

Authors:
Yuxiao Wang、Qiwei Xiong、Yu Lei、Weiying Xue、Qi Liu、Zhenao Wei
Paper:
https://arxiv.org/abs/2408.10641
Introduction
With the rapid increase in image data, understanding and analyzing the content within these images has become a significant challenge. Human-object interaction (HOI) detection has emerged as a crucial technology in computer vision, aiming to accurately locate humans and objects in images or videos and recognize the corresponding interaction categories to better understand human activities. Specifically, HOI detection outputs a series of triplets (
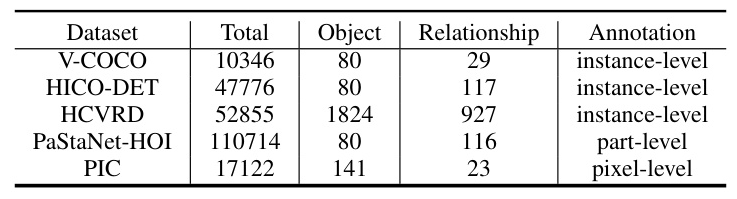
Datasets
Several excellent HOI detection datasets have emerged over the years, categorized based on annotation granularity into instance-level, part-level, and pixel-level. Here are some of the mainstream datasets:
- V-COCO: Based on COCO, it contains 10,346 images with 80 object categories and 29 action categories.
- HICO-DET: Introduced by the University of Michigan, it comprises 47,776 images with 80 object categories and 117 action categories.
- HCVRD: Constructed by the University of Adelaide, it includes nearly 10,000 categories, focusing on interaction relationships and relative positional relationships.
- PaStaNet-HOI: Developed by Shanghai Jiao Tong University, it provides approximately 110,000 annotated images with 116 interaction relationships and 80 object categories.
- PIC: Created by Liu et al., it includes 17,122 human-centered images with pixel-level annotations for precise localization.
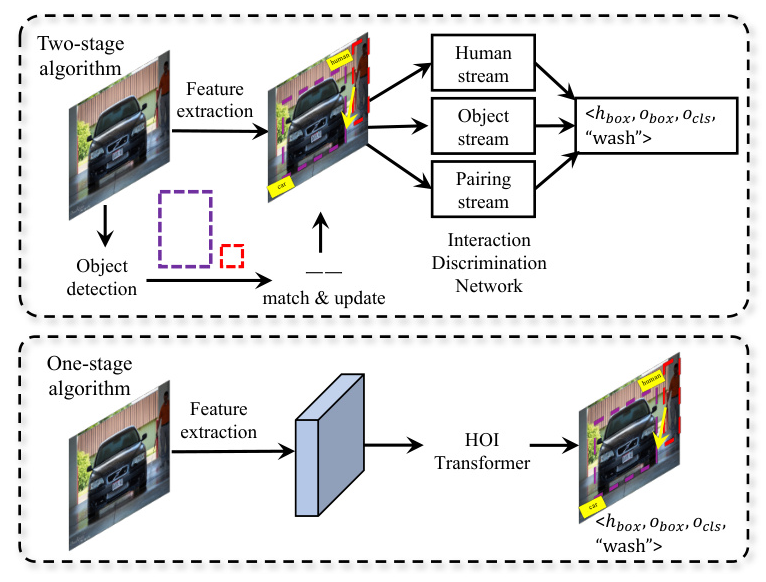
The Architectures of HOI Detection
HOI detection algorithms are primarily divided into two categories: two-stage and one-stage (end-to-end) methods.
Two-stage HOI Detection Architecture
Two-stage HOI detection is an instance-guided, bottom-up deep learning approach, divided into multi-stream models and graph models.
Multi-stream Models
Multi-stream models are an early attempt in HOI detection. They involve generating region proposals about humans and objects, extracting features, and fusing classification results. Notable models include:
- HO-RCNN: Extracts features of spatial relationships between humans and objects.
- InteractNet: Uses human appearance to predict the location of target objects.
- Interaction-aware Network: Learns general interaction knowledge from several HOI datasets.
Graph Models
Graph models address the limitations of multi-stream models by using nodes and edges to identify instances and interaction relationships. Notable models include:
- Graph Parsing Neural Network (GPNN): Introduces nodes and edges for instance and interaction relationship identification.
- Relational Pairwise Neural Network (RPNN): Utilizes object-body part and human-body part relations to analyze pairwise relationships.
One-stage HOI Detection Architecture
One-stage algorithms surpass traditional two-stage models in both speed and accuracy by directly outputting HOI triplets.
Bounding Box-based Models
These models detect the location and category of targets using a simple structure while predicting potential interaction relationships. Notable models include:
- UnionDet: Captures interaction regions directly, significantly improving inference speed.
- DIRV: Focuses on interaction regions of each human-object pair at different scales.
Relationship Point-based Models
Inspired by anchor-free detectors, these models redefine the HOI triplet as
- IP-Net: Views HOI detection as a keypoint detection problem.
- PPDM: Reduces computational costs by filtering interaction points.
Query-based Models
These models use transformer-based feature extractors where the attention mechanism and query-based detection play key roles. Notable models include:
- HOTR: Predicts triplets from images directly, leveraging inherent semantic relationships.
- GEN-VLKT: Eliminates the need for post-matching by using a dual-branch approach.
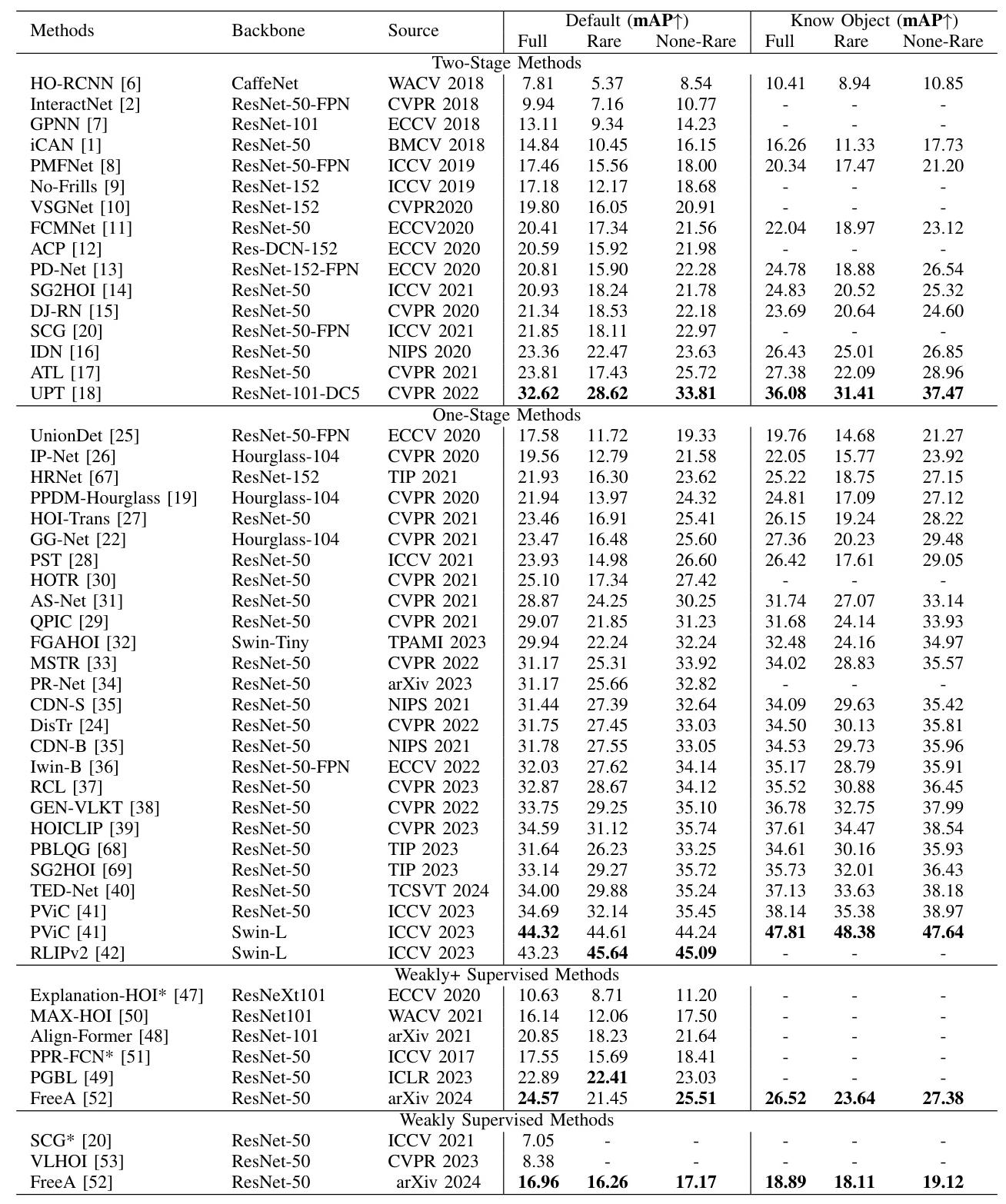
New Techniques
Zero-shot Learning
Zero-shot learning addresses the long-tail problem in HOI detection by enabling the detection of new verb-object combinations during the testing phase. Notable works include:
- Maraghi et al.: Utilize zero-shot learning methods to address the long-tail problem.
- Peyre et al.: Develop a model that merges semantic and visual spaces.
Weakly Supervised Models
Weakly supervised HOI detection uses image-level interaction labels for training. Notable works include:
- Peyre et al.: Introduce a weakly supervised discriminative clustering model.
- Align-Former: Equipped with an HOI alignment layer that generates pseudo aligned human-object pairs.
Large-scale Language Models
Large language models help query possible interactions between human and object categories using only image-level labels. Notable works include:
- ProposalCLIP: Predicts categories of objects without annotations.
- CLIP-guided HOI representation: Integrates prior knowledge at both the image level and the human-object pair level.
Complex Problem of HOI Detection
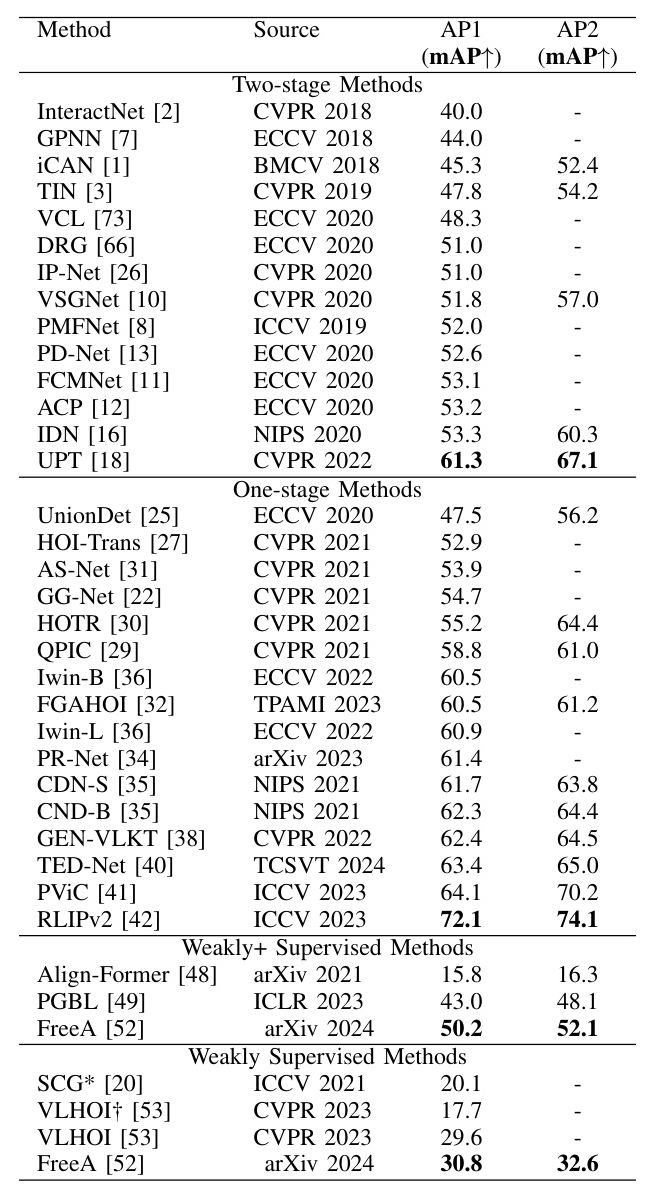
The performance of different methods on the HICO-DET and V-COCO datasets highlights the strengths and weaknesses of two-stage and one-stage methods. Two-stage methods decouple object detection and interaction classification but face challenges such as imbalanced sample distributions and additional computational costs. One-stage methods improve efficiency and accuracy but may suffer from task interference.
Conclusion
HOI detection is a research hotspot in computer vision with widespread applications. This paper discusses the latest advancements in two-stage and one-stage HOI detection tasks, introducing new techniques such as zero-shot learning, weakly supervised learning, and large-scale language models. Despite significant progress, challenges remain, and future research should focus on improving dataset diversity, enhancing multi-task learning strategies, and incorporating more contextual information to further advance the field.