Authors:
Alessio Devoto、Federico Alvetreti、Jary Pomponi、Paolo Di Lorenzo、Pasquale Minervini、Simone Scardapane
Paper:
https://arxiv.org/abs/2408.08670
Introduction
Vision Transformers (ViTs) have emerged as a powerful paradigm in computer vision, leveraging the self-attention mechanism to capture long-range dependencies in images. However, the fine-tuning process of ViTs is resource-intensive, posing challenges for deployment in edge or low-energy applications. This paper introduces ALaST (Adaptive Layer Selection Fine-Tuning for Vision Transformers), a method designed to optimize the fine-tuning process by adaptively allocating computational resources to different layers based on their importance. This approach significantly reduces computational cost, memory load, and training time.
Background on Vision Transformer
A Vision Transformer (ViT) processes an image through a series of transformer layers, transforming the image into a sequence of tokens. The architecture involves an encoding network that splits the image into patches, which are then flattened and projected into a lower-dimensional embedding space. The transformer layers process these tokens through multi-head self-attention and feed-forward neural networks, with the final classification performed by a classification head.
Layer Contributions during Fine-tuning
Not all layers in a transformer contribute equally during fine-tuning. Some layers, particularly in pre-trained models, function almost like identity mappings, providing minimal updates to the token embeddings. This observation is crucial for optimizing the fine-tuning process, as it allows for the identification of layers that can be frozen or processed with fewer tokens to save computational resources.
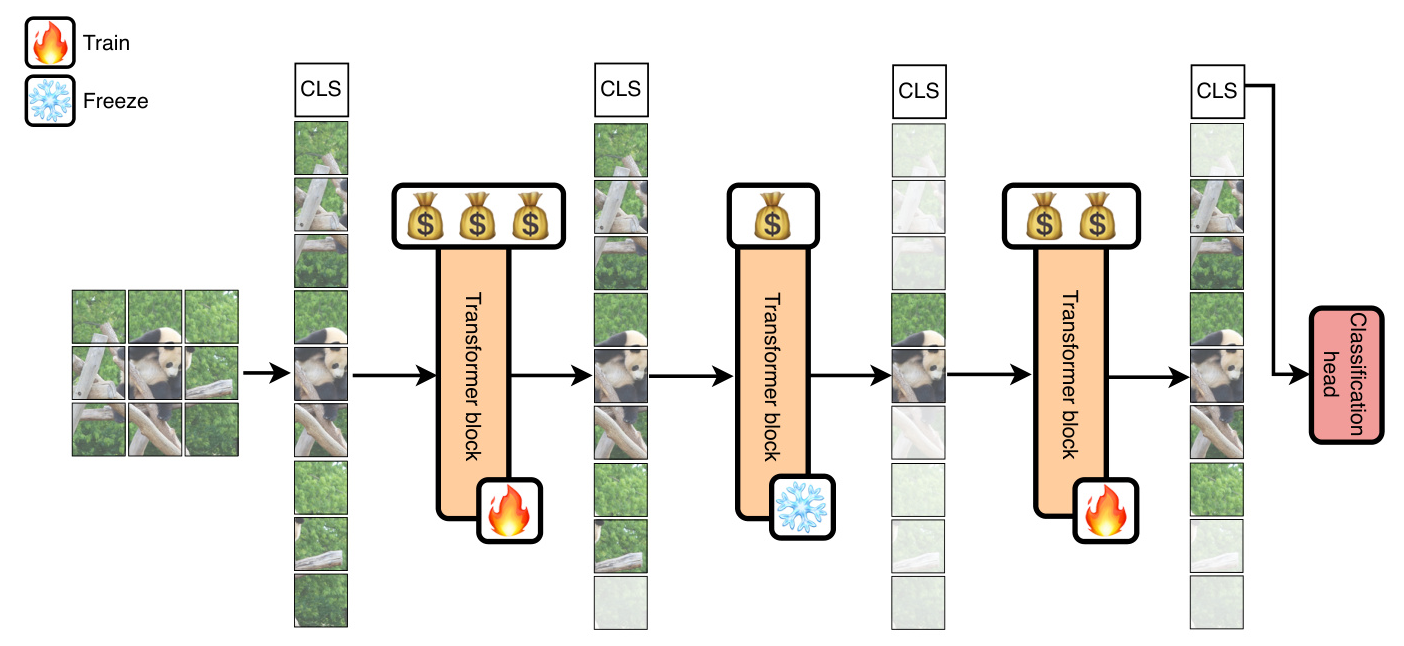
Adaptive Layer Selective Fine-tuning
The ALaST method adaptively estimates the importance of each layer during fine-tuning and allocates computational resources accordingly. This is achieved by assigning a “compute budget” to each layer, which determines whether the layer is frozen or trainable and how many tokens it processes. The method involves two key strategies: adaptive token selection and adaptive layer freezing.
Estimating the Importance of Each Layer
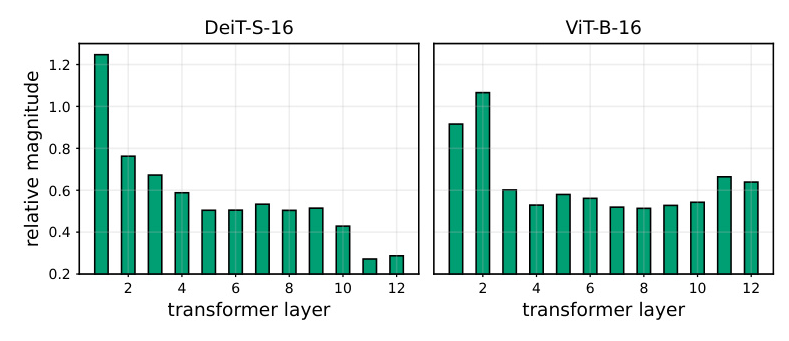
The importance of each layer is estimated based on the variations in the class token embedding, which aggregates information from all other tokens. The class token delta, defined as the change in the class token embedding at each layer, is used to compute the training budget for each layer. Layers with higher contributions to the class token receive higher budgets, while less critical layers receive lower budgets.
Applying the Budget
The compute budget is applied by adjusting the number of tokens processed by each layer and freezing less critical layers. Tokens are selected based on their attention scores from the class token, retaining only the most important tokens. Layers with the lowest budgets are frozen to save memory and computational resources.

Experimental Setup
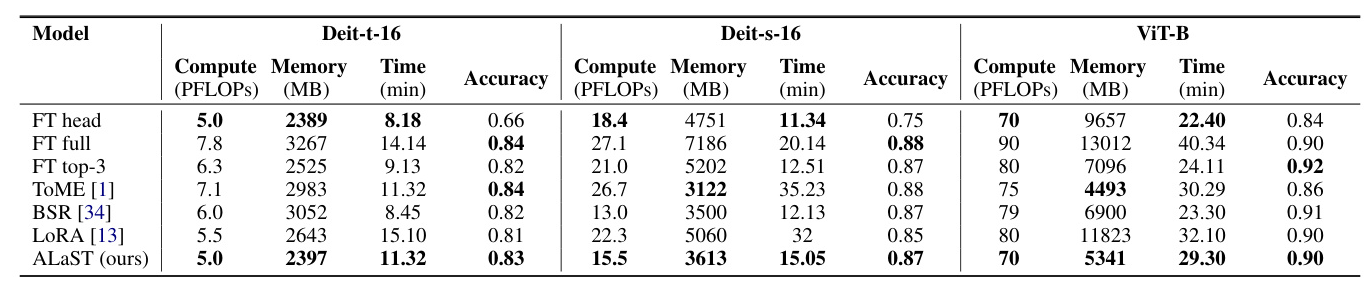
The ALaST method was tested on several datasets, including Flower-102, Cifar-100, and Food-101, using pre-trained Vision Transformers such as ViT-B, DeiT-S, and DeiT-T. The experiments involved mixed precision training to simulate real-world on-device training scenarios. Metrics such as FLOPs, memory load, and wall-clock time were tracked to assess the performance and resource utilization of the method.
Results & Analysis
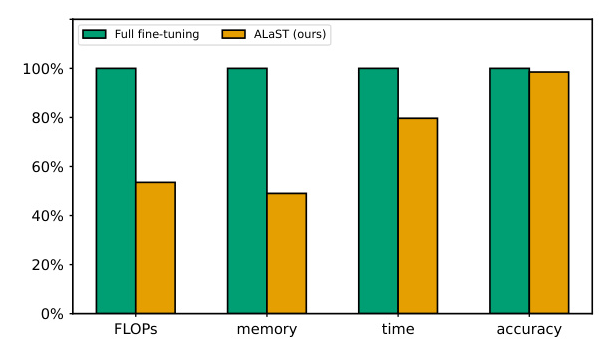
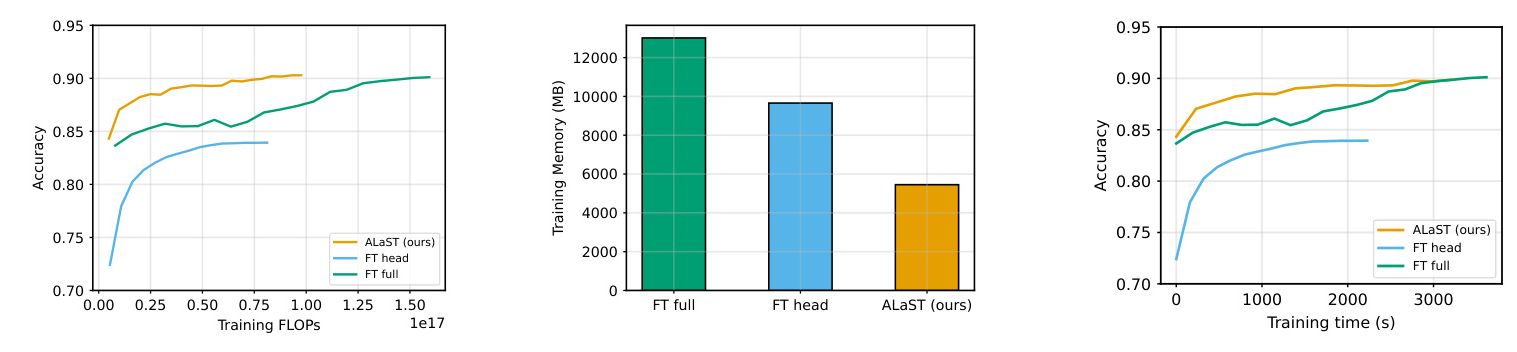
ALaST demonstrated significant improvements in efficiency compared to traditional fine-tuning approaches. The method achieved similar accuracy with only 60% of the FLOPs, 50% of the memory, and 80% of the fine-tuning time relative to full fine-tuning. ALaST also outperformed other parameter-efficient fine-tuning methods, such as LoRA and Token Merging, by dynamically allocating computational resources to the most critical layers.

Comparison to Other Methods
The method was compared to several baselines, including full fine-tuning, training only the classification head, and other state-of-the-art techniques. ALaST achieved competitive accuracy while significantly reducing computational and memory requirements. The dynamic allocation of compute budgets allowed for efficient resource management, making it well-suited for resource-constrained scenarios.
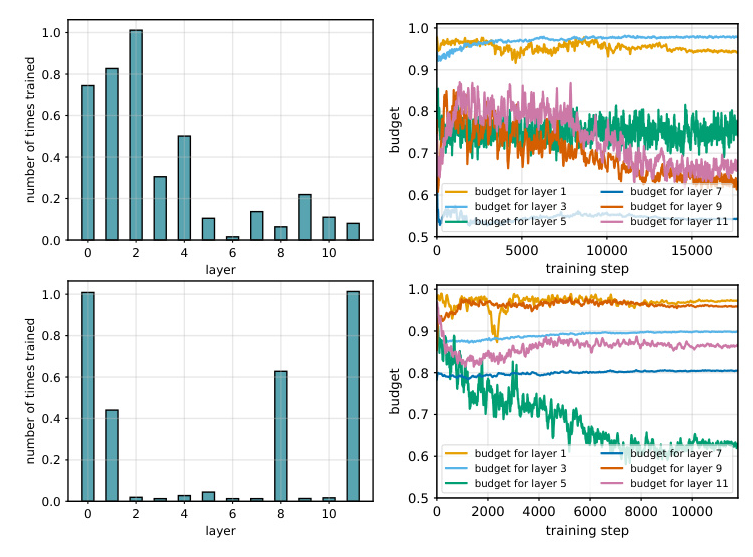
Layer Budgets across Fine-tuning
The compute budgets for different layers varied dynamically during fine-tuning. Higher budgets were typically allocated to the first layers, while central layers received lower budgets. This dynamic allocation ensured efficient use of computational resources throughout the training process.
Related Works
Parameter Efficient Fine-Tuning
Parameter-efficient fine-tuning (PEFT) methods, such as adapters, prefix-tuning, and LoRA, have been developed to optimize the number of additional parameters during fine-tuning. However, these methods often focus on parameter count rather than overall computational load. ALaST, in contrast, reduces both FLOPs and memory without adding additional parameters.
On-device Training
On-device training methods aim to optimize resource usage for training models on devices with limited computational resources. Techniques such as recomputing activations and smart initialization have been explored. ALaST builds on these approaches by dynamically learning the importance of individual layers during fine-tuning.
Efficient Transformers
Research on efficient transformers has focused on enhancing the efficiency of ViTs during inference. Methods such as token halting, distillation, and quantization have been proposed. ALaST addresses the challenge of fine-tuning ViTs in resource-constrained environments, complementing these inference-focused approaches.
Conclusions
ALaST is a simple and effective method for fine-tuning Vision Transformers in low-resource scenarios. By dynamically allocating computational resources to the most critical layers, ALaST reduces computational cost, memory load, and training time with minimal modifications to the training pipeline. The principles of ALaST are generalizable to other transformer-based architectures, offering potential for further exploration in future work.