JEEDS was shown to produce far more accurate skill estimates for agents across the entire spectrum of rationality levels.
Related Research Areas
The topic of skill estimation has connections to many other lines of research, including:
- Estimating the execution error of darts players.
- Modeling the interaction between pitcher and batter in baseball.
- Opponent modeling in games like poker and real-time strategy games.
- Transfer learning in reinforcement learning.
Research Methodology
Bayesian Framework
The dynamic Bayesian network used to guide inference for the Monte Carlo Skill Estimation (MCSE) method consists of the following random variables:
- Σ: A multivariate random variable consisting of k dimensions corresponding to the execution skill parameters of the agent.
- Λ: A random variable corresponding to the decision-making skill of the agent.
- T: A random variable indicating the target action for a given observation.
- X: A random variable indicating the action that is actually executed and observed.
Particle Filter Approach
The MCSE method utilizes a particle filter to perform probabilistic inference over the space of possible skill levels. Each particle corresponds to a complete specification of an agent’s skill, including specific execution skill parameters (σ) and rationality parameter (λ). The steps of the MCSE method are as follows:
- Initialize the set of particles.
- For each observed executed action:
- Update the weight of each particle.
- Possibly resample a new set of particles.
- Perturb the parameters of each particle to account for dynamic skill.
- Generate a skill estimate as the weighted average of all particle skill parameters.
Experimental Design
Experimental Domain: Two-Dimensional Darts
The traditional game of darts has been the basis for much previous work in estimating agent skill. The authors utilize a two-dimensional darts (2D-Darts) variant where the base rewards of the traditional dartboard are randomly shuffled. This variation guarantees that each dartboard presented to an agent is different and challenging, enabling the agent to showcase its decision-making and execution abilities more explicitly.
Agents
Different types of agents, each with a unique decision-making component, were utilized for the experiments:
- Rational Agent: Selects an optimal action that will maximize its expected reward.
- Flip Agent: Employs an ϵ-greedy strategy.
- Softmax Agent: Uses the softmax function to probabilistically select an action.
- Deceptive Agent: Selects the action that is the farthest from an optimal action.
Experimental Procedure
The process used to conduct each experiment was as follows:
- Initialize each agent with the same execution skill level and a random decision-making skill level.
- Each agent repeatedly sees a state, selects a target action, and has an execution noise perturbation added to its target action.
- The final executed action is observed by each of the estimation methods, which produce an estimate after each observation.
Evaluating Execution Skill
The MCSE method produces estimates for multiple execution skill parameters. Instead of using mean squared error (MSE), the authors use Jeffreys divergence (JD) to measure the difference between the estimated execution noise distribution and the agent’s true execution noise distribution.
Results and Analysis
Estimating Execution Skill in Higher Dimensions
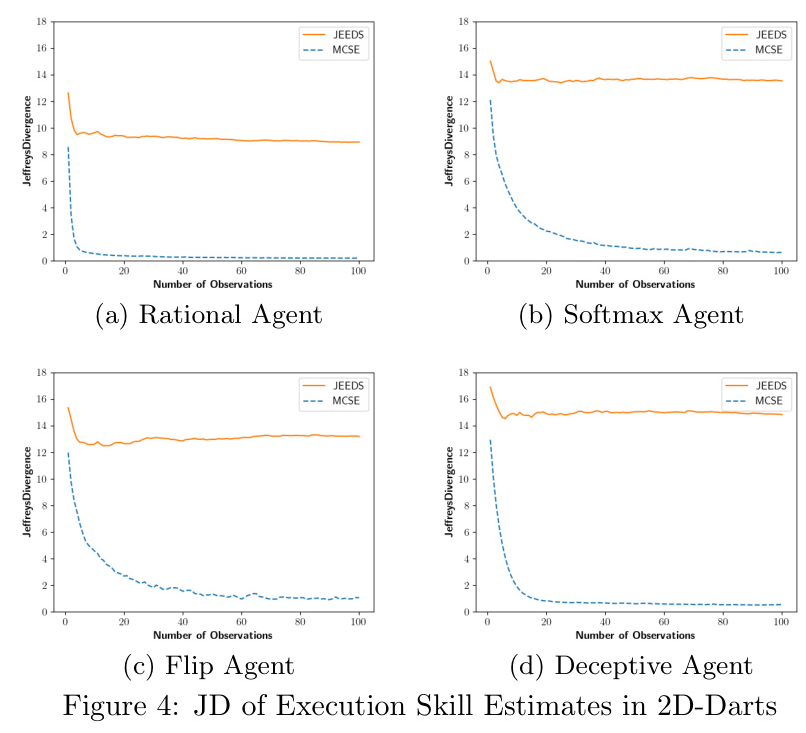
The performance of MCSE at estimating execution skill in higher dimensions was investigated. The results showed that the MCSE estimators are significantly more accurate than JEEDS when used on agents with arbitrary execution noise distributions. The average Jeffreys divergence for the MCSE estimators converges to values between 1 and 2 after 100 observations for all the different agents, while the JEEDS average JD only nears 9 for the Rational agent and is between 12 and 15 for the other agent types.
Estimating Execution Skill Over Time
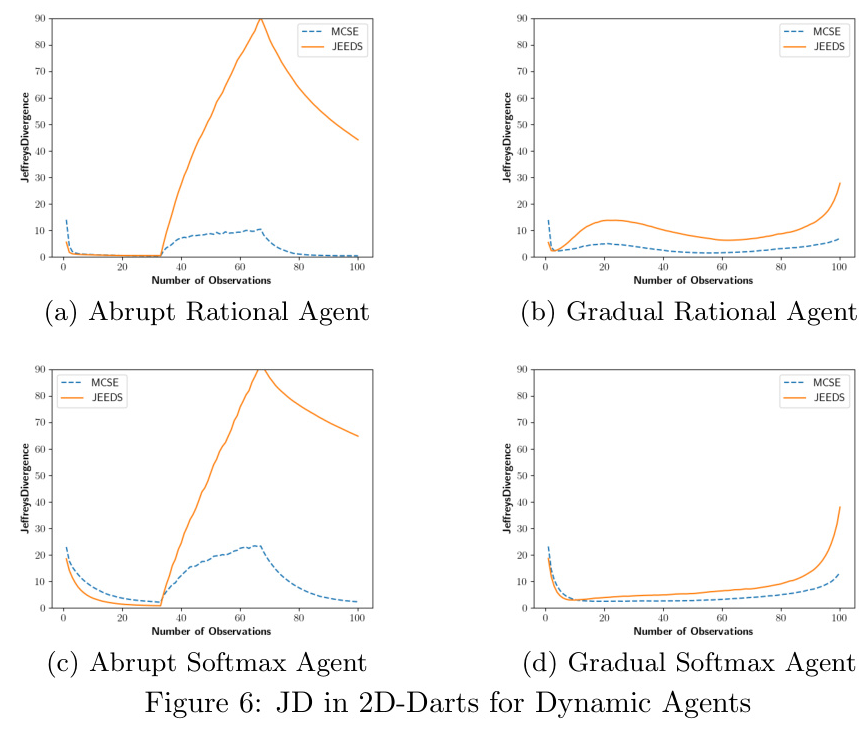
The ability of MCSE to estimate execution skill as it changes over time was explored. The results showed that MCSE exhibits smaller errors than JEEDS at this task. The abrupt execution skill changes cause massive spikes in JD for JEEDS, from which it never completely recovers. While MCSE also has more error around the changes, it is of lower magnitude and the estimate quickly recovers afterward.
Application: Skill in Baseball
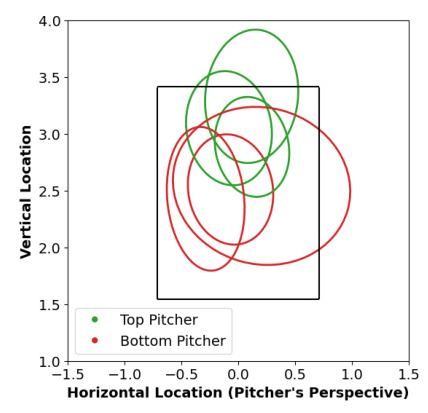
The applicability of MCSE to real-world Major League Baseball (MLB) data was demonstrated. The methods were generally able to distinguish between top-ranked and bottom-ranked pitchers by their walks per inning (BB/IP) statistic. The estimates vary significantly between estimators, and the MCSE method was able to provide more nuanced insights into the pitchers’ execution skills.
Overall Conclusion
In this paper, the Monte Carlo Skill Estimation (MCSE) method was introduced, which utilizes a particle filter to perform inference in a dynamic Bayesian network with random variables corresponding to the execution and decision-making skill of an observed agent. MCSE makes two significant contributions:
- It can model and estimate execution skill in multiple dimensions.
- It can better handle agents whose execution skill varies over time.
These properties make it a natural method to use on real-world data, as demonstrated on MLB data. Future work will explore additional enhancements and extensions of the basic particle filter approach and apply the MCSE method to additional real-world data sources.