

Authors:
Zhongliang Guo、Lei Fang、Jingyu Lin、Yifei Qian、Shuai Zhao、Zeyu Wang、Junhao Dong、Cunjian Chen、Ognjen Arandjelović、Chun Pong Lau
Paper:
https://arxiv.org/abs/2408.10901
Introduction
The rapid advancements in generative artificial intelligence, particularly in image synthesis and manipulation, have brought about significant transformations in various industries. State-of-the-art methodologies, such as Latent Diffusion Models (LDMs), have demonstrated exceptional capabilities in producing photorealistic imagery. However, these advancements also pose ethical and security challenges, including data misappropriation and intellectual property infringement. The ease with which diffusion-based models can manipulate existing visual content presents a significant threat to the integrity of digital assets.
Adversarial attacks on machine learning models have emerged as a critical area of study, providing potential solutions to the misuse of generative AI. By introducing carefully crafted perturbations, it may be possible to impede the ability of diffusion models to edit or manipulate content effectively. Current protection techniques often rely heavily on extensive prior knowledge of the target models, which is impractical in real-world scenarios due to the rapid pace of technological advancement. This study proposes a novel method, the Posterior Collapse Attack (PCA), to address these challenges by targeting the Variational Autoencoders (VAEs) used in LDMs.
Related Work
Generation Models
Diffusion Probabilistic Models (DPMs) have achieved state-of-the-art results in density estimation and sample quality. However, they face challenges in inference speed and training costs, especially for high-resolution images. To address these limitations, researchers have developed approaches like Denoising Diffusion Implicit Models (DDIM) and explored two-stage processes. Latent Diffusion Models (LDMs) use autoencoding models to learn a perceptually similar space with lower computational complexity.
Adversarial Attack
The field of adversarial machine learning was catalyzed by the seminal work of Szegedy et al., uncovering the vulnerability of neural networks. Subsequent research has led to the development of various attack methodologies and defensive strategies. Adversarial attacks on VAEs have primarily focused on manipulating the input or latent space to affect reconstruction output. Recent research has also paid attention to adversarial attacks against diffusion models for image editing.
Research Methodology
Problem Definition
Adversarial attacks aim to craft imperceptible perturbations added to clean images, resulting in disruptive outputs from machine learning models. The key objectives of the adversarial attack against LDM-based image editing are:
- Minimize the perceptual distance between the adversarial sample and the clean image while introducing watermark artifacts.
- Maximize the perceptual distance between the adversarial sample and the clean image to disrupt the model’s output.
Existing methods often require extensive white-box information about the target model, limiting their transferability and applicability. Our method focuses on the second objective, exploiting the inherent characteristics of LDM-based editing by targeting the VAE component.
Posterior Collapse
Variational Autoencoders (VAEs) are a foundational component across different LDM implementations. The encoder of a VAE aims to approximate the intractable posterior distribution of the latent variable by a Gaussian distribution. The training process minimizes the KL divergence between the variational distribution and the prior distribution. However, VAEs often suffer from posterior collapse, where the KL divergence term dominates the overall loss, leading to uninformative posteriors. Our approach leverages this vulnerability to propose adversarial attacks that cause posterior collapse during the inference stage.
Posterior Collapse Loss Function
We aim to generate adversarial samples by minimizing the KL divergence between the variational distribution and a target distribution. The attack target is set to a zero mean Gaussian distribution, making it a more general attack method. Successful attacks should make the encoded posterior uninformative, disrupting the downstream image generation process. We use projected sign gradient ascent for iterative updates to craft adversarial samples.
Experimental Design
Dataset
We utilized a 1000-image subset of the ImageNet dataset, resized to 512 × 512, ensuring consistency across evaluations.
Baselines
We compared our approach against several state-of-the-art methods, including AdvDM, PhotoGuard, MIST, and SDS. Our method was implemented with specific hyperparameters and optimization settings.
Victim Models
Our experiments focused on popular LDMs, specifically Stable Diffusion 1.4 (SD14) and 1.5 (SD15). We also tested the transferability across different resolutions and architectures, including Stable Diffusion 2.0 (SD20) and Stable Diffusion XL (SDXL).
Varied Prompts
To evaluate the robustness and versatility of our method, we conducted inference using a diverse set of prompts, including empty prompts, BLIP-generated captions, weather modifications, lighting adjustments, and style transfers.
Image Quality Assessment (IQA)
We employed five different IQAs to quantitatively assess the quality of the edited images pre- and post-attack: Peak Signal-to-Noise Ratio (PSNR), Fréchet Inception Distance (FID), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Aesthetic Color Distance Metric (ACDM).
Against Defending Methods
We evaluated our attack’s robustness against potential defenses, including Adv-Clean and 3 × 3 Gaussian blur, to simulate potential degradation of protected images during distribution.
Results and Analysis
Image Editing Results with Varied Prompts
Our experimental results demonstrate the superior performance of our proposed PCA compared to existing methods. Our method significantly disrupts image editing, causing substantial semantic loss and introducing noise patterns that degrade the quality of the generated images. The quantitative results further corroborate the effectiveness of our method, achieving state-of-the-art results while requiring minimal knowledge of the opponent model and less computational resources.

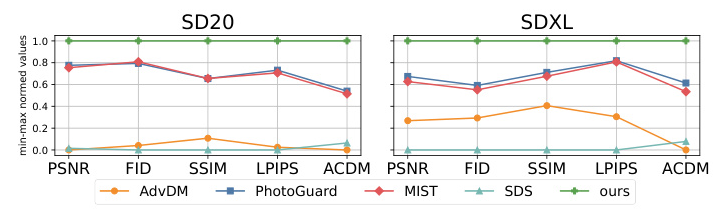
Transferability
Our method demonstrates superior transferability compared to existing approaches when tested on both SD20 and SDXL models. It consistently achieves the highest normalized scores across all IQA metrics, indicating the best attack performance. This generalizability is crucial in addressing the challenges posed by rapidly evolving generative AI models.
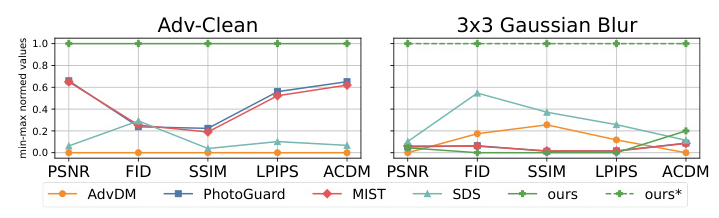
Against Defense
Our method shows robust performance against the Adv-Clean defense and comparable performance against 3 × 3 Gaussian blur. The adaptive version of our method achieves superior performance across all metrics, highlighting its flexibility and robustness in overcoming diverse defense mechanisms.
Overall Conclusion
In this paper, we proposed the Posterior Collapse Attack, a novel method for disrupting LDM-based image editing. Our method leverages a novel loss function targeting the VAE encoder of LDMs, inducing collapse in the VAE’s posterior distribution to significantly disrupt the image semantics during LDM editing. Experimental results demonstrate that PCA significantly degrades the quality of LDM-edited images, causing a collapse in their semantic content. This approach proves highly effective in protecting images from unauthorized manipulation across various LDM architectures, contributing to the ongoing efforts to secure digital assets in an era of rapidly advancing generative AI.
