

Authors:
Paper:
https://arxiv.org/abs/2408.10516
Introduction
Spoken Dialogue Systems (SDSs) have become a pivotal technology in artificial intelligence and speech processing, garnering significant attention from both academia and industry. Despite the advancements in large language models (LLMs), traditional SDSs remain a research focal point due to their superior control and interpretability. These systems are typically trained using data from human-to-human interactions, which exhibit varying speaking styles. This variability necessitates that human speakers adjust their dialogue strategies when engaging with different users, such as minors who often exhibit less clarity in their intentions and give ambiguous responses.
However, adapting SDSs to these distinctive speaking styles typically requires a wealth of annotated dialogue data, which can be challenging to obtain in abundance due to the minority status of users employing unique conversational strategies or behaviors. This study introduces a tailored data augmentation framework designed specifically for low-resource user groups exhibiting distinctive conversational behaviors. By leveraging a large language model (LLM) to extract speaker styles and a pre-trained language model (PLM) to simulate dialogue act history, this method generates enriched and personalized dialogue data, facilitating improved interactions with unique user demographics.
Related Work
The scarcity of annotated data and the challenge of data imbalance are persistent issues in various artificial intelligence domains. To address these effectively, data augmentation techniques have been employed across different tasks. For instance, Schick and Schütze (2021) generated text similarity datasets from scratch by instructing a large PLM. Similarly, Liu et al. (2022) and Chen and Yang (2021) enhanced data by manipulating individual utterances within dialogues while preserving the original meaning, which improved model performance in dialogue summarization tasks.
While these methods focus on generating individual sentences, our study aims to create coherent dialogues comprising multiple sentences tailored for specific target groups. Mohapatra et al. (2021) utilized GPT-2 to develop user and agent bots, generating comprehensive task-oriented dialogues through bot interactions, demonstrating notable enhancements in low-resource scenarios. Recently, researchers have started using LLMs for data augmentation, generating domain-specific, task-oriented dialogues by extracting dialogue paths from out-of-domain conversations. However, our approach generates tailored dialogue act histories based on existing data, specifically optimized for target user groups.
Research Methodology
The Proposed Framework
The proposed data augmentation framework aims to enhance the dialogue act (DA) prediction performance of the system when dealing with low-resource user groups that exhibit unique dialogue strategies. The framework comprises three main components:
- Speaker Style Extraction: Employing ChatGPT to extract the speaking styles of target users and speakers interacting with them.
- Dialogue Act History Generation: Fine-tuning a pre-trained model to generate the system’s DA history for the previous turns.
- Dialogue Generation: Using the extracted speaking styles and generated DA histories to create training dialogue data with ChatGPT.
The task involves predicting the current turn’s DA based on the dialogue history and the system’s DA history. By capturing the speaking style of dialogue participants and generating dialogue flows that mimic real human interactions with the target user group, the model can effectively understand and adapt to unique dialogue strategies.
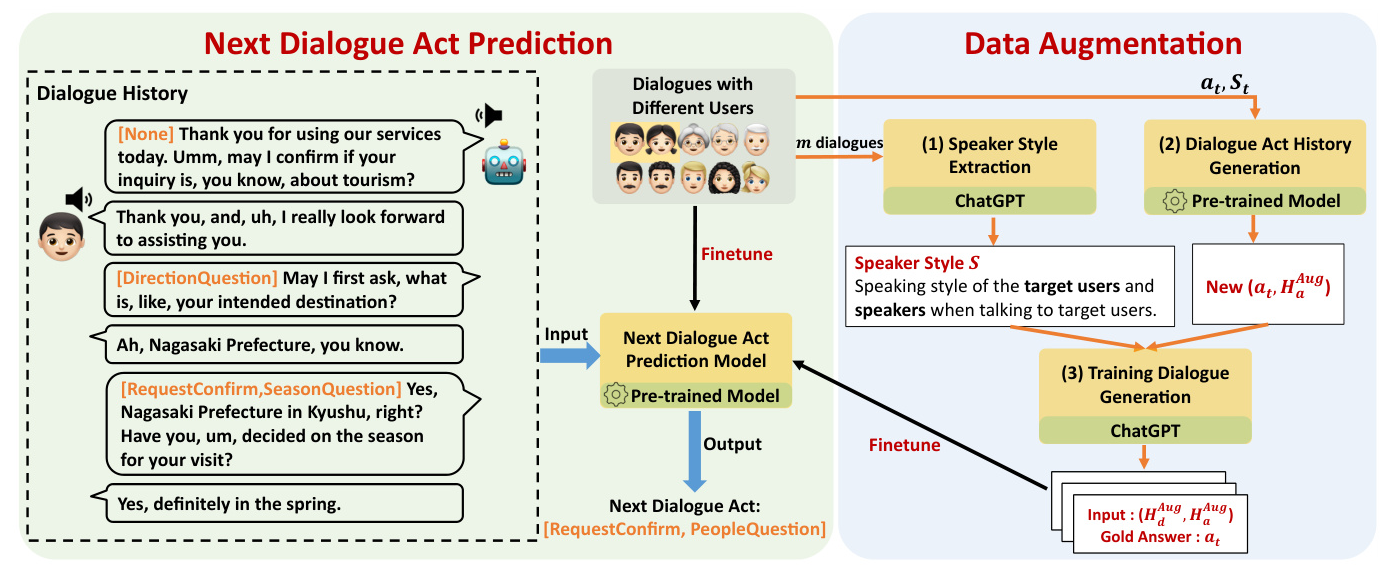
Speaker Styles Extraction
Capturing the unique speaking styles employed by the target user group is crucial as it significantly influences the content of conversations. This is achieved by comparing dialogues from the target user group with those from non-target groups. ChatGPT is utilized to extract speaker styles from conversations involving target users, focusing on abstract styles that significantly influence the direction of the dialogue.
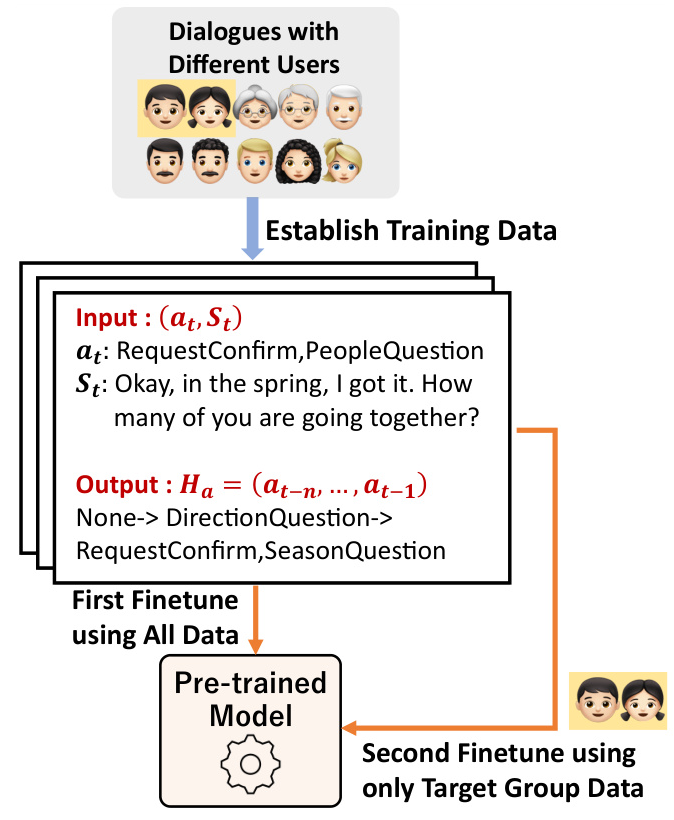
DA History Generation
The unique conversational strategies employed by the target group also significantly influence the DAs of those engaging with them. The objective is to generate a diverse and realistic DA history that is specifically optimized for groups with distinctive speaking strategies. This involves fine-tuning a PLM using existing data to generate the system’s DA history for the previous turns, ensuring that the generated DA histories closely mimic real human dialogues and align with the unique speaking strategies of the target users.
Dialogue Generation
Having obtained speaker styles and DA history tailored to users employing unique dialogue strategies, the ultimate goal is to generate dialogues corresponding to these styles and histories to enrich the training data for DA prediction. ChatGPT’s powerful generation capabilities are leveraged to create dialogue data for training purposes, enhancing the model’s ability to predict DAs when interacting with target users who exhibit unique conversational strategies.
Experimental Design
Dataset
The study utilized the “Travel Agency Task Dialogue Corpus,” a multimodal dialogue Japanese dataset featuring conversations from users of various age groups, with detailed annotations of DAs. The dataset contains 115 hours of dialogue, spanning 330 conversations, with each averaging about 20 minutes. The dialogues revolve around recommending travel destinations to users across various age groups.
Low-Resource Setting
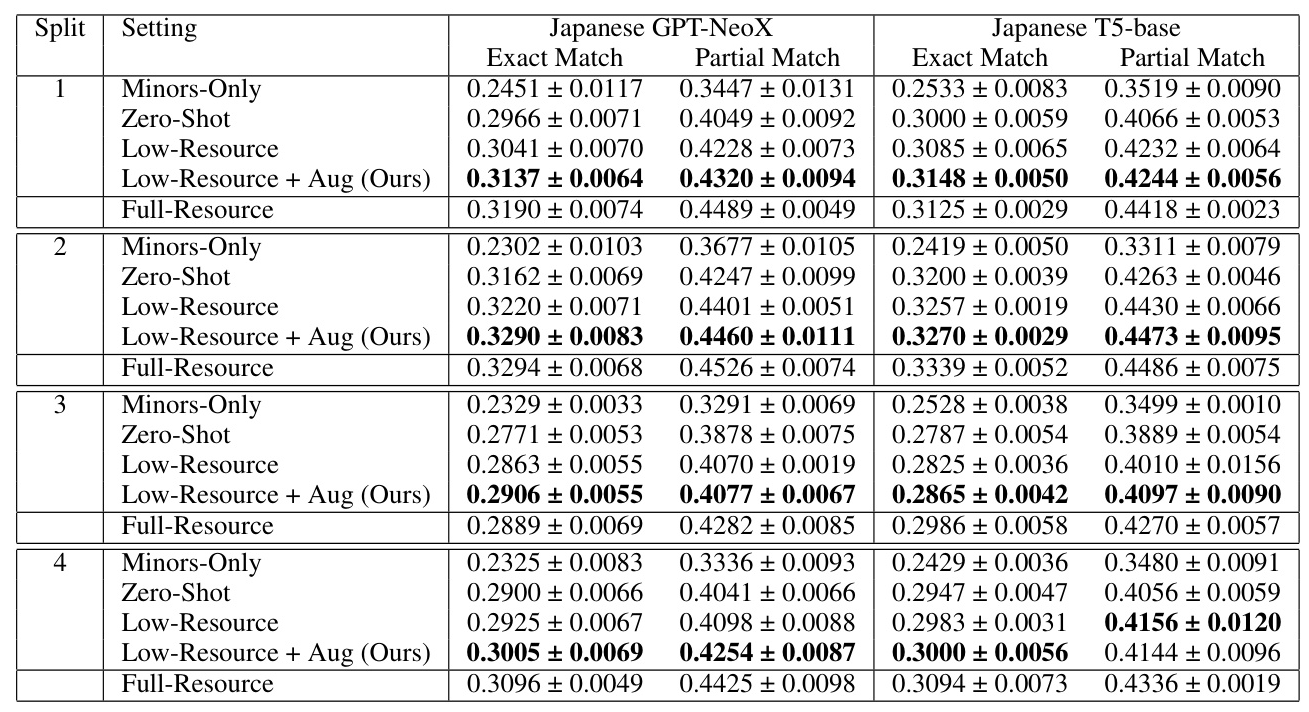
To simulate low-resource conditions for specific user demographics, dialogue data from only 3 minors out of a group of 20 were used for training. For evaluation, dialogues from 10 minors were used. Five DA prediction models were trained using datasets of varying scales:
- Minors-Only: Employed only dialogues from minors.
- Zero-Shot: Utilized all data from adults and seniors.
- Low-Resource: Combined dialogues from minors with those from adults and seniors.
- Full-Resource: Included dialogues from minors plus all dialogues from adults and seniors.
- Low-Resource + Augmentation (Ours): Used the Low-Resource dataset supplemented with augmented data generated using the proposed framework.
Setup and Details
In the process of extracting speaker styles, dialogues were fed into GPT-4-0125-preview. For generating training dialogues, GPT-3.5-turbo-0125 was employed. During the DA history generation phase, Japanese T5-Large was used as the PLM, with two rounds of fine-tuning to ensure the model generates DA histories that closely mimic real human conversations and align with the unique conversational strategies of minors.

Results and Analysis
Performance Evaluation
The performance of the proposed data augmentation framework was evaluated using exact match and partial match rates as evaluation metrics. The results showed that the proposed framework, Low-Resource + Aug (Ours), almost always surpassed the Low-Resource model in terms of mean exact and partial match rates. This demonstrates that even in a low-resource setting, the method successfully captures the characteristics of minor speakers and generates dialogue flows that align with minor speaking behaviors.
Ablation Study
Ablation experiments were conducted to evaluate the individual effectiveness of components in the proposed framework. The findings indicated that both the independent use of style extraction and DA history generation components significantly improved performance. The combination of speaker styles extraction and DA history generation was found to be most effective, underscoring the necessity of targeted age-specific second fine-tuning when training the DA history generation model.

Effectiveness of Speaker Style and DA History Generation
The effectiveness of the speaker style was demonstrated by generating dialogues that more closely match the speaking styles of minors. The DA history generation was shown to produce more DA histories closely aligned with the target group, enhancing performance.
Overall Conclusion
The study introduced a data augmentation method designed to enhance the performance of the DA prediction model for users with limited data and unique conversational styles. The experiments confirmed the reliability of the proposed method and the effectiveness of its components. While the study did not exhaustively explore the full potential for improvement of the proposed method, further evaluation is planned for future work.
The proposed framework demonstrates significant potential in enhancing the adaptability and inclusivity of spoken dialogue systems, particularly for low-resource user groups with unique conversational behaviors.