

Authors:
Vladislav Li、Georgios Tsoumplekas、Ilias Siniosoglou、Vasileios Argyriou、Anastasios Lytos、Eleftherios Fountoukidis、Panagiotis Sarigiannidis
Paper:
https://arxiv.org/abs/2408.10940
Introduction
In the rapidly evolving landscape of Artificial Intelligence (AI), the ability to train models efficiently and effectively is paramount. This is especially true in domains where data scarcity is a significant challenge, such as the industrial and healthcare sectors. Traditional AI models often require extensive datasets and computational resources, which can be both costly and energy-intensive. To address these challenges, low-shot learning (LSL) and few-shot learning (FSL) have emerged as promising solutions. These approaches leverage prior knowledge to generalize from a small amount of labeled data, significantly reducing the need for large datasets and extensive computational resources.
This paper delves into the efficacy of various data augmentation (DA) strategies when combined with finetuning-based low/few-shot object detection. The study aims to evaluate both the performance and energy efficiency of these strategies, providing insights into their effectiveness in data-scarce environments.
Related Work
Low/Few-Shot Object Detection
Low/few-shot object detection techniques can be broadly categorized into meta-learning and finetuning-based approaches. Meta-learning involves creating low/few-shot tasks during training and learning how to transfer knowledge to novel tasks. Examples include Meta Faster R-CNN and Meta-DETR. Finetuning-based approaches, on the other hand, involve pretraining on a base dataset with abundant data and then finetuning on low/few-shot tasks. Techniques such as finetuning only the final classification layer, contrastive learning, and gradient scaling and stopping are commonly used.
Energy Efficient Object Detection
Green AI focuses on developing energy-efficient models to address the carbon footprint concerns of modern deep learning approaches. In computer vision, various methods have been proposed to optimize model performance and energy efficiency. However, limited attention has been given to the energy efficiency of LSL/FSL for object detection, with few studies evaluating the efficiency of finetuning-based approaches.
Data Augmentation
Data augmentation techniques for deep learning, particularly in computer vision, have been extensively researched. These techniques can be broadly categorized into image manipulation, image erasing, and image mixing. More recently, automated DA selection methods have emerged, using reinforcement learning, random selection, or consistency enforcement between original and augmented images. However, the energy efficiency of these techniques, especially in the context of LSL and FSL, remains underexplored.
Research Methodology
Problem Formulation
The goal of few-shot object detection (FSOD) and low-shot object detection (LSOD) is to develop object detectors capable of rapidly adapting to novel tasks with only a few training images. The standard formulation involves training an object detector on a base dataset with abundant data and then adapting it to a novel dataset with limited data. The base dataset contains images and corresponding labels and bounding box annotations, while the novel dataset contains a small number of labeled bounding boxes for each class.
Real-Time Detection with YOLO
The study utilizes the YOLOv8 architecture, a widely used real-time object detector known for its balance between efficiency and accuracy. YOLOv8 consists of a backbone feature extractor and a prediction head, enabling multi-scaled object detection. This architecture is particularly effective for real-time object detection tasks.
Data Augmentation Strategies
The study examines two main lines of work: custom DA strategies and automated DA selection strategies. Custom DA strategies involve applying specific transformations to the data to increase dataset size and diversity. Automated DA selection methods, such as AutoAugment, RandAugment, and AugMix, use search algorithms to select optimal DA operations.
Experimental Design
Datasets
Three datasets containing images of objects and hazards commonly found in industrial settings are used to assess the examined DA techniques. The datasets are summarized in Table I. The training set images are used to create low/few-shot training tasks, and model performance is evaluated on the validation and test sets.
Model Settings
The YOLOv8n variant, pretrained on the MS COCO dataset, is used as the initial model. The model contains approximately 3.2M parameters, with only the detection modules’ parameters finetuned. The model is finetuned for 1000 epochs using Early Stopping with patience set to 100 epochs. Various DA strategies are implemented using the Albumentations library.
Evaluation Metrics
Model performance is evaluated using AP50, representing the model’s Average Precision with a fixed Intersection over Union (IoU) threshold of 50%. Energy efficiency is assessed using the CodeCarbon library, and the Efficiency Factor (EF) metric is used to consider both performance and energy efficiency.
Results and Analysis
Few-Shot Learning Results
Main Results
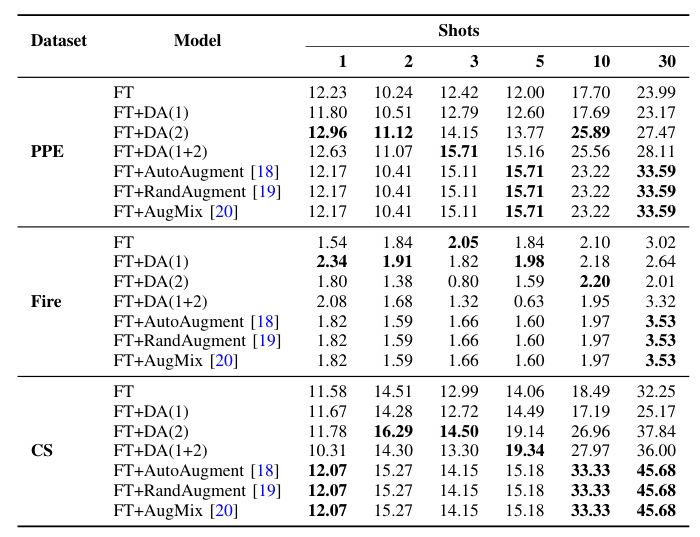
Table II shows the model performance of different DA strategies for varying shots. Increasing the number of shots generally leads to improved performance. Automated DA selection methods demonstrate similar performance, possibly due to the limited DA pool. For the PPE dataset, automated DA selection methods lead to improved results compared to custom DAs and finetuning without DA. Similar conclusions can be drawn for the CS dataset. In the Fire dataset, custom DA methods produce strong results for a small number of shots, but automated DA selection methods lead to the best results in the 30-shot scenario.
Energy Consumption
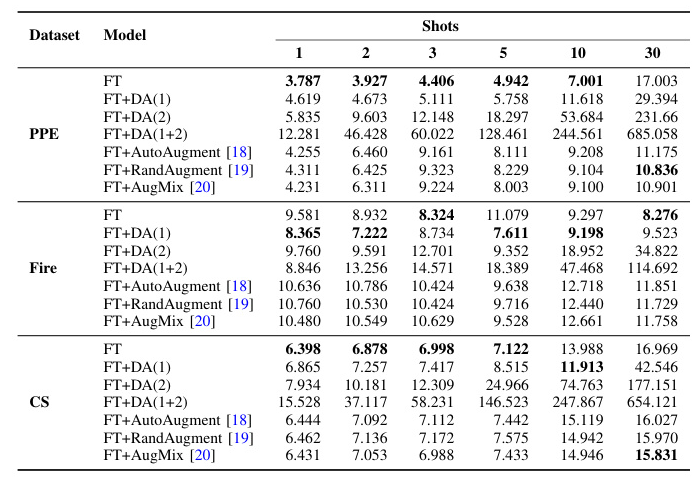
Table III includes the energy consumed by each model during finetuning. Increasing the number of shots generally leads to increased energy consumption. However, this relationship is unclear in the Fire dataset, possibly due to the small number of samples. Including DA methods in the finetuning process generally leads to increased energy consumption, but automated DA selection approaches can be beneficial in certain scenarios.
Efficiency Factor
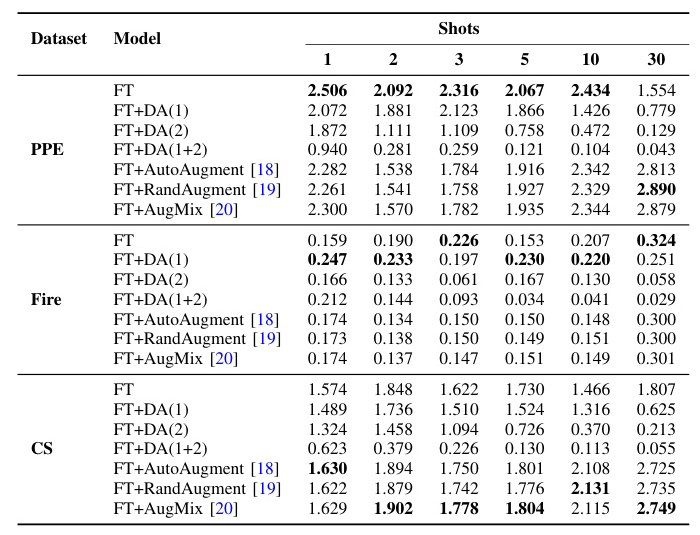
Table IV displays the EF metric values for different DA strategies. Generally, EF improves with higher AP50 values and lower energy consumption. For the PPE dataset, FT achieves the best EF values due to its low energy consumption. In the Fire dataset, FT+DA(1) performs particularly well. In the CS dataset, automated DA selection methods achieve the best EF values due to their significant performance boost in AP50.
Effect of Custom Augmentations
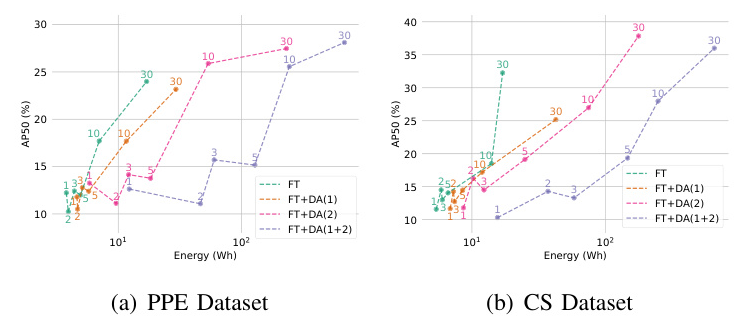
Fig. 1 illustrates model performance in terms of AP50 with respect to energy consumption for different DA strategies. FT leads to the most optimal performance vs. energy efficiency trade-off, followed by FT+DA(1), FT+DA(2), and FT+DA(1+2).
Effect of Automated Augmentations
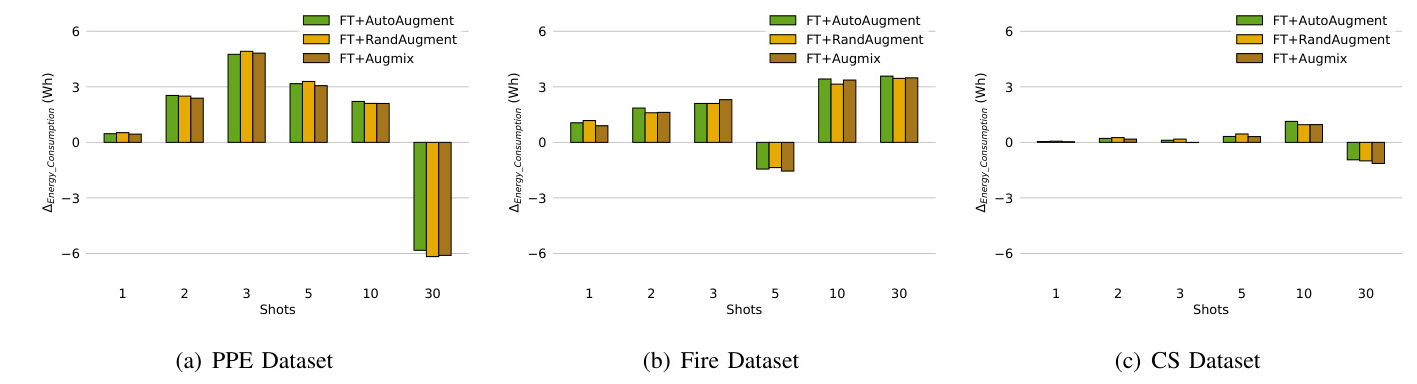
Fig. 2 illustrates the energy consumption difference between automated DA selection techniques and vanilla FT. Automated DA selection methods generally result in increased energy consumption compared to FT, except in certain scenarios where finetuning converges faster.
Finetuning with and without DAs
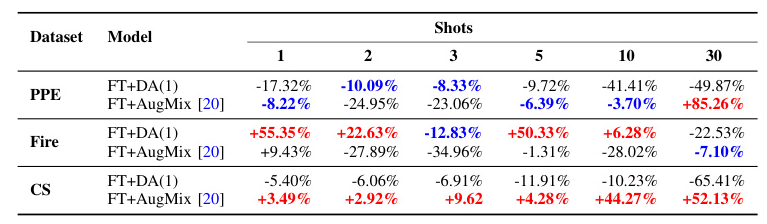
Table V compares the performance of the best custom and automated DA approaches to vanilla FT in terms of the EF metric. In the PPE dataset, DA approaches generally lead to worse EF performance, except FT+AugMix in the 30-shot scenario. In the Fire dataset, FT+DA(1) leads to a significant boost for a small number of shots. In the CS dataset, FT+AugMix shows clear benefits.
Low-Shot Learning Results
Main Results
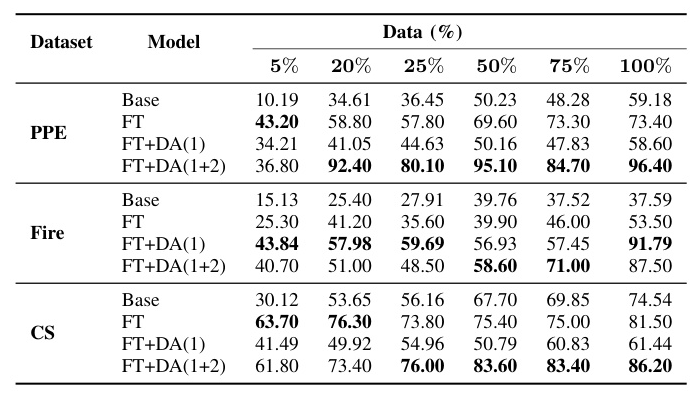
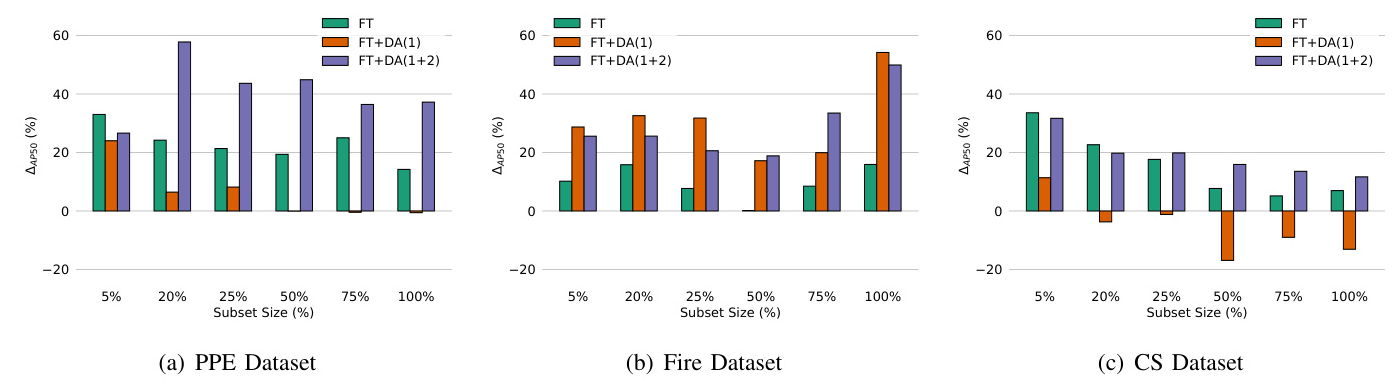
Table VI includes the model performance of the examined methods under varying sizes of the training set. In the PPE and CS datasets, vanilla FT leads to the best performance when the percentage of utilized data is small. In the Fire dataset, custom DA approaches lead to improved results regardless of the training set size.
Energy Consumption
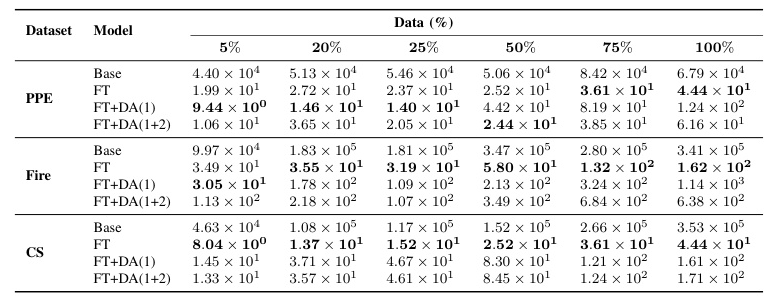
Table VII contains the energy consumption during finetuning. Training a model from scratch is highly inefficient compared to finetuning. Vanilla FT demonstrates the lowest energy consumption, especially as the number of available training data increases.
Efficiency Factor
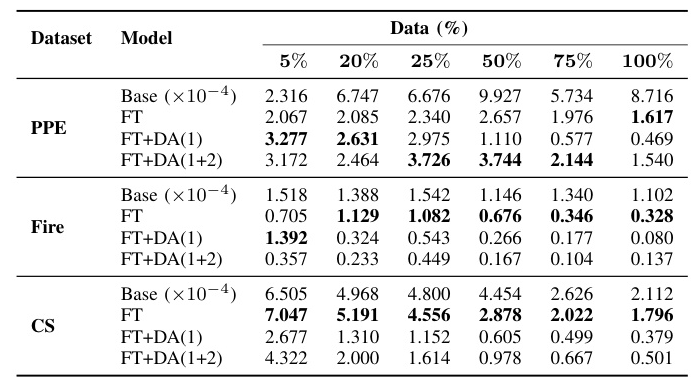
Table VIII displays the EF metric values for different training strategies. While using DAs can enhance model performance, vanilla FT yields the best results when considering both performance and energy efficiency.
Performance vs Efficiency Trade-offs
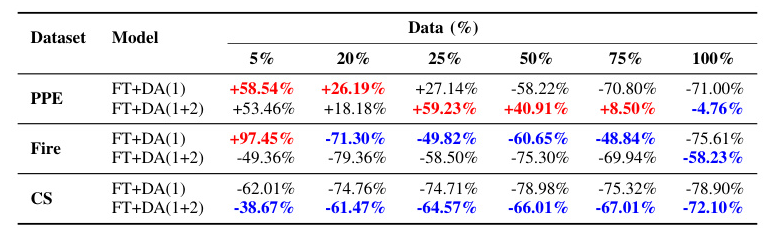
Table IX includes the percent change of the EF metric values between the best custom DA approaches and vanilla FT. Utilizing DA methods is optimal only in the PPE dataset. In the Fire and CS datasets, using DAs generally leads to worse results compared to FT.
Overall Conclusion
This study provides a comprehensive empirical analysis of data augmentation strategies for finetuning-based low/few-shot object detection. While data augmentations can improve model performance, the additional energy consumption often outweighs the performance gains. The novel Efficiency Factor metric highlights that the effectiveness of data augmentations highly depends on the dataset and may not always lead to improved results. Future research should focus on designing augmentation strategies that enhance both model performance and energy efficiency in data-scarce settings and other application domains with similar requirements.