

Authors:
Paper:
https://arxiv.org/abs/2408.09958
Introduction
In the realm of deep learning, the vanishing gradient problem has long been a significant challenge, particularly when training very deep neural networks. Residual Networks (ResNet) have been instrumental in addressing this issue by introducing skip connections, which allow gradients to flow directly through the network, thereby facilitating the training of much deeper networks. However, the traditional implementation of ResNet combines the input (ipd) and the transformed data (tfd) in a fixed 1:1 ratio, which may not be optimal across all scenarios.
In this paper, we introduce AdaResNet (Auto-Adapting Residual Network), a novel architecture that enhances the flexibility of ResNet by dynamically adjusting the ratio between ipd and tfd during training. This dynamic adjustment is achieved through a learnable parameter, weightipd tfd, which is optimized during backpropagation. Our experimental results demonstrate that AdaResNet significantly improves accuracy compared to traditional ResNet, particularly in tasks where the relative importance of ipd and tfd varies across different layers and datasets.
Related Work
Residual Networks and Skip Connections
ResNet, introduced by He et al. in 2016, has revolutionized the design of deep neural networks by addressing the degradation problem, where adding more layers to a network does not necessarily lead to better performance. ResNet’s skip connections allow the network to learn residual mappings, effectively mitigating the vanishing gradient problem and enabling the training of networks with over 100 layers.
Several extensions of ResNet have been proposed to further enhance its performance. Wide ResNet increases the width of the network, leading to improved performance on various datasets. ResNeXt introduces a cardinality dimension, allowing for a more flexible combination of feature maps, which has been shown to improve accuracy and efficiency.
Adaptive Mechanisms in Neural Networks
Adaptive mechanisms have been incorporated into neural networks to make models more flexible and responsive to varying data distributions. Squeeze-and-Excitation Networks (SENet) adaptively recalibrate channel-wise feature responses, enabling the network to focus on the most informative features. Adaptive learning rates, as seen in algorithms like Adam and RMSprop, have become standard practice in training deep networks.
However, adaptive mechanisms within the architecture itself, such as the one proposed in AdaResNet, are less explored. Existing methods typically focus on global adjustments rather than dynamically altering the flow of information within the network.
Limitations of Traditional Residual Networks
Traditional ResNet adds ipd and tfd without considering the varying importance of these components across different layers or training data conditions. This uniformity can lead to suboptimal performance, especially in cases where the relative importance of ipd and tfd differs significantly.
Several approaches have been proposed to modify the skip connections in ResNet. Mixed-Scale Dense Network (MSDNet) adapts the receptive field sizes across the network but does not dynamically adjust the skip connections themselves. Highway Networks introduce gates to control the flow of information through the network, but these gates are static once trained and do not adapt during training.
Research Methodology
AdaResNet Model
AdaResNet introduces a learnable parameter, weightipd tfd, which dynamically adjusts the ratio between ipd and tfd during training. This parameter is optimized through backpropagation, allowing the network to adapt to the specific characteristics of the training data.
The process of transforming input data (x) to produce output (y) in AdaResNet can be described as follows:
[ y = fact(fn(. . . (f1(x) . . . )) + weightipd tfd \cdot f ′(x)) ]
Here, weightipd tfd enables the network to learn the optimal influence of the input x on the final output y. If weightipd tfd is close to zero, the network emphasizes the transformed data over the raw input. Conversely, a larger weightipd tfd indicates a greater influence of the raw input.
Gradient Descent Algorithm
The update formula for the parameter weightipd tfd during each training step is given by:
[ weight_{tfd}^{ipd} \leftarrow weight_{tfd}^{ipd} – \eta \frac{\partial L}{\partial weight_{tfd}^{ipd}} ]
where η is the learning rate, and (\frac{\partial L}{\partial weight_{tfd}^{ipd}}) is the gradient of the loss function with respect to weightipd tfd. This update step is repeated for each batch of training data across multiple epochs, leading to an optimized result from the training data.
Experimental Design
Experimental Setup
To validate the effectiveness of AdaResNet, we conducted comparative experiments using three different approaches: (1) AdaResNet with a trainable weight, (2) traditional ResNet 50, and (3) a method using a fixed weight (2x) instead of a trainable one. The experiments were performed on the CIFAR-10 dataset, which consists of 60,000 32×32 color images in 10 classes.
Training Process
The training process of AdaResNet involves the following steps:
- Forward Pass of weightipd tfd: The custom layer receives inputs ipd and the intermediate result tfd, and then calculates the output as tfd + weightipd tfd · ipd.
- Calculating the Loss Function: The model output is compared with the true labels to compute the loss function.
- Backward Pass: The backpropagation algorithm calculates the gradients of the loss function with respect to the model parameters, including weightipd tfd.
- Updating the Parameters: The optimizer updates all trainable parameters, including weightipd tfd, based on the computed gradients.
Results and Analysis
Accuracy
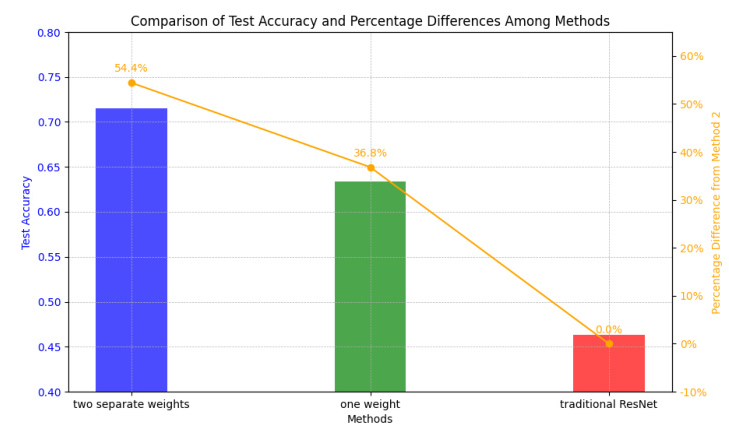
The comparison of training and validation accuracy for each method over 10 epochs is shown in Figures 3 and 4. AdaResNet consistently outperforms traditional ResNet, achieving higher accuracy on both training and test data. Specifically, AdaResNet with two separate weights achieves the highest final test accuracy of 0.81, which is a significant improvement over the traditional ResNet method with an accuracy of 0.46.
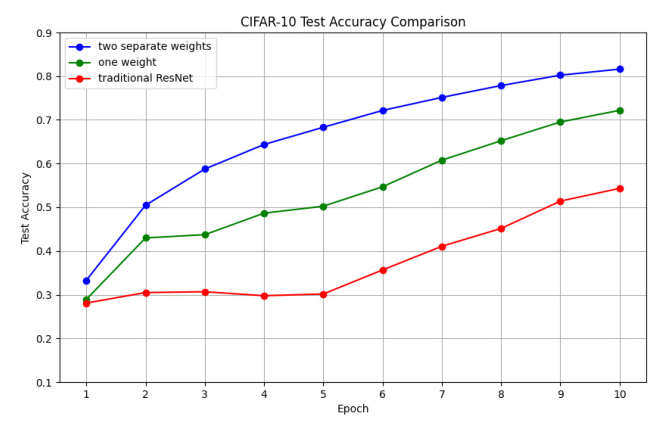
Weights Impact
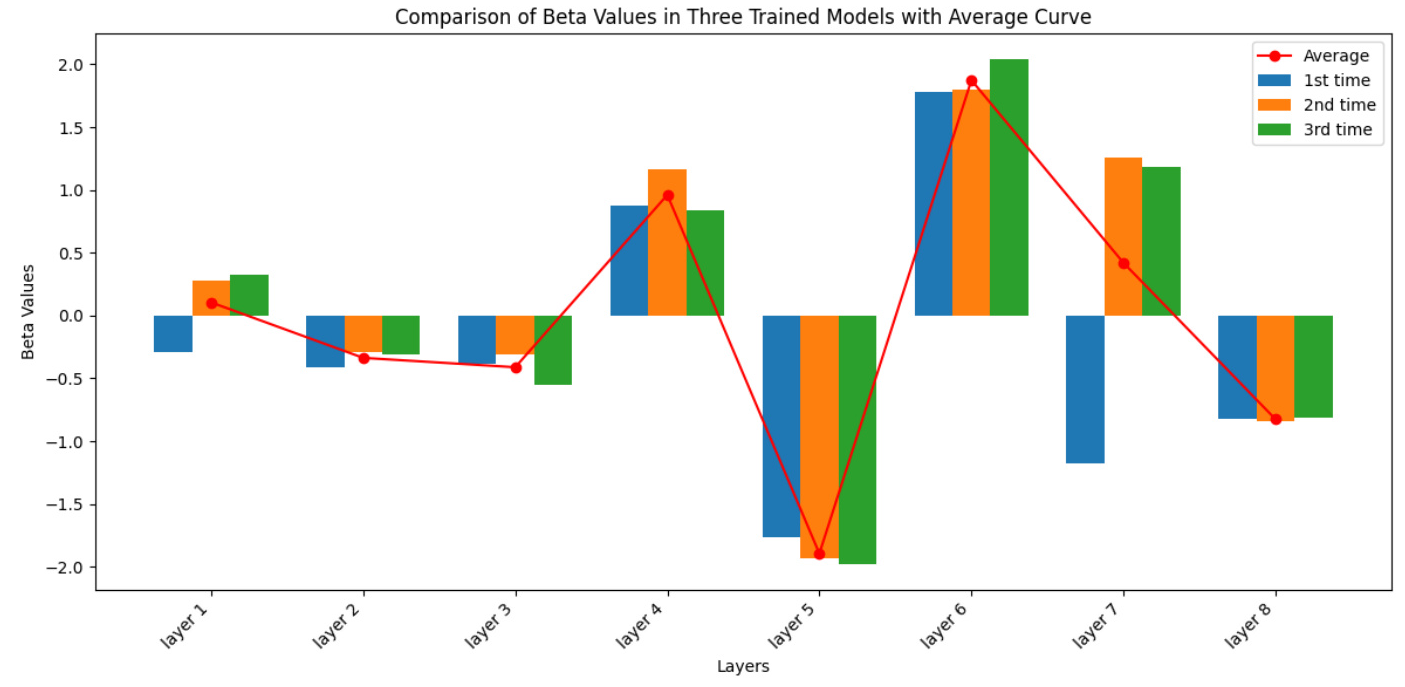
To verify that weightipd tfd is a dynamic parameter, we output the weightipd tfd after each training iteration. The results show that the weights differ between layers and across different training tasks, indicating that a fixed value for the combination of input and the intermediately processed data is not suitable.
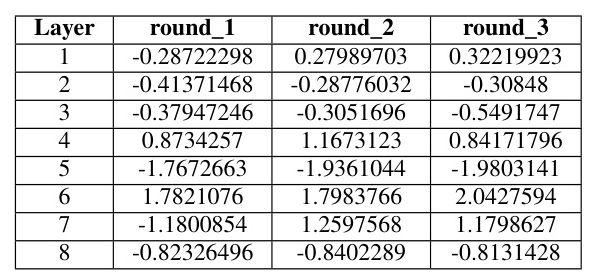
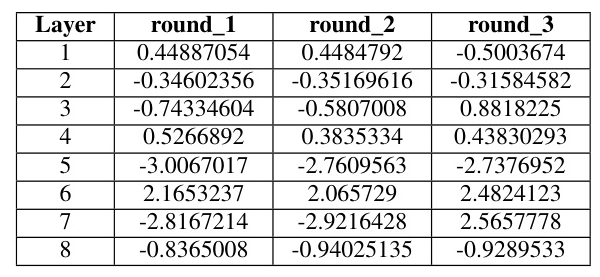
The variance analysis between the CIFAR-10 and MNIST datasets further highlights the differences in weightipd tfd values, underscoring the need for dynamic adjustment during training.
Overall Conclusion
AdaResNet represents a significant advancement in the design of deep neural networks by introducing an adaptive mechanism for dynamically balancing the contributions of skipped input (ipd) and processed data (tfd). This approach addresses the limitations of traditional ResNet, which relies on a fixed 1:1 ratio for combining ipd and tfd. By allowing the ratio to be adjusted dynamically during training, AdaResNet enhances the model’s adaptability and overall performance.
Our experimental results demonstrate that AdaResNet consistently outperforms traditional ResNet, particularly in tasks where the relative importance of ipd and tfd varies across different layers and datasets. This work opens up new possibilities for further exploration of adaptive mechanisms in neural networks, with potential applications across various domains in deep learning.
Future work will focus on extending the AdaResNet framework to other network architectures and exploring the impact of adaptive mechanisms in different types of neural networks, such as those used in natural language processing and reinforcement learning. Additionally, we plan to investigate the theoretical underpinnings of adaptive skip connections to better understand their role in improving network generalization and robustness.