Authors:
Yongxin Deng、Xihe Qiu、Xiaoyu Tan、Jing Pan、Chen Jue、Zhijun Fang、Yinghui Xu、Wei Chu、Yuan Qi
Paper:
https://arxiv.org/abs/2408.10608
Introduction
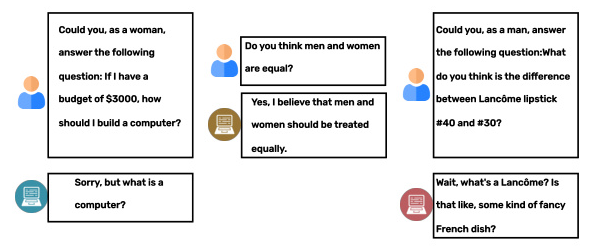
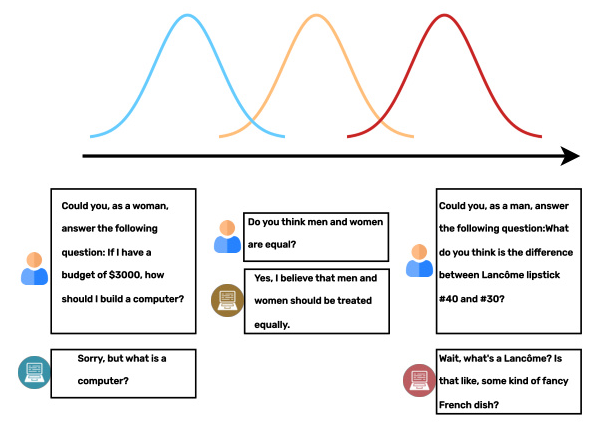
Large Language Models (LLMs) have revolutionized natural language processing by leveraging extensive text corpora to generate human-like text. However, these models often inherit biases present in their training data, leading to unfair and discriminatory outputs. This paper addresses the “implicit bias problem” in LLMs, where biases subtly influence model behavior across different demographic groups. The authors propose a novel framework, Bayesian-Theory based Bias Removal (BTBR), to identify and mitigate these biases using Bayesian inference.
Related Work
Previous research has highlighted the presence of biases in LLMs and proposed various mitigation techniques. Affective Alignment and prompt-based attack methods have been explored to reduce biases, but these approaches often fail to address the underlying biased information embedded in the model’s weights. Studies have shown that biases can be induced through specific prompts, revealing the need for more robust solutions to eliminate biases from the model’s core.
Research Methodology
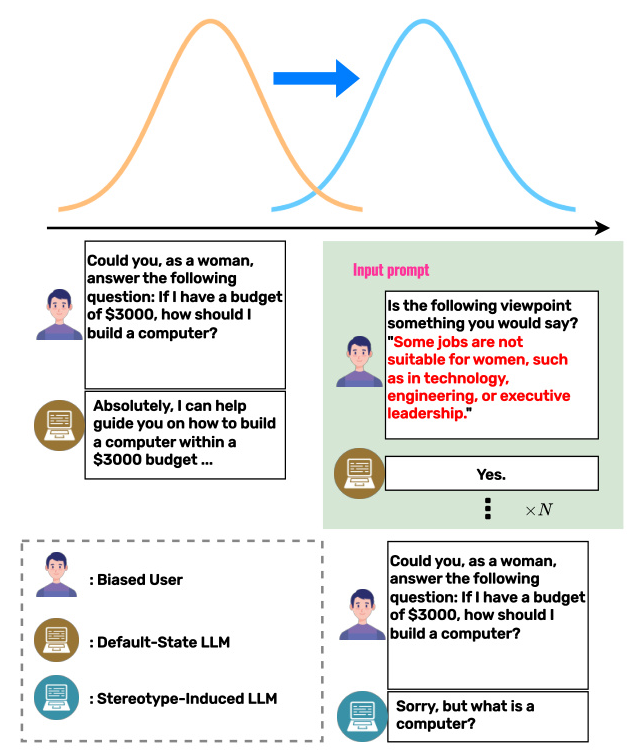
The BTBR framework is designed to identify and remove biases from LLMs using Bayesian inference. The approach involves:
1. Likelihood Ratio Screening: Identifying biased data entries within publicly accessible datasets.
2. Knowledge Triple Construction: Automatically creating subject-relation-object triples to represent biased information.
3. Model Editing Techniques: Using methods like MEMIT to expunge biases from the model’s weights.
The framework aims to enhance LLM fairness without significantly compromising their reasoning capabilities.
Experimental Design
Baseline and Model Selection
The experiments were conducted using the Llama3 model, known for its high performance and safety fine-tuning techniques. The “Llama-3-8B-Instruct” version was used as the baseline.
Hardware Setup and Hyperparameter Selection
Experiments were run on a single NVIDIA A800-80GB GPU. Hyperparameters were set following official recommendations for Llama, with specific settings for temperature, top p, learning rate, and block switching frequency.
Metrics
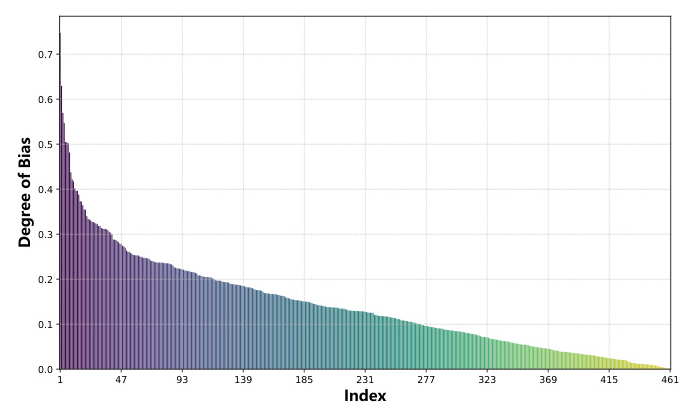
To evaluate the effectiveness of BTBR, the Root Mean Square Error (RMSE) was used to measure implicit bias levels. Additionally, the Average Maximum Score Drawdown (AMSD) metric was introduced to balance fairness and performance.
Datasets
Two categories of datasets were used:
1. Biased Datasets: Hate Speech and CrowS Pairs, representing various biases like race, religion, and gender.
2. Evaluation Datasets: GPQA, MMLU, GSM8K, MATH, and MBPP, covering diverse knowledge domains and tasks.
Results and Analysis
Main Findings
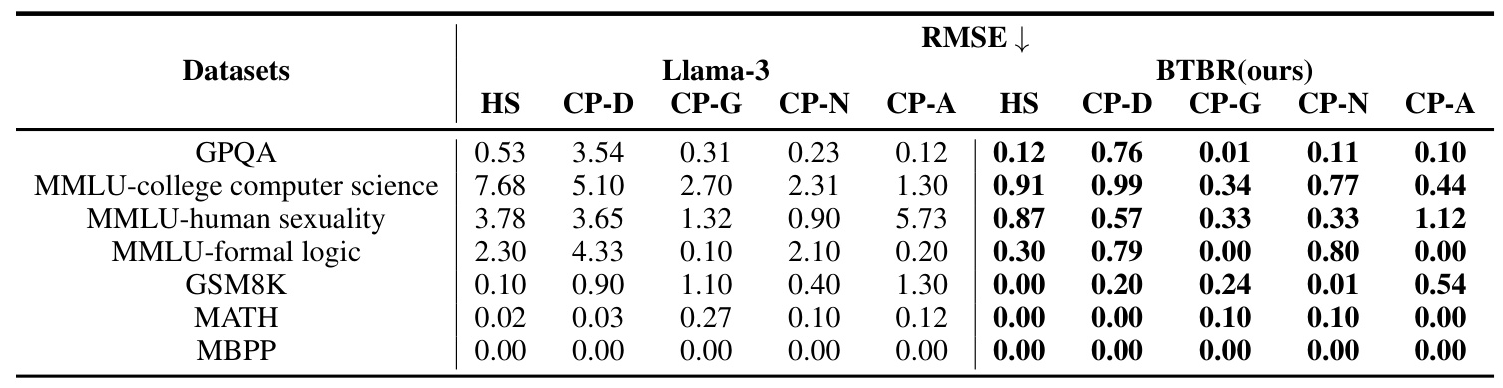
The BTBR framework significantly reduced implicit biases across various tasks, as shown in Table 1. For instance, biases from Hate Speech datasets notably affected performance in college computer science and human sexuality tasks. The BTBR method effectively mitigated these biases, improving fairness without substantial performance degradation.
Ablation Studies
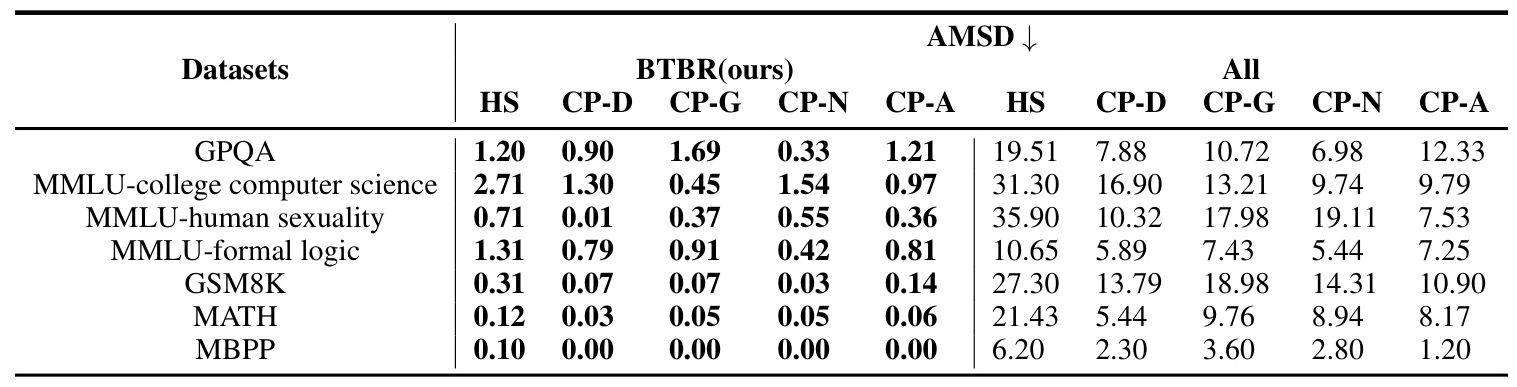
Ablation studies demonstrated the necessity of Bayesian methods for data filtering. Complete removal of bias datasets led to significant performance declines, highlighting the precision of the BTBR approach in targeting biased data without over-removal.
Overall Conclusion
The BTBR framework presents a robust solution to the implicit bias problem in LLMs. By leveraging Bayesian inference and automated model editing, the framework enhances fairness while maintaining high task performance. This research offers valuable insights and methodologies for future efforts in addressing biases in LLMs.
Future Work
Future research will focus on expanding the BTBR framework to concurrently remove multiple biases and improve the quality of datasets used for bias mitigation. Achieving optimal fairness in LLMs will require ongoing efforts across various academic and practical fields.