

Authors:
Paper:
https://arxiv.org/abs/2408.06663
Introduction
The rise of large language models (LLMs) has significantly transformed the field of natural language processing (NLP). These models are typically trained using a two-stage process: pre-training on a large text corpus followed by fine-tuning to align the model with specific tasks or human preferences. This paper investigates the relationship between these two stages by fine-tuning multiple intermediate pre-trained model checkpoints. The study aims to understand how pre-training and fine-tuning interact and affect the resulting model’s performance.
Background: Model Training
Pre-training
Pre-training involves training a model on a massive text corpus to learn general language patterns. This stage has seen significant advancements, including larger training sets, different data selection mechanisms, higher quality data, and various model architectures. The goal is to create a robust base model that can be fine-tuned for specific tasks.
Fine-Tuning
Fine-tuning involves adapting the pre-trained model to specific tasks or aligning it with human preferences. This can be done through supervised fine-tuning for specific tasks or instruction fine-tuning for general-purpose usage. Fine-tuning typically yields significant improvements in downstream tasks.
Instruction Fine-Tuning
Instruction fine-tuning is used when more general model behaviors are desired. This method utilizes a reward model to simulate human feedback, often through reinforcement learning with human feedback (RLHF) or AI feedback (RLAIF).
In-Context Learning
In-context learning, also known as few-shot learning, uses a small amount of supervised data to improve model performance. This method does not change the model parameters but improves performance through better context understanding.
Fine-Tuning Techniques
Various techniques facilitate efficient fine-tuning, including parameter-efficient fine-tuning (PEFT), quantization, and specialized data filtering. This study focuses on full-parameter fine-tuning to understand the critical turning points in model training.
Experimental Setup
Model Choice
The study uses OLMo-1B, a high-performing open-source large language model. This model was chosen because it is the only one that releases intermediate pre-training checkpoints, allowing for a detailed analysis of training dynamics.
Training Procedure
The study fine-tunes each selected model checkpoint using two different procedures: supervised fine-tuning and instruction tuning. Supervised fine-tuning is conducted separately for each model checkpoint and dataset, while instruction tuning is done once using an instruction dataset.
Evaluation
The evaluation involves selecting a representative number of datasets for different types of tasks to test model abilities. The datasets include tasks like summary generation, question generation, natural language inference, and paraphrase detection.
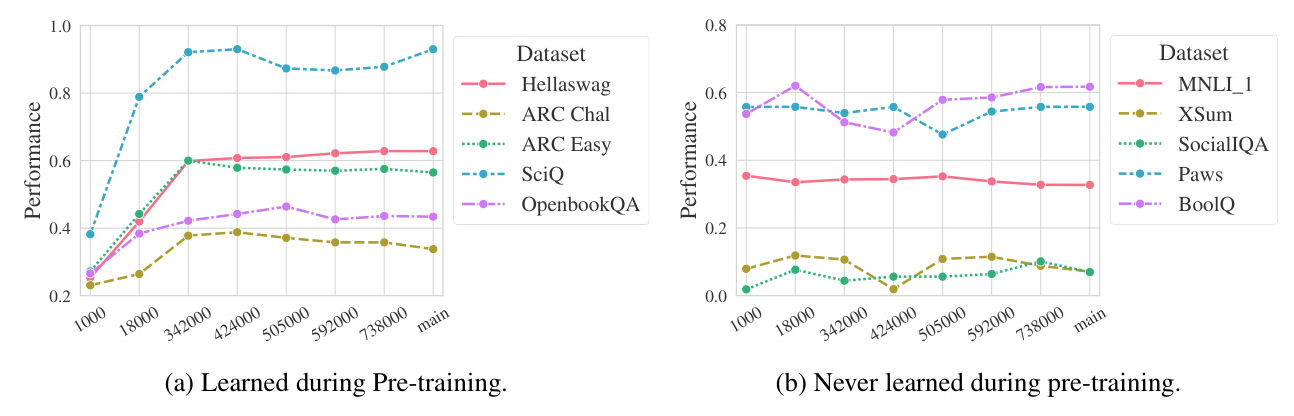
How Does the Model Change Across Pre-Training?
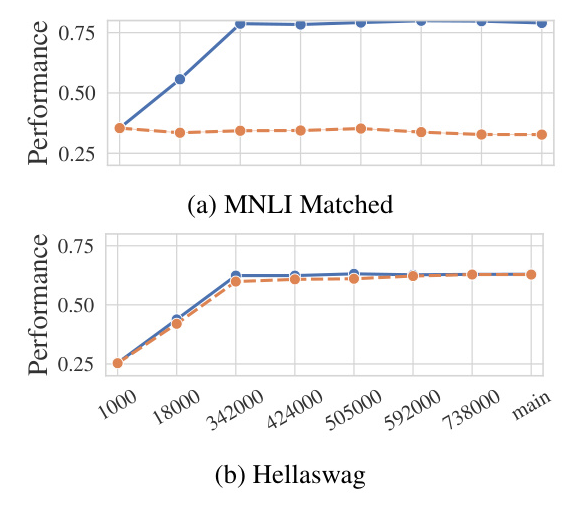
The study evaluates the pre-trained checkpoints with few-shot examples, as models without alignment tend to perform poorly in a zero-shot context. The results suggest that datasets fall into two groups: those that show improvement during pre-training and those that do not. This dichotomy is explored further by examining the fine-tuned models.
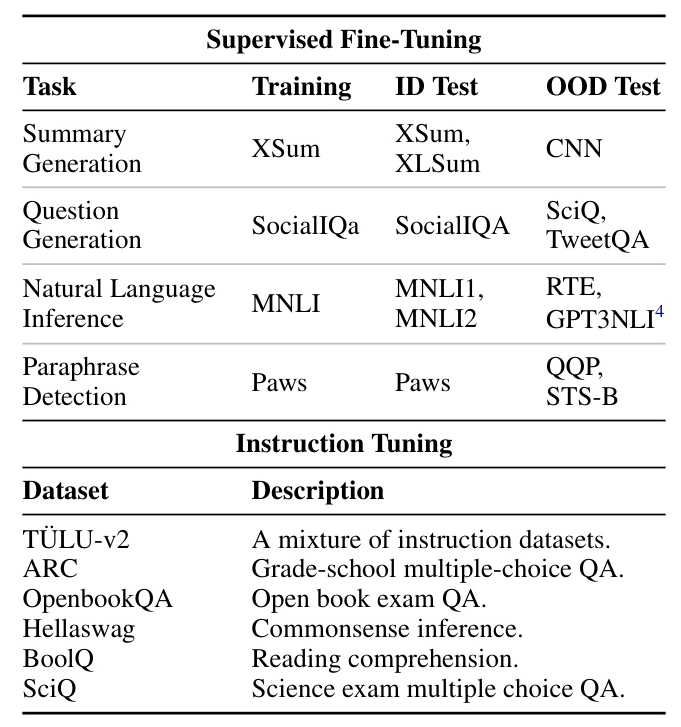
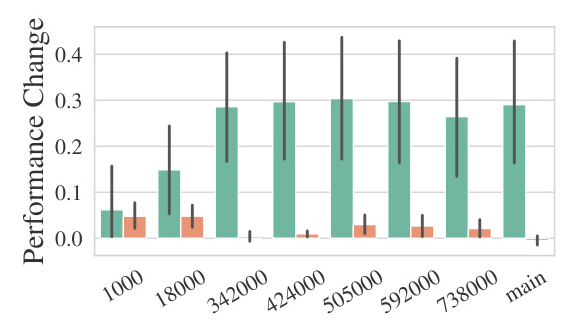
Does More Pre-Training Improve Fine-Tuning?
The study finds that datasets learned during pre-training do not benefit significantly from fine-tuning. However, datasets that are not learned during pre-training show substantial improvements with fine-tuning. This suggests that the model learns important information during pre-training, but it cannot express that information without fine-tuning.
Supervised Fine-Tuning: What Does the Model Learn and Forget?
Task Format
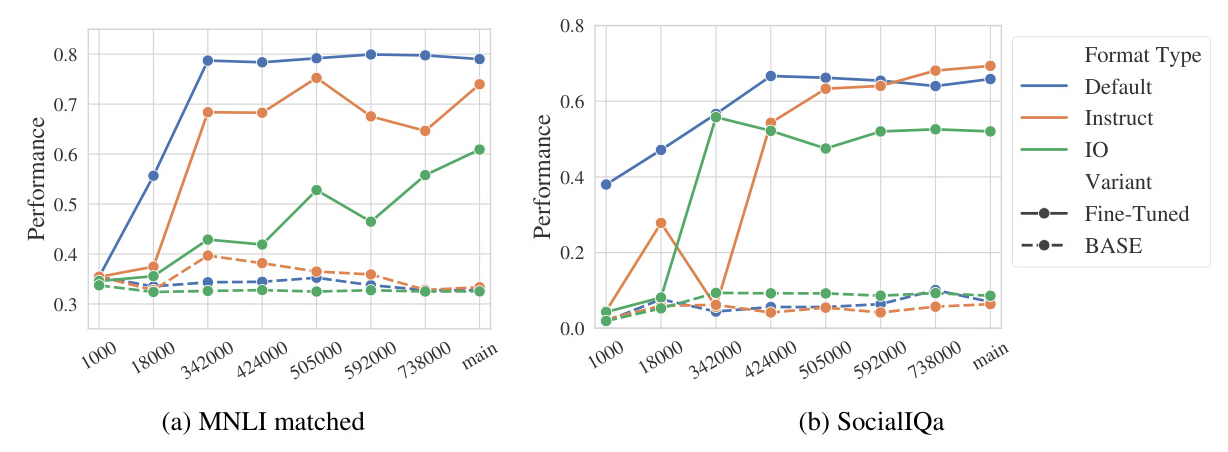
The study finds that fine-tuning fits the model to a specific task format, resulting in higher performance when the evaluation set matches this format. The model becomes more flexible with different task formats as pre-training progresses.
Task Transfer
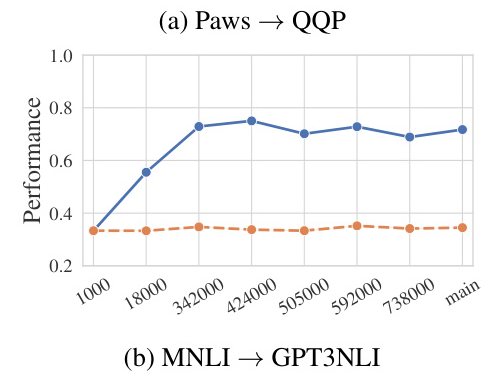
The study examines model forgetfulness by evaluating whether the model does worse on some tasks after fine-tuning for other tasks. Models fine-tuned on classification tasks lose their generation abilities, while those fine-tuned on generation tasks maintain their classification abilities.
Domain Knowledge
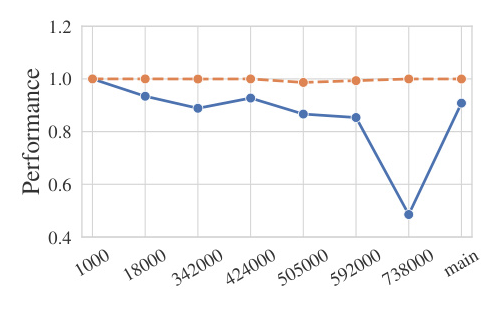
The study explores how fine-tuning affects the model’s generalization ability. Fine-tuning can cause the model to forget domain knowledge if it is not needed for the fine-tuned task. This implies that both learning and forgetting occur during fine-tuning.
Discussion
The study suggests several insights for future work:
- Dataset Dichotomy: Some datasets are learned during pre-training, while others are not. Fine-tuning provides no additional information for tasks already learned during pre-training.
- Latent Benefits: Some datasets benefit from additional pre-training, even though these benefits are not revealed without fine-tuning.
- Task Format Learning: Fine-tuning teaches the model how to format a response for a task, but it can lead to forgetting other abilities.
Conclusion
The study explores the relationship between fine-tuning and pre-training in LLMs. The findings show that the model can rapidly pick up datasets it could not solve during fine-tuning with minimal supervision. The study also identifies aspects that LLMs learn and forget during supervised fine-tuning, such as task format, task solution, and domain knowledge. The results demonstrate the value of analyzing language model training dynamics and encourage the release of pre-training checkpoints to aid future studies.
Limitations
The study acknowledges several limitations, including computational constraints, the availability of pre-training checkpoints, and the focus on a single model and a limited number of datasets. Future work should address these limitations by exploring larger models and more datasets.
Acknowledgments
The authors thank Saleh Soltan, Niyati Bafna, Fan Bai, Miriam Wanner, Xinbo Wu, and Carlos Aguirre for their helpful feedback.
Datasets:
GLUE、MultiNLI、HellaSwag、BoolQ、OpenBookQA、PAWS、ARC (AI2 Reasoning Challenge)、SciQ