Authors:
Bei Ouyang、Shengyuan Ye、Liekang Zeng、Tianyi Qian、Jingyi Li、Xu Chen
Paper:
https://arxiv.org/abs/2408.10746
Introduction
Background
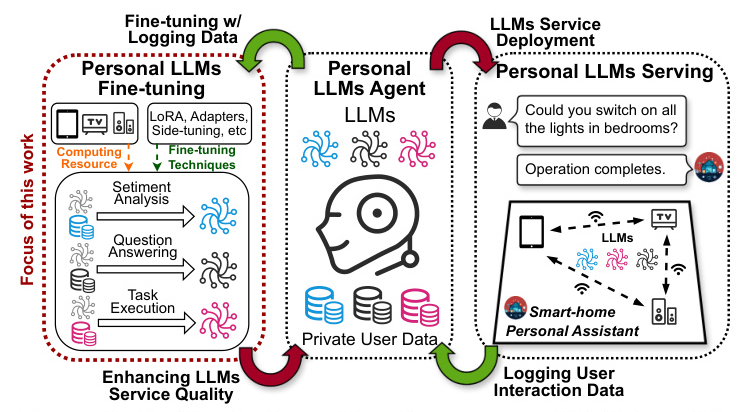
Large Language Models (LLMs) have revolutionized machine intelligence, enabling a wide range of applications, especially at the network edge. Intelligent personal assistants (IPAs) are a prime example, providing users with high-performance, privacy-preserving intelligent services. However, the fine-tuning of these models on edge devices presents significant challenges due to their computational and memory-intensive nature.
Problem Statement
While parameter-efficient fine-tuning (PEFT) techniques like Adapters and LoRA have been developed to mitigate resource constraints, they are not sufficiently resource-efficient for edge devices. Additionally, resource management optimization techniques are bottlenecked by the resource limitations of individual devices. To address these challenges, the paper proposes Pluto and Charon (PAC), a collaborative edge AI framework designed to efficiently fine-tune personal LLMs by leveraging multiple edge devices.
Related Work
Parameter-Efficient Fine-Tuning
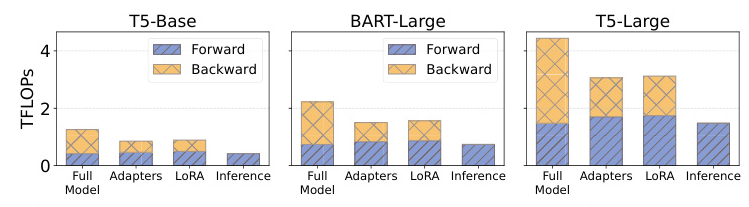
PEFT techniques such as Adapters and LoRA aim to reduce the number of trainable parameters, thereby lowering the computational and memory requirements. However, these techniques still require full backward passes through the LLM backbone, limiting their efficiency on resource-constrained edge devices.
On-Device Fine-Tuning
On-device fine-tuning preserves user data privacy by leveraging idle resources at the edge. However, the computational and memory limitations of edge devices pose significant challenges. Techniques like CPU-DSP co-execution and memory budget adaptation have been explored, but they are still constrained by the resource limitations of single devices.
Collaborative Edge Computing
Collaborative edge computing leverages multiple edge devices to overcome individual resource limitations. Techniques like federated learning and pipeline parallelism have been explored, but they primarily focus on LLM inference rather than fine-tuning.
Research Methodology
Algorithmic Design
PAC employs a sophisticated algorithm-system co-design to break the resource wall of personal LLMs fine-tuning. The key components are:
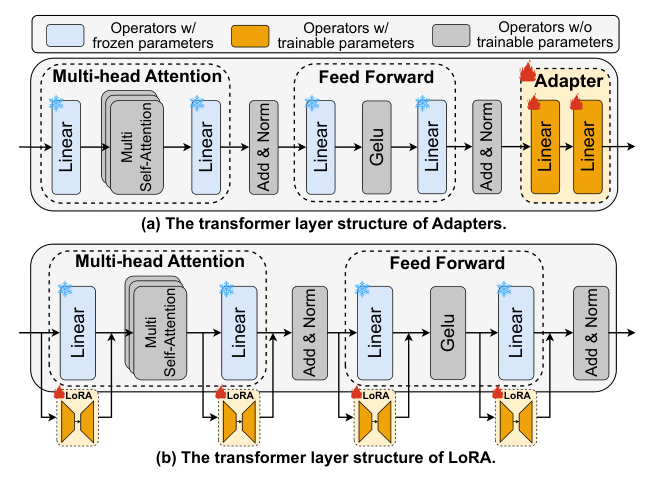
- Parallel Adapters: These adapters provide a dedicated gradient “highway” for trainable parameters, eliminating the need for full backward passes through the LLM backbone.
- Activation Cache: This mechanism caches intermediate activations, allowing for their reuse across multiple epochs, thereby reducing the need for repeated forward passes.
System Design
PAC leverages edge devices in close proximity, pooling them as a collective resource for in-situ personal LLMs fine-tuning. The framework employs a hybrid data and pipeline parallelism approach to orchestrate distributed training, further enhancing resource efficiency.
Experimental Design
Prototype Implementation
PAC was implemented in a realistic testbed with a cluster of edge devices. The framework was evaluated using three LLMs (T5-Base, BART-Large, and T5-Large) and four tasks from the GLUE benchmark (SST-2, MRPC, STS-B, and QNLI).
Baseline Methods
The performance of PAC was compared against several baseline methods, including standalone fine-tuning on a single device, Eco-FL (pipeline parallelism), and EDDL (data parallelism). These baseline methods were enhanced with prevalent PEFT techniques like Adapters and LoRA for a fair comparison.
Results and Analysis
End-to-End Performance
PAC significantly outperformed the baseline methods, achieving up to 8.64× end-to-end speedup and up to 88.16% reduction in memory footprint. The framework demonstrated comparable or superior performance to full model fine-tuning and PEFT techniques across various models and datasets.
Time and Memory Efficiency
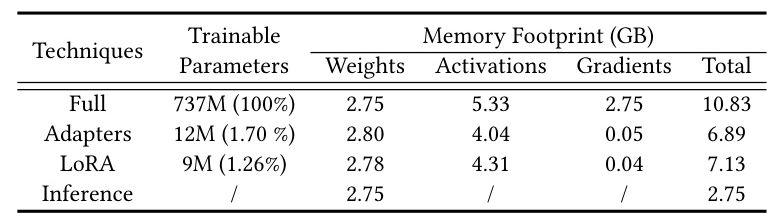
Parallel Adapters markedly reduced the average sample training time and memory usage compared to baseline methods. The activation cache mechanism further decreased the training time by up to 96.39% and reduced the peak memory footprint by up to 88.16%.
Scalability
PAC’s hybrid parallelism provided enhanced scalability and robustness across varying numbers of devices and workloads. The framework’s planning algorithm identified efficient parallel configurations, maximizing throughput within the constraints of available resources.
Overall Conclusion
PAC presents a time and memory-efficient collaborative edge AI framework for personal LLMs fine-tuning. By leveraging a sophisticated algorithm-system co-design, PAC breaks the resource wall of personal LLMs fine-tuning, achieving significant improvements in training speed and memory efficiency. The framework’s extensive evaluation demonstrates its potential to enable efficient and privacy-preserving fine-tuning of LLMs on resource-constrained edge devices.