

Authors:
Yonggan Wu、Ling-Chao Meng、Yuan Zichao、Sixian Chan、Hong-Qiang Wang
Paper:
https://arxiv.org/abs/2408.10624
Introduction
Person re-identification (ReID) is a critical task in surveillance systems, aiming to match images of individuals captured by different cameras. Traditional visible-light person ReID methods have achieved significant success, but they struggle under poor lighting conditions. To address this, infrared cameras are increasingly used, leading to the development of visible-infrared person re-identification (VI-ReID). VI-ReID is challenging due to the significant modality discrepancies between visible and infrared images. Existing methods often fail to fully mine modality-invariant information, focusing on either spatial or channel dimensions but not both. This study introduces the Wide-Ranging Information Mining Network (WRIM-Net) to address these challenges by comprehensively mining modality-invariant information across multiple dimensions and modalities.
Related Work
Visible-Infrared Person Re-Identification
VI-ReID methods can be broadly categorized into image-level and feature-level approaches. Image-level methods fuse modalities at the data level to reduce modality discrepancies, but they often suffer from noise due to the lack of high-quality image pairs. Feature-level methods map visible and infrared features into a common space but struggle to capture sufficient modality-invariant information. Dual-stream network architectures are commonly used, separating parameters in shallow layers for specific-modality information and sharing them in deep layers for shared-modality information. However, these methods often neglect multi-dimension information interaction.
Attention Mechanisms
Attention mechanisms have been widely used in visual tasks to enhance neural network performance by improving visual representation. In person ReID, attention mechanisms have been employed to capture long-range spatial relationships and potent features. However, most methods apply attention mechanisms only in deep layers, neglecting specific-modality multi-dimension information mining. The proposed MIIM module addresses this by achieving non-local spatial and channel interactions through spatial compression and Global Region Interaction (GRI).
Contrastive Learning
Contrastive learning is crucial in self-supervised learning, allowing neural networks to extract invariant features efficiently. It has been used for modality alignment in image-text multi-modalities learning and unsupervised VI-ReID tasks. Unlike previous methods, the proposed Cross-Modality Key-Instance Contrastive (CMKIC) loss selects top-K least similar samples with the same ID but different modalities as positive samples, increasing task difficulty and enabling the network to mine modality-invariant information more effectively.
Research Methodology
Multi-dimension Interactive Information Mining Module
The MIIM module enhances information extraction by employing global spatial interactions and establishing long-range dependencies to capture non-local spatial-related information, such as shape and pose. It also employs channel interactions to capture channel-related information, such as texture. The MIIM module comprises three components: Spatial-Channel Compression (SCC), Global Region Interaction (GRI), and Spatial-Channel Restore (SCR). The input features pass through a Batch Normalization (BN) layer, followed by SCC, which compresses the features to reduce computational complexity. The compressed features are then processed by the GRI component, which employs Multi-Head Attention (MHA) to achieve global spatial interaction. Finally, the features are restored to their original size through the SCR component.
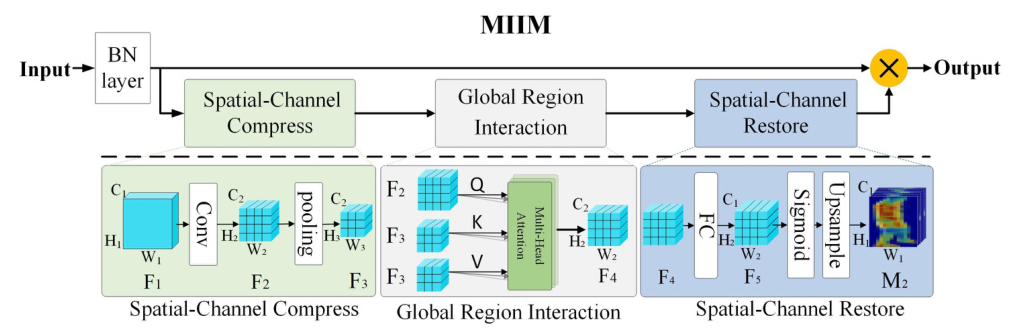
Auxiliary-Information-based Contrastive Learning Approach
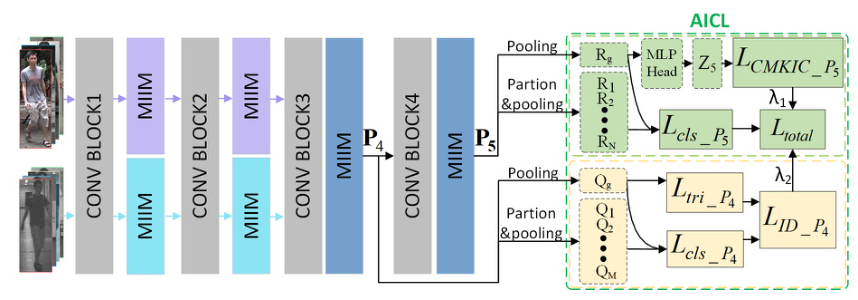
The AICL approach employs the CMKIC loss to guide the network in learning modality-invariant features. The CMKIC loss selects top-K least similar samples with the same ID but different modalities as positive samples, facilitating the network’s exploration of crucial modality-invariant information. The AICL approach also leverages auxiliary information from additional layers to enhance the mining of modality-invariant information. The total loss during training is a weighted sum of the CMKIC loss, cross-entropy classification loss, and ID loss.
Experimental Design
Datasets and Evaluation Setting
The experiments were conducted on three benchmark datasets: SYSU-MM01, RegDB, and LLCM. SYSU-MM01 comprises 491 identities captured by four visible and two infrared cameras. RegDB consists of 412 pedestrians, each with 10 visible and 10 infrared images. LLCM is the latest VI-ReID benchmark, comprising 30,921 images from 713 unique identities. The evaluation metrics used were Rank-1 accuracy and mean average precision (mAP).
Implementation Details
The pre-trained ResNet50 was chosen as the backbone, with BNNeck used in the classification head. The features of the last layer were split according to the ideas of PCB and MGN. The image size was resized to 384 × 144. The MIIM module was placed after Block1 and Block2 for specific-modality information mining and after Block3 and Block4 for shared-modality information mining.
Results and Analysis
Comparison with State-of-the-Art Methods
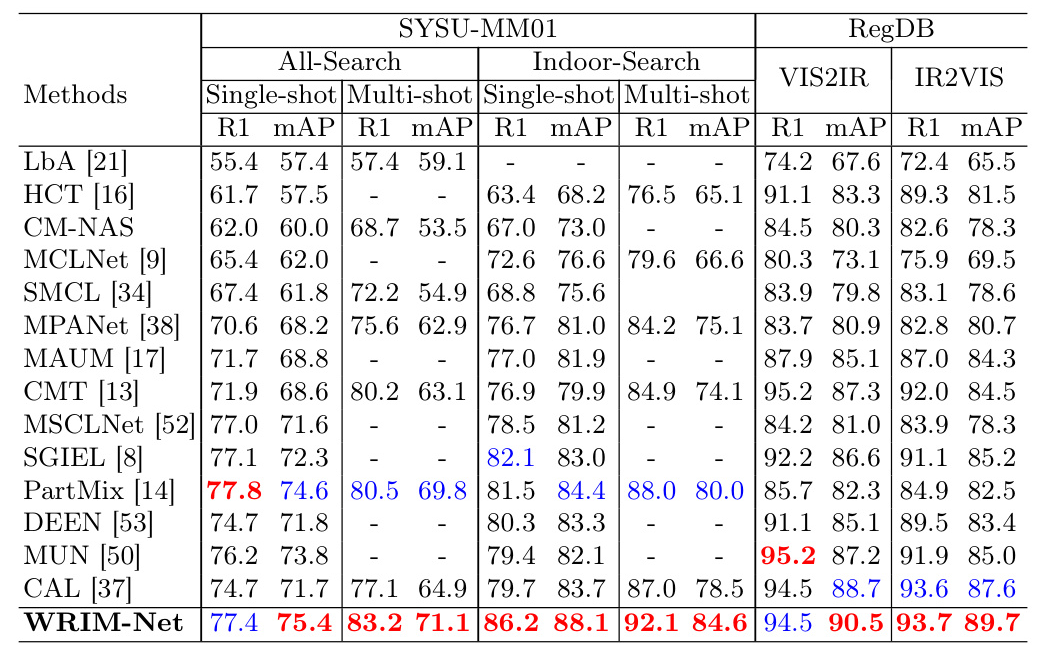
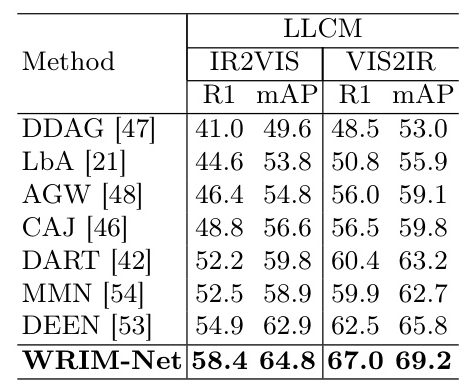
WRIM-Net outperformed state-of-the-art methods on SYSU-MM01, RegDB, and LLCM datasets. On SYSU-MM01, WRIM-Net achieved substantial improvement in the Indoor-Search scenario and Multi-shot mode. On LLCM, WRIM-Net consistently outperformed previous methods, with all metrics significantly exceeding them.
Ablation Study
The ablation study demonstrated the effectiveness of the MIIM module and AICL approach. Introducing MIIM alone resulted in a significant increase in Rank-1 and mAP, indicating its effectiveness in mining modality-invariant information. The inclusion of AICL further improved the model’s capabilities. The study also highlighted the importance of placing MIIM in shallower layers for specific-modality information mining.
Parameters Analysis
The analysis of spatial and channel compression ratios revealed that the optimal performance was attained with specific configurations. Excessively high compression ratios led to the loss of critical information, while excessively low ratios impeded effective information interaction. The optimal ks parameter in SCC was found to be 3, enhancing network performance while maintaining low complexity. The top-K value in CMKIC loss was optimally set to 4, significantly improving Rank-1 and mAP.
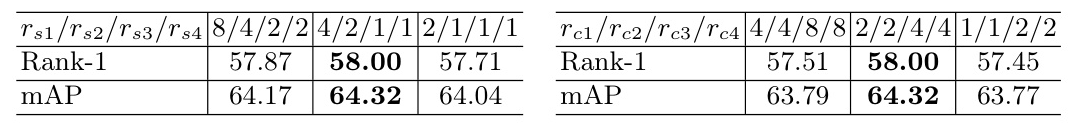
Visualization Analysis
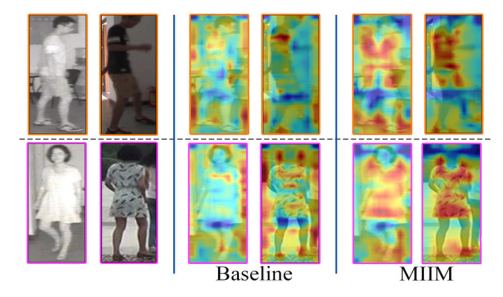
Grad-Cam visualizations showed that the MIIM module enabled the network to focus on pedestrians themselves, paying more attention to global information. T-SNE visualizations demonstrated that AICL effectively alleviated modality discrepancies and improved feature discriminability.
Overall Conclusion
WRIM-Net is a novel approach for VI-ReID, emphasizing modality-invariant information mining across a wide range. The MIIM module effectively extracts specific-modality and shared-modality features through multi-dimension interactions, while the AICL approach guides the network to explore modality-invariant information using CMKIC loss. Extensive experiments on three benchmark datasets demonstrated the superiority of WRIM-Net, achieving the best performance on almost all metrics. This study provides a significant advancement in the field of VI-ReID, addressing the challenges of modality discrepancies and enhancing the robustness of person re-identification systems.