

Authors:
Geonhee Kim、Marco Valentino、André Freitas
Paper:
https://arxiv.org/abs/2408.08590
Introduction
Transformer-based Language Models (LMs) have achieved remarkable success across various natural language processing tasks. This success has led to increased interest in understanding the reasoning capabilities that emerge during pre-training. Recent studies suggest that logical reasoning abilities may emerge in large-scale models or through transfer learning on specialized datasets. However, there is ongoing debate about whether these models apply systematic inference rules or merely reuse superficial patterns learned during pre-training. This paper aims to provide a deeper understanding of the low-level logical inference mechanisms in LMs by focusing on mechanistic interpretability.
Methodology
The main research objective is to discover and interpret the core mechanisms adopted by auto-regressive Language Models (LMs) when performing content-independent syllogistic reasoning. The methodology consists of three main stages:
- Syllogism Completion Task: A task designed to assess the model’s ability to predict valid conclusions from premises.
- Circuit Discovery Pipeline: Implemented on a syllogistic schema instantiated only with symbolic variables to identify the core sub-components responsible for content-independent reasoning.
- Generalization Investigation: Exploring how the identified circuit generalizes across different syllogistic schemes and model sizes.
Syllogism Completion Task
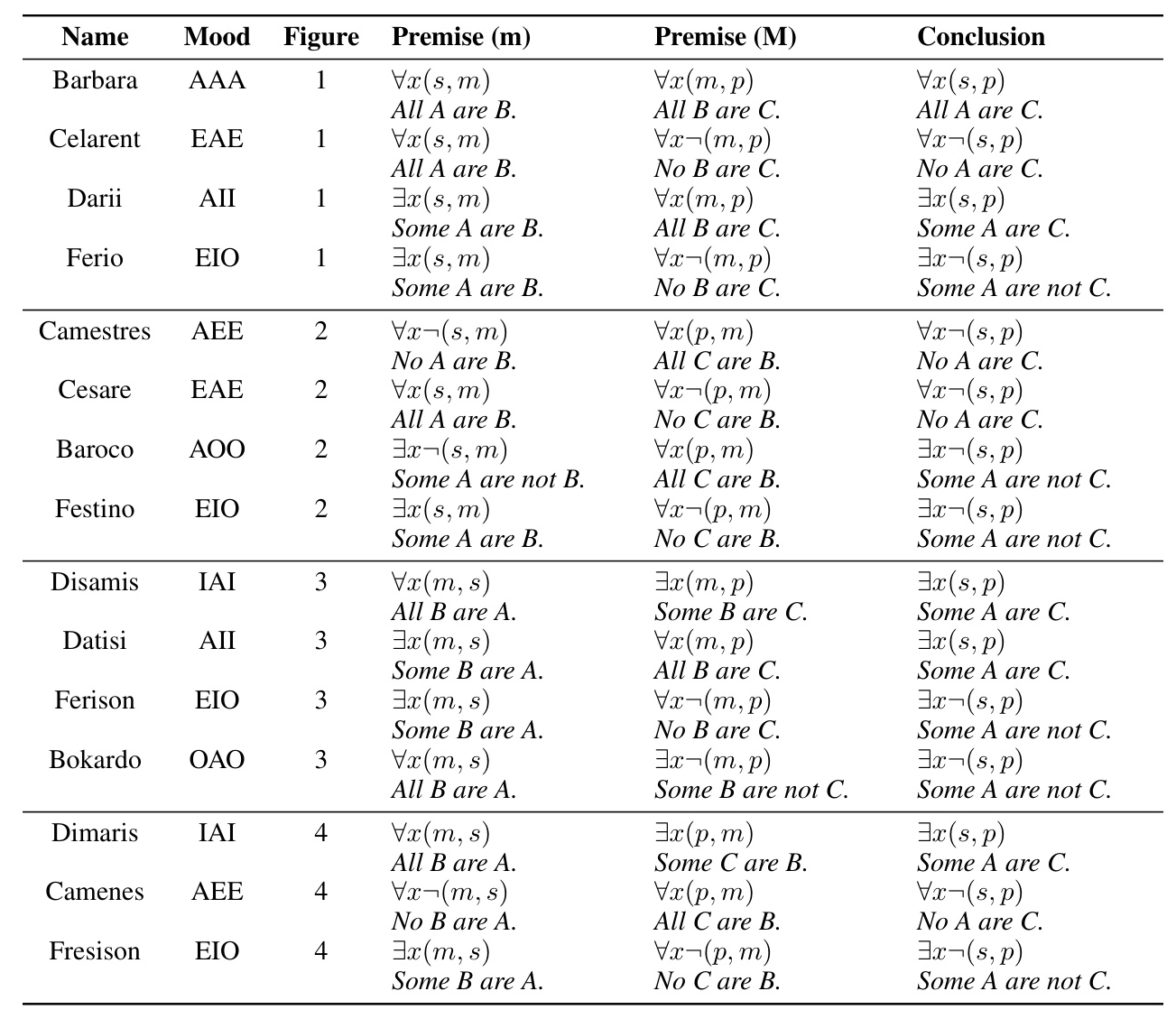
The syllogistic argument is typically composed of two premises (P1, P2) and a conclusion (C). To evaluate syllogistic reasoning in LMs, the completion task is formalized as masking language modeling, removing the final token from the conclusion and comparing the probability assigned by the LM to the correct token and the middle term.
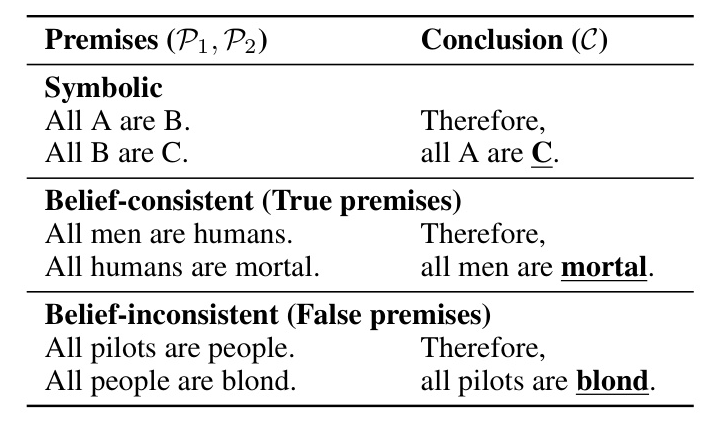
Circuit Discovery
The main objective is to find a circuit for syllogistic reasoning in a Language Model. A circuit can be defined as a subset of the original model that is both sufficient and necessary for achieving the original model performance on the syllogistic completion task. Activation Patching and circuit ablation methods are employed to identify and evaluate the circuit.
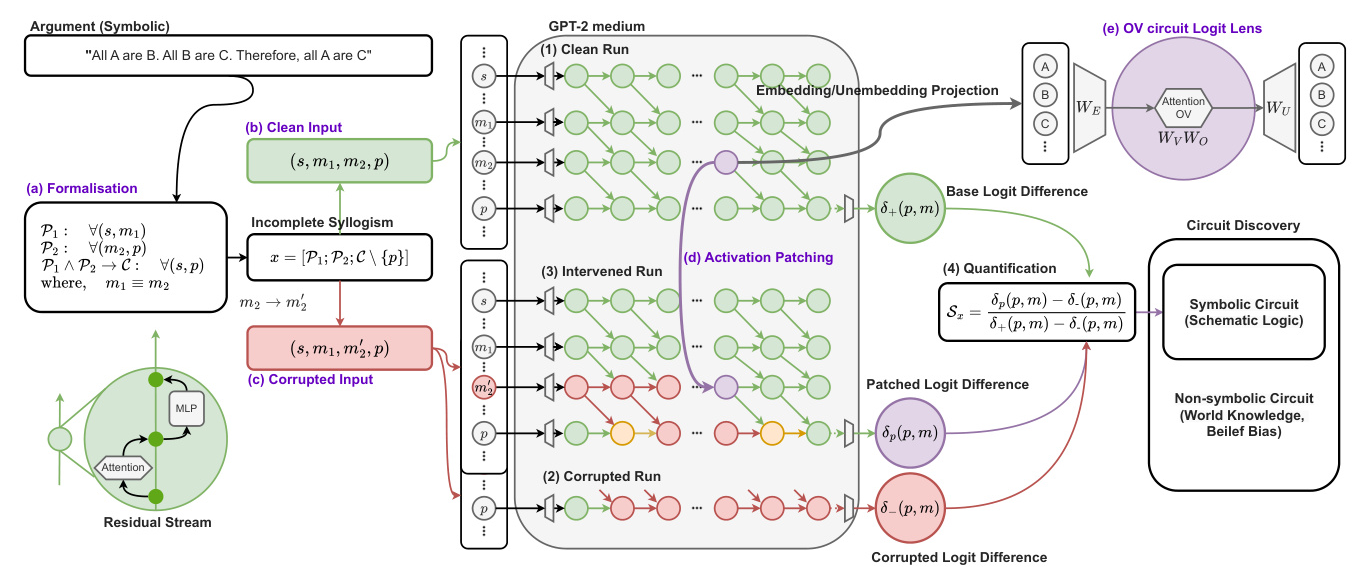
Interventions
Two distinct interventions are used to isolate the mechanisms related to the reasoning schema from the propagation of specific token information:
- Middle-Term Corruption: Replacing the second middle term with an unseen symbol to break the equality and corrupt the validity of the reasoning.
- All-Term Corruption: Replacing the original terms with different terms while keeping the completion answers unchanged to identify potential mover heads.
Empirical Evaluation
Model Selection
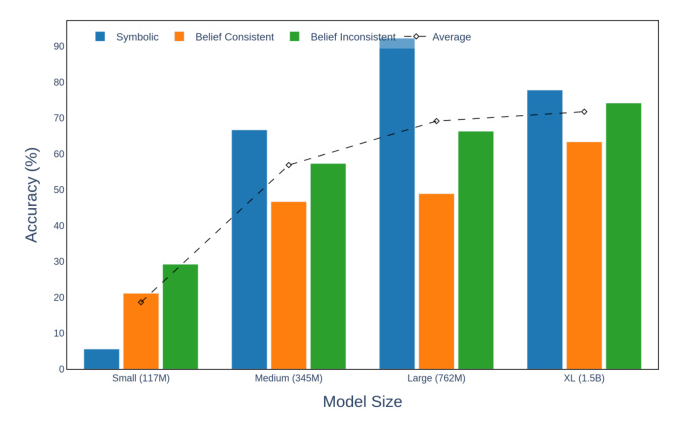
GPT-2 models of different sizes (117M, 345M, 762M, and 1.5B) are evaluated on the syllogism completion task to identify potential phase transition points where significant performance changes emerge. GPT-2 Medium is selected for circuit discovery based on a trade-off between model size and performance.
Localization of Transitive Reasoning Mechanisms
Middle-term corruption reveals information flow relevant to the transitive property. The results show that information from the middle term is conveyed to the conclusion position, with specific attention heads playing crucial roles in this mechanism.
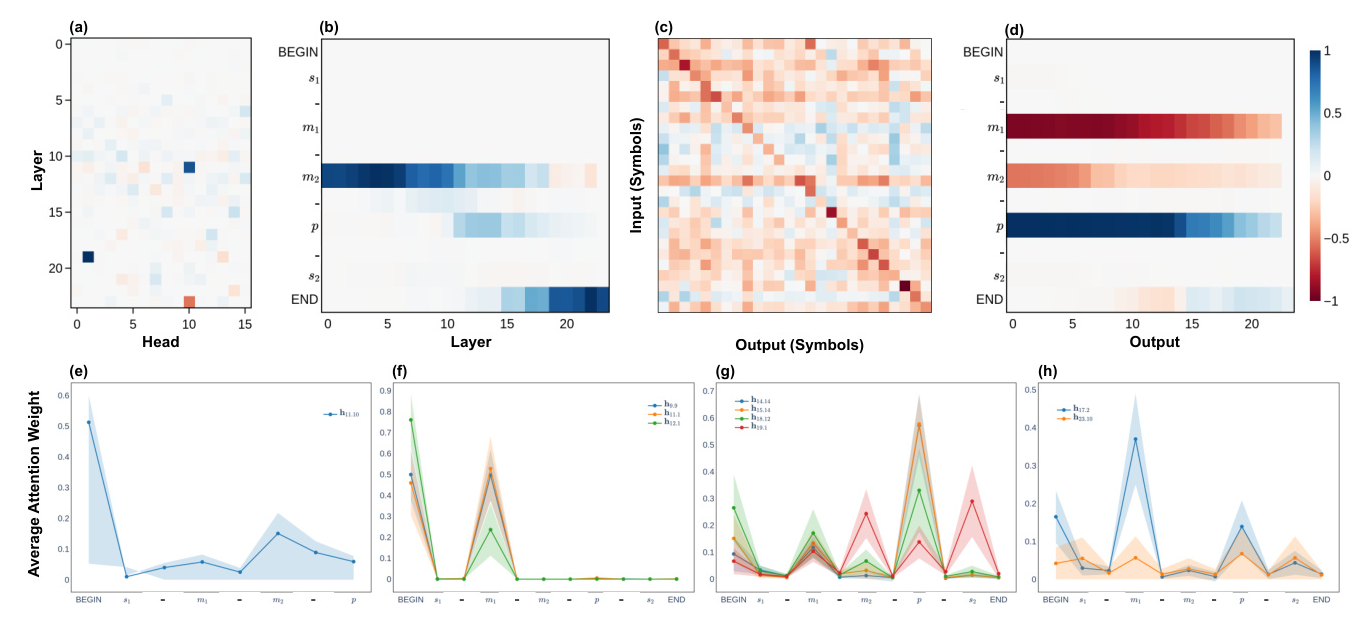
Localization of Term-Related Information Flow
Key information is moved from term-specific positions to the last position. The results indicate that the information residing in these positions contributes to their corresponding token prediction, with specific attention heads identified as mover heads.
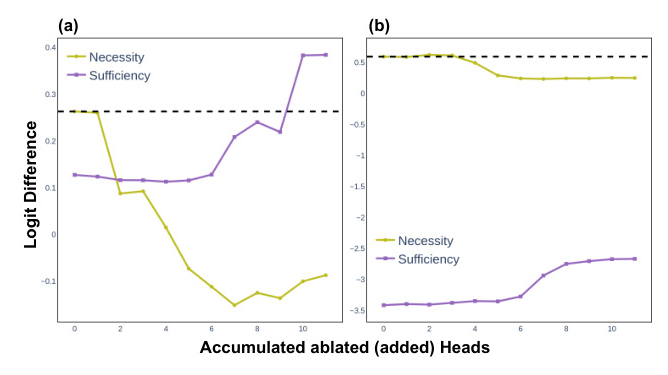
Circuit Evaluation
The correctness and robustness of the circuit are evaluated using ablation methods. The results demonstrate that the identified circuit is both necessary and sufficient, with performance degradation observed when removing circuit components and performance restoration when considering only the circuit’s subcomponents.
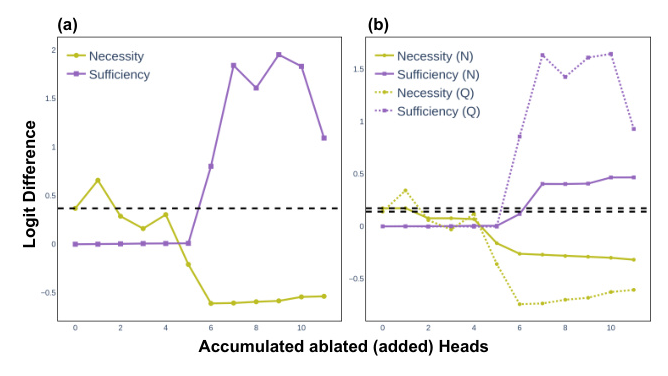
Circuit Transferability
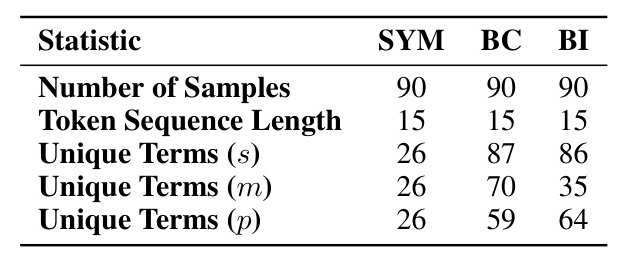
The circuit is evaluated on non-symbolic syllogistic arguments. The results show that the symbolic circuit is necessary for both belief-consistent and belief-inconsistent inputs, but only sufficient for belief-consistent data. This indicates that belief biases encoded in different attention heads may play an important role.
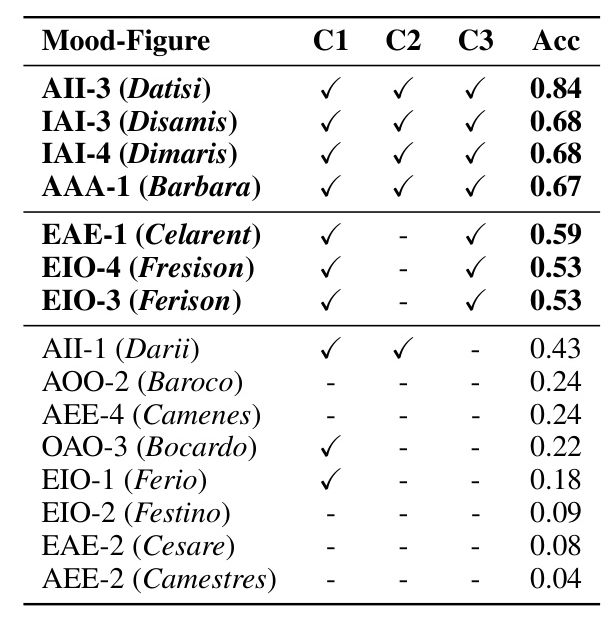
Generalization to Different Syllogistic Schemes
The experiment is extended to encompass all 15 unconditionally valid syllogisms. The results show that the circuit is sufficient and necessary for all the syllogistic schemes in which the model achieves high downstream accuracy (≥60%).
Generalization to Different Model Sizes
The analysis is expanded to different sizes of GPT-2 (small, large, and XL). The results show similar suppression mechanism patterns and information flow across all models, with increasing complexity in attention heads’ contributions as model size increases.
Conclusion
The study provides a comprehensive mechanistic interpretation of syllogistic reasoning within auto-regressive language models. The findings suggest that LMs learn transferable content-independent reasoning mechanisms, but these mechanisms might be contaminated and suppressed by specific world knowledge acquired during pre-training. Despite some limitations, the study offers valuable insights into the reasoning mechanisms adopted by auto-regressive language models and lays a solid foundation for future research in this field.