

Authors:
Michał Bortkiewicz、Władek Pałucki、Vivek Myers、Tadeusz Dziarmaga、Tomasz Arczewski、Łukasz Kuciński、Benjamin Eysenbach
Paper:
https://arxiv.org/abs/2408.11052
Introduction
Self-supervised learning has revolutionized various domains within machine learning, such as natural language processing and computer vision. However, its application in reinforcement learning (RL) has not seen similar success. This paper addresses the challenges faced by self-supervised goal-conditioned reinforcement learning (GCRL) methods, particularly the lack of data from slow environments and unstable algorithms. The authors introduce JaxGCRL, a high-performance codebase and benchmark for self-supervised GCRL, which enables researchers to train agents for millions of environment steps in minutes on a single GPU. This paper aims to provide a foundation for future research in self-supervised GCRL by combining GPU-accelerated environments with a stable, batched version of the contrastive reinforcement learning algorithm.
Related Work
Goal-Conditioned Reinforcement Learning
Goal-conditioned reinforcement learning (GCRL) is a subset of multi-task reinforcement learning where tasks are defined by goal states that the agent aims to reach. GCRL has been successful in domains such as robotic manipulation and navigation. Recent work has shown that goal representations can be structured to enable capabilities like language grounding, compositionality, and planning. This paper builds on contrastive learning techniques to scale GCRL with GPU acceleration.
Accelerating Deep Reinforcement Learning
Deep RL has become practical for many tasks due to improvements in hardware support. Distributed training has enabled RL algorithms to scale across hundreds of GPUs. GPU-accelerated environments reduce CPU-GPU data-transfer overhead and can be vectorized to collect data from hundreds of rollouts in parallel. This paper leverages these advances to scale self-supervised GCRL across orders of magnitude more data than previously possible.
Self-Supervised RL and Intrinsic Motivation
Self-supervised training has enabled breakthroughs in language modeling and computer vision. In RL, self-supervised techniques learn through interaction with an environment without a reward signal. Intrinsic motivation methods, such as curiosity and surprise minimization, compute their own reward signals. This paper aims to address the bottleneck of large numbers of environment interactions by providing a fast and scalable implementation for contrastive, self-supervised RL.
RL Benchmarks
The RL community has focused on improving how RL research is conducted, reported, and evaluated. Reliable and efficient benchmarks are essential for rigorous comparison of novel methods. This paper proposes a stable contrastive algorithm and a suite of goal-reaching tasks that enable meaningful RL research on a single GPU by significantly reducing the cost of running experiments.
Research Methodology
Self-Supervision through Goal-Conditioned Reinforcement Learning
In GCRL, an agent interacts with a controlled Markov process (CMP) to reach arbitrary goals. The goal-conditioned policy receives both the current observation and a goal observation. The objective is to learn a policy that maximizes the probability of reaching the goal. This paper extends previous work by viewing the learning of this policy as a classification problem, training a critic to classify whether a goal state is the goal of a trajectory or a negative sample.
Contrastive Representations for Goal-Reaching
The paper uses the infoNCE objective, modified to use a symmetrized critic parameterized with ℓ2-distances, to learn the critic. The critic is trained on batches of state-action-goal tuples to classify whether the goal is the goal state of the trajectory. The policy is learned using a DDPG-style policy extraction loss, with goals sampled from the same trajectories as the states and actions.
Experimental Design
New Implementation and Benchmark
The key contribution of this paper is the fast implementation of state-based self-supervised RL algorithms and a new benchmark of BRAX-based environments. The implementation leverages GPU-accelerated simulators to reduce the time required for data collection and training. The benchmark includes eight diverse continuous control environments, ranging from simple tasks to complex, exploration-oriented tasks.
Training Speedup from Environment Vectorization on a Single GPU
The proposed implementation is evaluated by executing the basic goal-conditioned contrastive RL method using both the original and novel repositories. The experiments were conducted on an NVIDIA V100 GPU, showing a 22-fold speedup in training time. The implementation uses only one CPU thread and has low RAM usage, as all operations are computed on the GPU.
Benchmark Environments
The benchmark consists of eight environments: Reacher, Half Cheetah, Pusher (easy and hard), Ant, Ant Maze, Ant Soccer, Ant Push, and Humanoid. These environments test various aspects of RL, such as spatial navigation, object manipulation, and long-horizon reasoning.
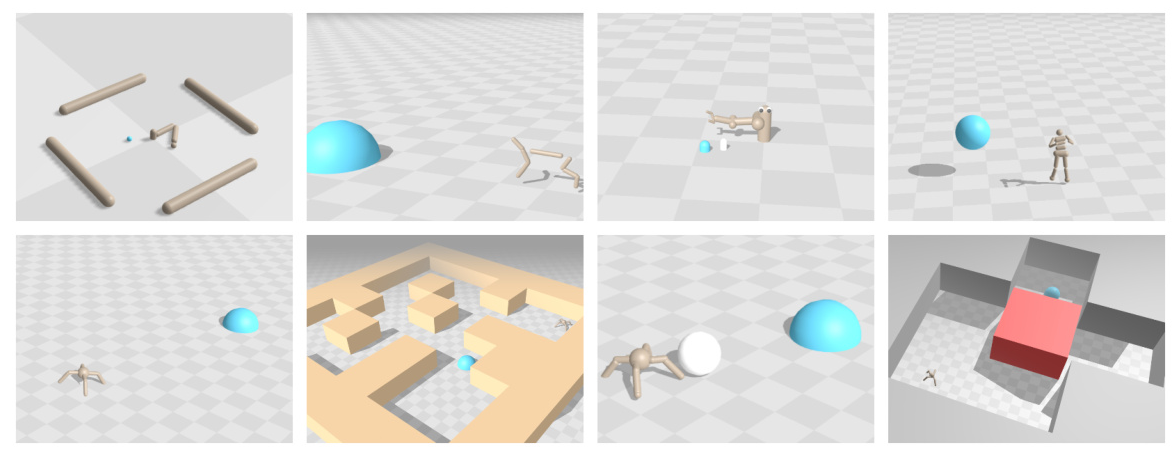
Results and Analysis
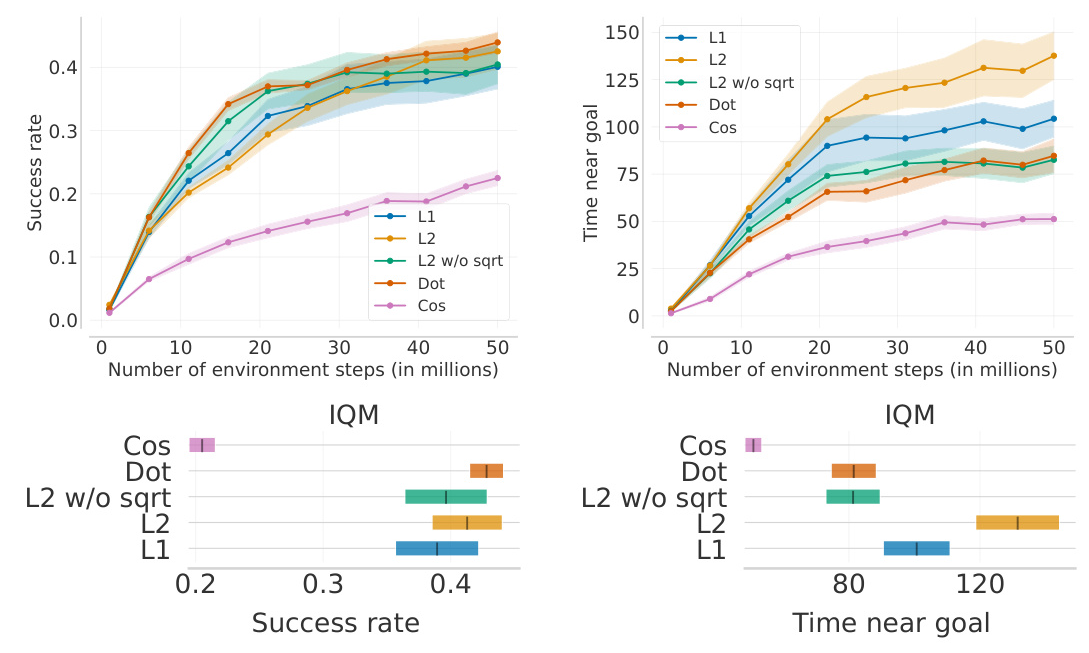
Contrastive RL Design Choices
The performance of contrastive learning is sensitive to the choice of energy function and contrastive loss. The paper evaluates five energy functions (L1, L2, L2 without sqrt, dot product, and cosine) and several contrastive losses (InfoNCE, FlatNCE, Forward-Backward, DPO, and SPPO). The results show that p-norms and dot product significantly outperform cosine similarity, and InfoNCE-derived objectives perform best among the tested contrastive losses.
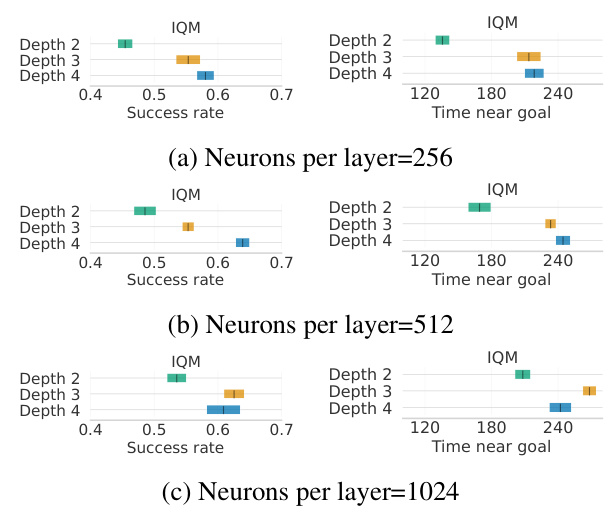
Scaling the Architecture
The paper examines the impact of scaling actor and critic neural networks in terms of depth and width. The results indicate that deeper architectures improve performance, but training destabilizes when scaling to very deep and wide architectures. Adding Layer Normalization before every activation allows better scaling.
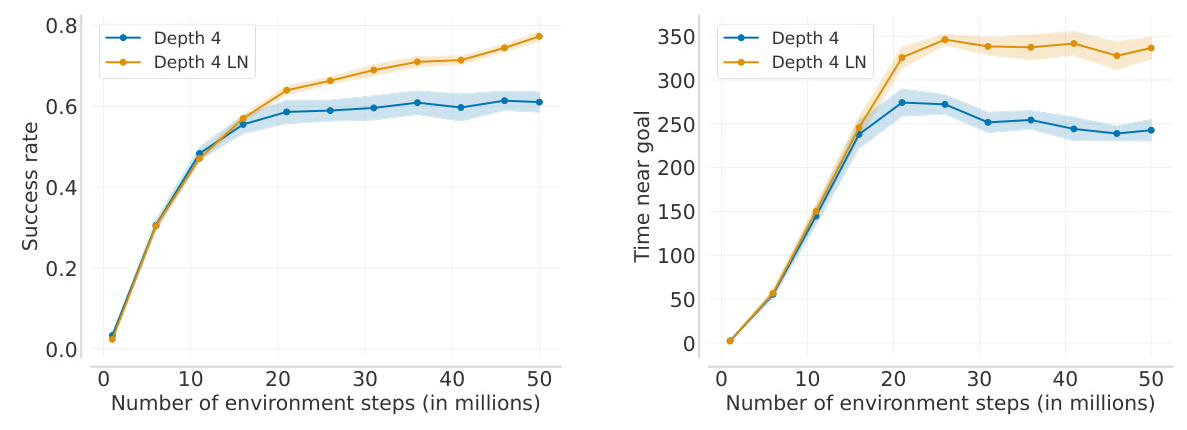
Effect of Layer Normalization
Layer Normalization improves the performance of deep and wide architectures, enabling further scaling. The results show that Layer Normalization mitigates catastrophic overestimation by bounding the Q-values for actions outside the offline dataset.
Scaling the Data
The paper evaluates the performance of different combinations of energy functions and contrastive objectives in a big data setup. The L2 energy function with the InfoNCE objective and a 0.1 logsumexp penalty configuration outperforms all others, indicating that only a subset of design choices performs well in effectively scaling Contrastive RL.
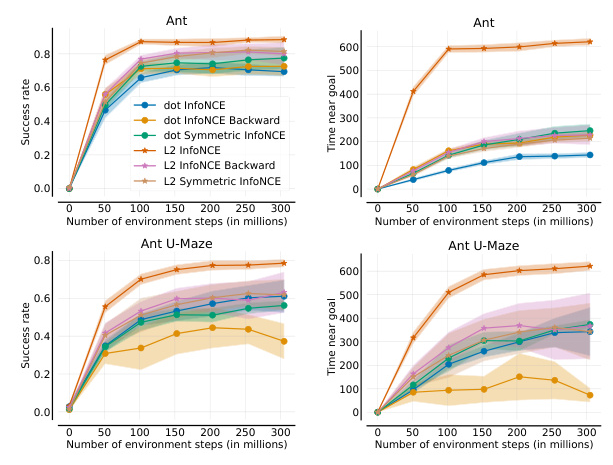
Benchmark Baselines
The final hyperparameter configuration for the benchmark includes Symmetric InfoNCE loss, L2 energy function with a 0.1 logsumexp penalty, and four hidden layers with 1024 neurons each. The results show that the proposed method achieves high success rates across various environments.
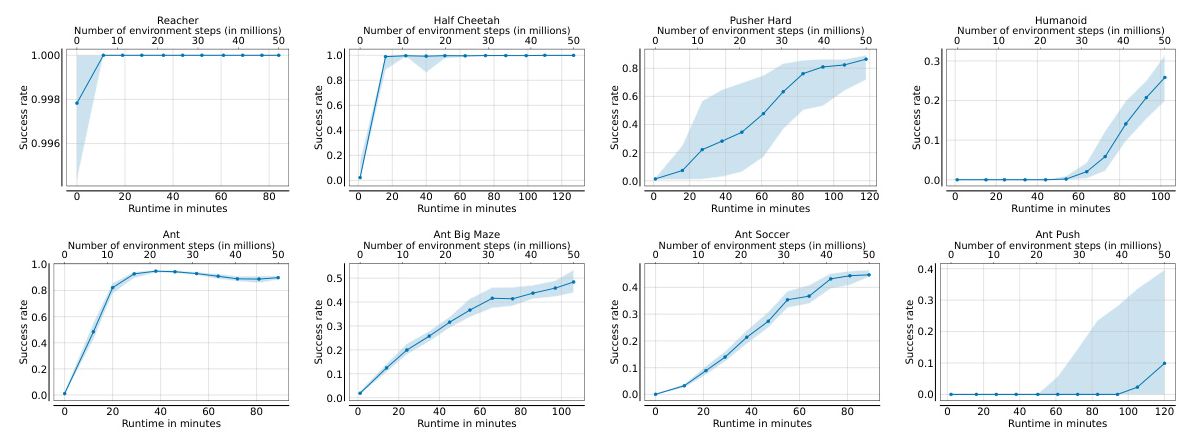
Overall Conclusion
This paper introduces JaxGCRL, a high-performance codebase and benchmark for self-supervised goal-conditioned reinforcement learning. The proposed implementation leverages GPU-accelerated simulators to enable rapid experimentation, significantly reducing the time required for data collection and training. The benchmark includes diverse environments that test various aspects of RL, providing a practical tool for the community to develop and evaluate new algorithms efficiently. The results demonstrate that the proposed method achieves high success rates across various environments, paving the way for future research in self-supervised GCRL.
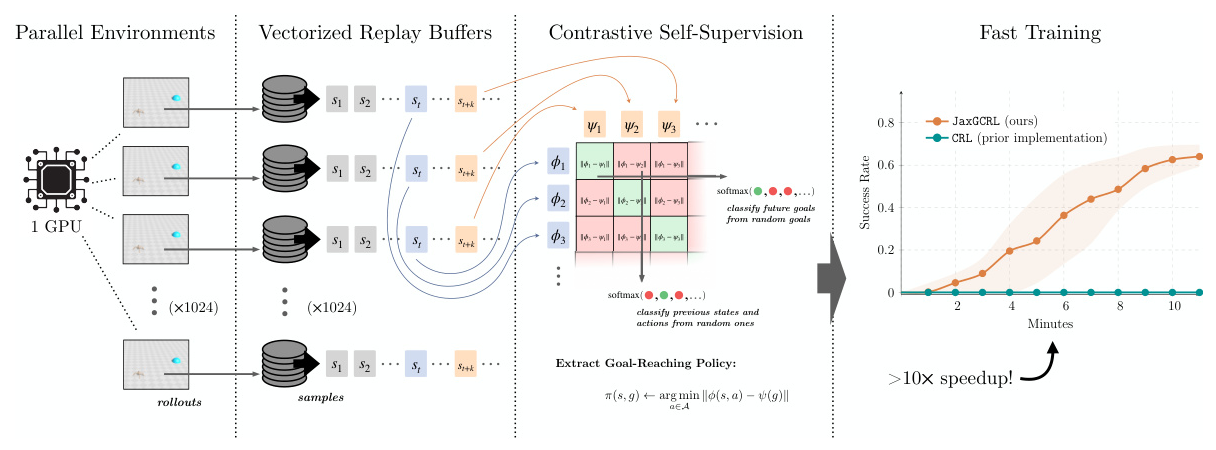
The key contribution of this work is to democratize self-supervised RL research, enabling researchers from less-resourced institutions to conduct state-of-the-art experiments on a single GPU. The open-sourced codebase provides easy-to-implement self-supervised RL methods, making RL research more accessible and reproducible. Future work should relax the assumptions of full observability and goal sampling during training rollouts, and investigate hardware-accelerated environments and algorithms in the offline setting.
Code:
https://github.com/michalbortkiewicz/jaxgcrl