

Authors:
Yanbo Ding、Shaobin Zhuang、Kunchang Li、Zhengrong Yue、Yu Qiao、Yali Wang
Paper:
https://arxiv.org/abs/2408.10605
Introduction
In recent years, the field of text-to-image generation has seen significant advancements, with models like Stable Diffusion and DALL-E pushing the boundaries of what is possible. However, these models often struggle with generating images that contain multiple objects with complex spatial relationships in a 3D world. This limitation is particularly evident when precise control over 3D attributes such as object orientation, spatial relationships, and camera views is required. To address this challenge, the authors introduce MUSES, a novel AI system designed for 3D-controllable image generation from user queries. MUSES employs a multi-modal agent collaboration approach, mimicking the workflow of human professionals to achieve precise 3D control in image generation.
Related Work
Controllable Image Generation
Before the advent of diffusion models, GAN-based methods like ControlGAN and AttnGAN incorporated text features via attention modules to guide image generation. With the rise of diffusion models, the Stable Diffusion series quickly became dominant in the text-to-image generation market. However, text-based control alone proved insufficient for precise and fine-grained image generation. Models like ControlNet, GLIGEN, and T2I-Adapter introduced additional control conditions such as depth maps and sketches. Despite these advancements, existing methods still struggle to control 3D properties of objects. MUSES takes an innovative approach by planning 3D layouts and incorporating 3D models and simulations to achieve 3D-controllable image generation.
LLM-Based Agents
Large Language Models (LLMs) like ChatGPT and Llama have revolutionized natural language processing, while Multimodal LLMs (MLLMs) like LLaVA and InternVL have enabled impressive performance on visual tasks. The combination of LLMs and MLLMs in multi-agent systems has achieved remarkable success across various domains, including visual understanding, gaming, software development, video generation, and autonomous driving. Unlike previous works, MUSES uses LLMs to plan 3D layouts, bridging the gap between linguistic understanding and 3D spatial reasoning, particularly in complex 3D scenes.
Research Methodology
Overview of MUSES
MUSES is a generic AI system with a distinct multi-modal agent collaboration pipeline. It comprises three collaborative agents:
- Layout Manager: Responsible for 2D-to-3D layout lifting.
- Model Engineer: Handles 3D object acquisition and calibration.
- Image Artist: Manages 3D-to-2D image rendering.
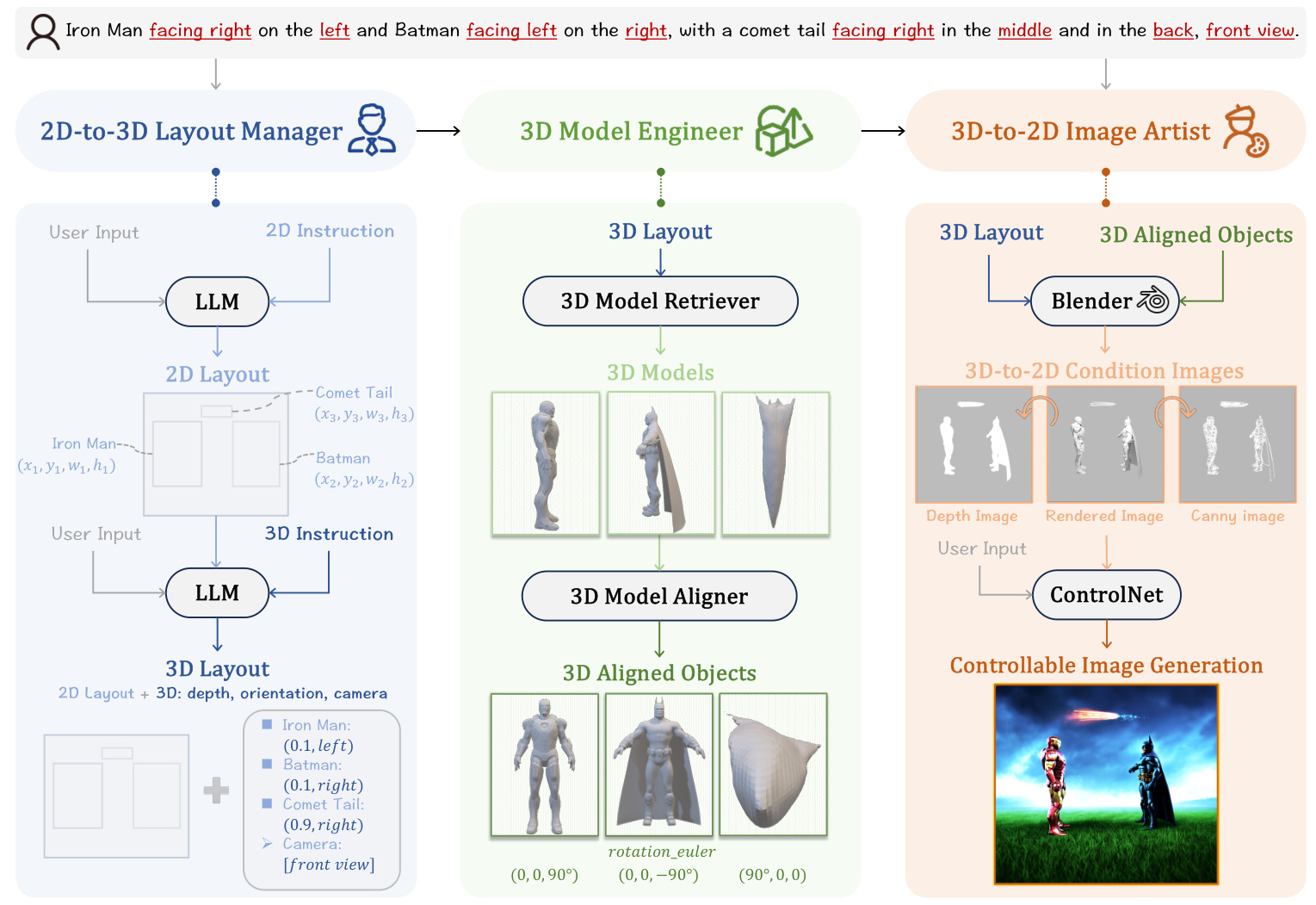
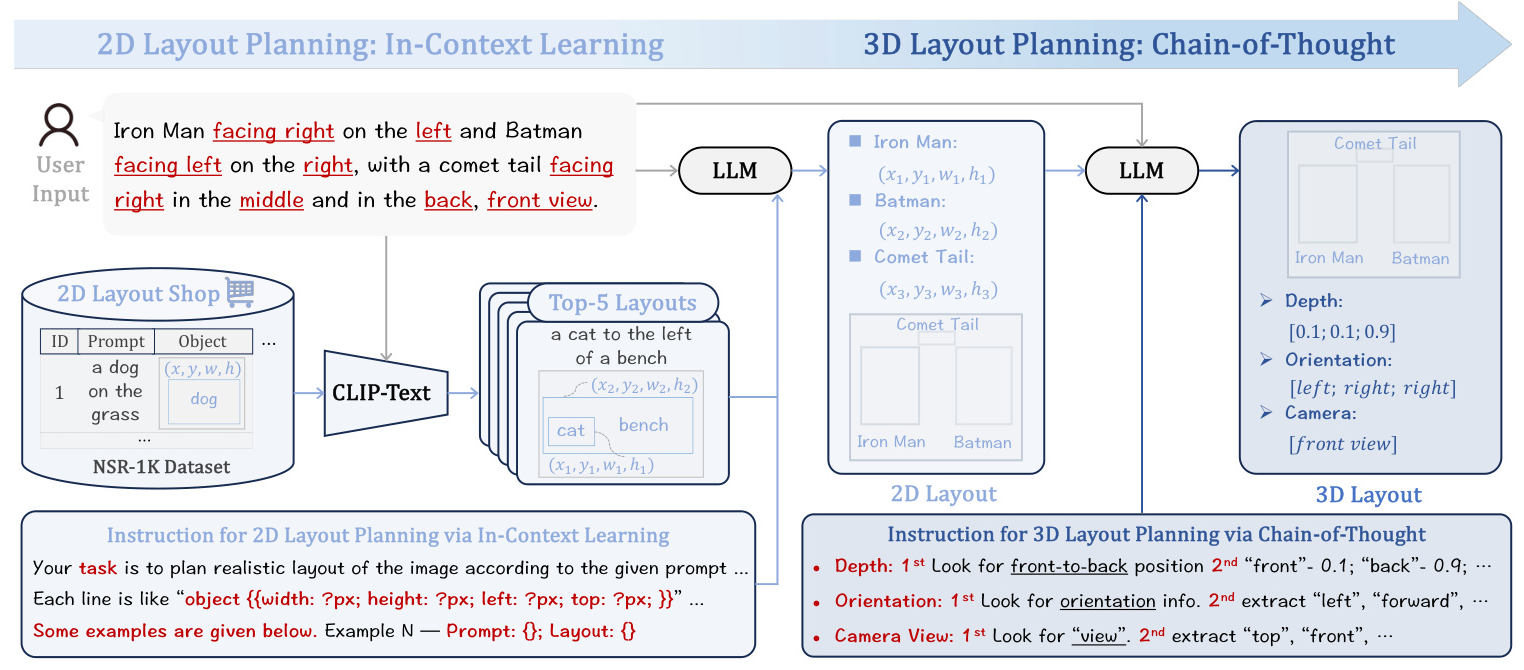
Layout Manager: 2D-to-3D Layout Lifting
The Layout Manager employs a Large Language Model (LLM) to plan 3D layouts based on user input. The process involves two main steps:
- 2D Layout Planning via In-Context Learning: The LLM generates a 2D layout through in-context learning, using examples from a 2D layout shop.
- 3D Layout Planning via Chain-of-Thought Reasoning: The LLM lifts the 2D layout to 3D space by determining object depth, orientation, and camera view through step-by-step reasoning.
Model Engineer: 3D Object Acquisition and Calibration
The Model Engineer consists of two key roles:
- Model Retriever: Acquires 3D models of objects using a decision tree approach that prioritizes retrieval from a self-collected 3D model shop, online search, and text-to-3D generation.
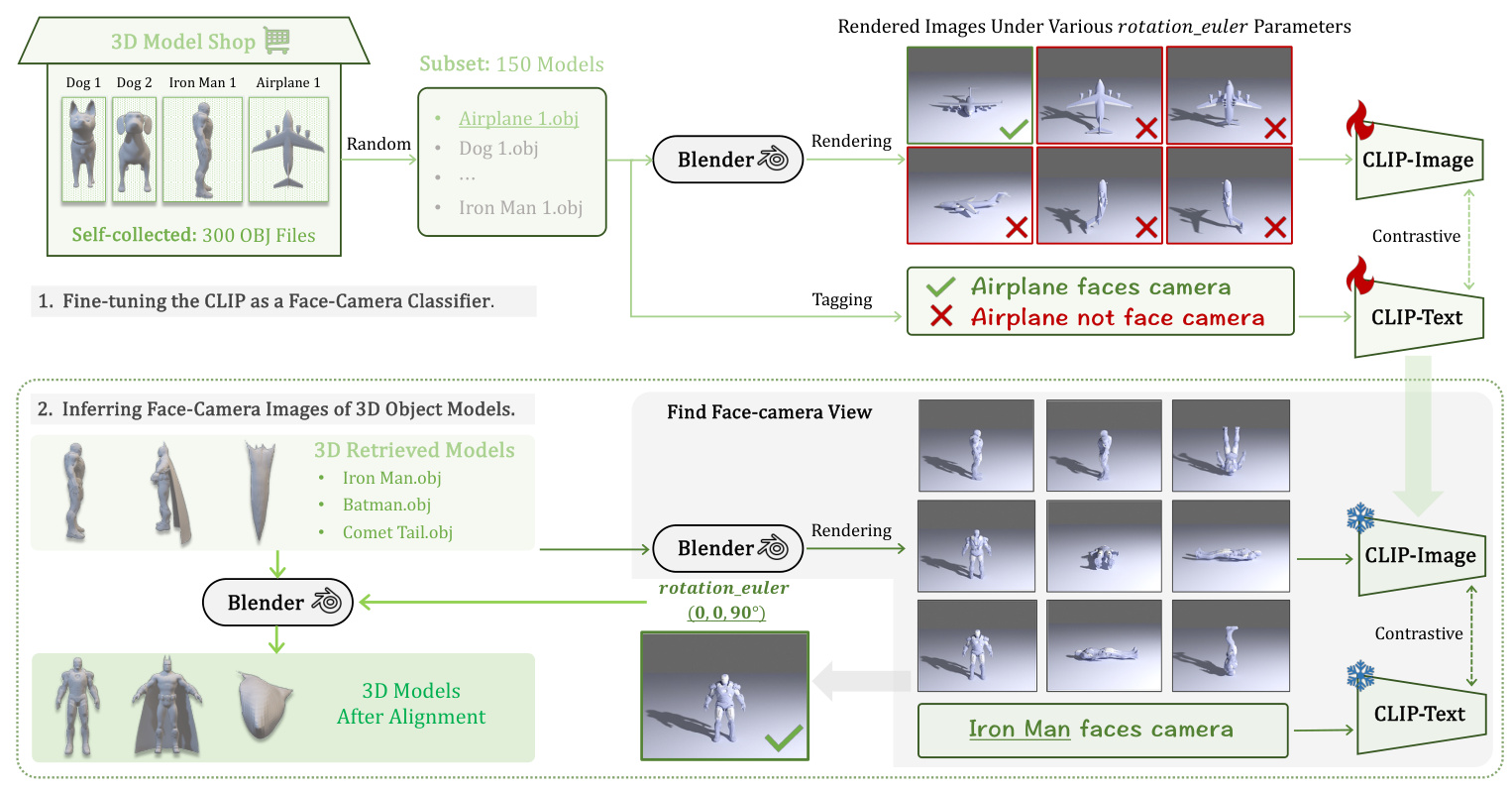
- Model Aligner: Calibrates the orientations of acquired 3D models to face the camera using a fine-tuned CLIP as a face-camera classifier.
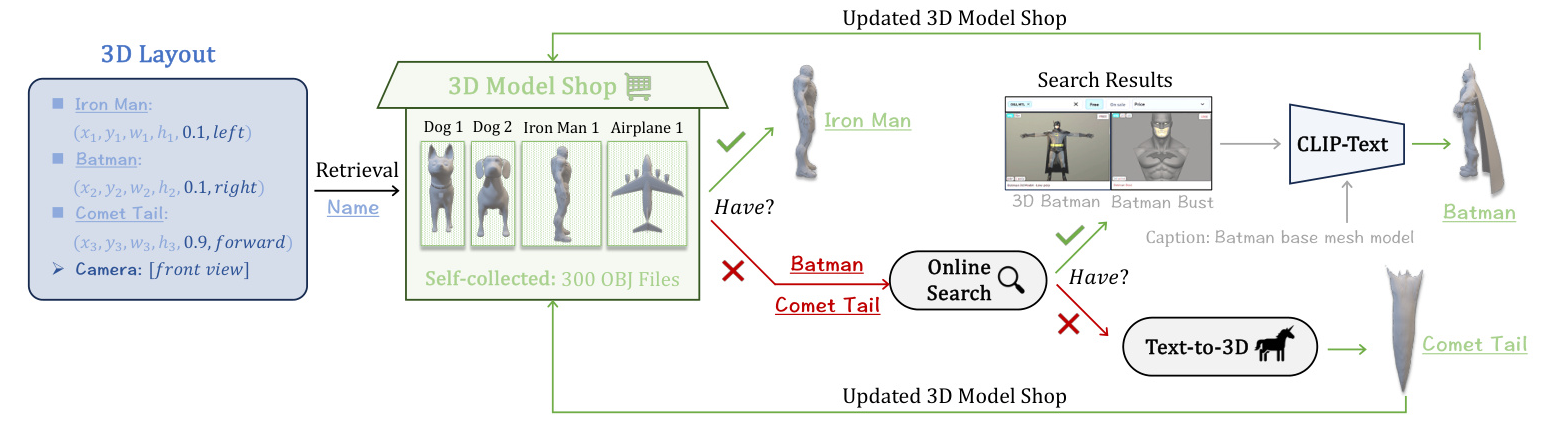
Image Artist: 3D-to-2D Image Rendering
The Image Artist assembles the 3D-aligned objects into a complete scene in Blender, generating high-quality 2D images. The process involves:
- 3D Scene Composition: Assembling 3D object models according to the 3D layout.
- Condition Image Generation: Creating depth maps and canny edge images for fine-grained control.
- Final Image Generation: Using ControlNet to generate the final image based on the 3D-to-2D condition images.
Experimental Design
Datasets and Metrics
The experiments were conducted on two datasets:
- T2I-CompBench: Evaluates object count and spatial relationships but lacks detailed text prompts for object orientations and camera views.
- T2I-3DisBench: A newly introduced dataset with 50 detailed texts encapsulating complex 3D information, including object orientations and camera views.
Both automatic and user evaluations were conducted on T2I-3DisBench. Visual Question Answering (VQA) on InternVL was used to rate the generated images on four key dimensions: object count, orientation, 3D spatial relationship, and camera view.
Implementation Details
MUSES is designed to be modular and extensible, allowing for the integration of various LLMs, CLIPs, and ControlNets. The experiments were conducted on an Ubuntu 20.04 system with 8 NVIDIA RTX 3090 GPUs. Specific settings for Llama-3-8B, ViT-L/14, ViT-B/32, and SD 3 ControlNet were used to ensure precise, consistent, and reliable outputs.
Results and Analysis
SOTA Comparison on T2I-CompBench
MUSES consistently outperforms both specialized/multi-agent approaches and generic models across all metrics, including object count, relationship, and attribute binding. The innovative 3D layout planning and 3D-to-2D image conditions enhance object relationship understanding, leading to the best performance on spatial-related metrics.
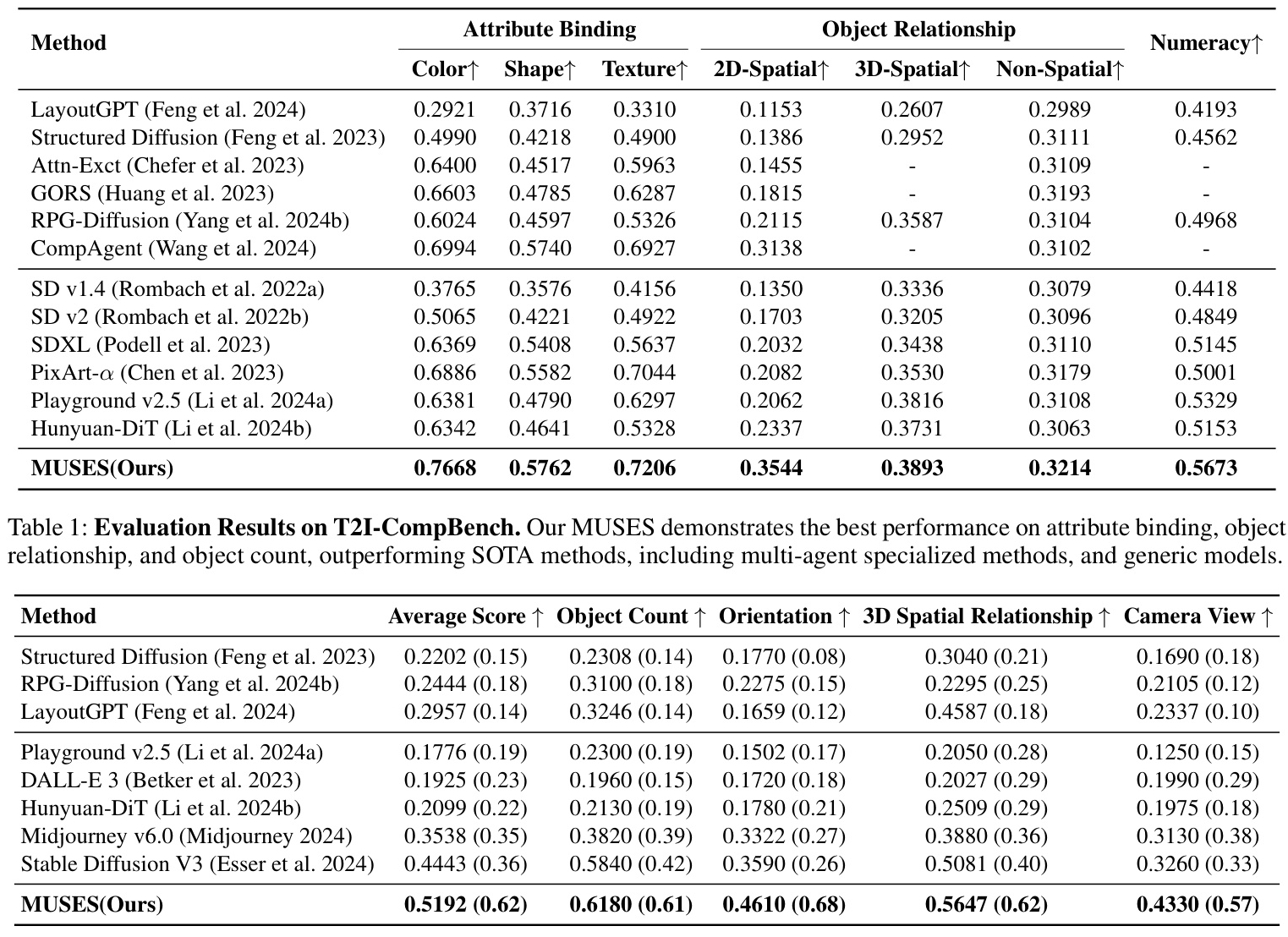
SOTA Comparison on T2I-3DisBench
MUSES also outperforms other methods on T2I-3DisBench, both in automatic and user evaluations. Existing approaches struggle with complex prompts containing 3D information, highlighting the importance of MUSES’ 3D-integration design. User evaluations show a strong preference for MUSES, demonstrating its effectiveness in handling complex 3D scenes.
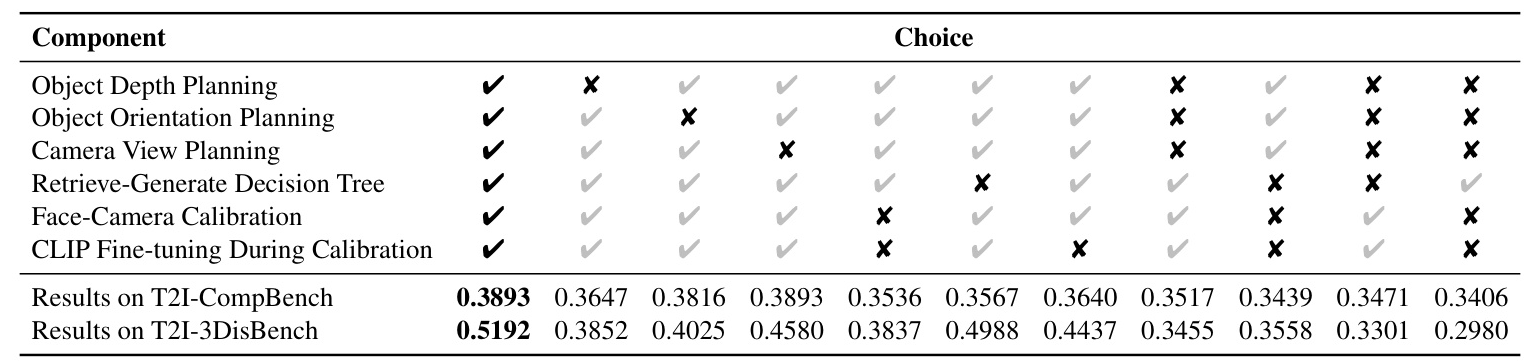
Ablation Studies
Ablation studies reveal that each component of MUSES is crucial for 3D-controllable image generation. Removing any component degrades the results, with the most significant impact observed when the Model Engineer is removed, resulting in poor object shaping and orientation.
Overall Conclusion
MUSES represents a significant advancement in 3D-controllable image generation, achieving fine-grained control over 3D object properties and camera views. The introduction of T2I-3DisBench provides a comprehensive benchmark for evaluating complex 3D image scenes. Future work will focus on improving efficiency, expanding capabilities to control lighting conditions, and potentially extending to video generation.
Acknowledgments
The authors acknowledge the contributions of teams at OpenAI, Meta AI, and InstantX for their open-source models, and CGTrader for supporting 3D model crawler free downloads. They also appreciate the valuable insights from researchers at the Shenzhen Institute of Advanced Technology and the Shanghai AI Laboratory.